前言
声明,本文用得是jdk1.8
前面已经讲了Collection的总览和剖析List集合以及散列表、Map集合、红黑树的基础了:
本篇主要讲解HashMap,以及涉及到一些与hashtable的比较~
看这篇文章之前最好是有点数据结构的基础:
当然了,如果讲得有错的地方还请大家多多包涵并不吝在评论去指正~
一、HashMap剖析
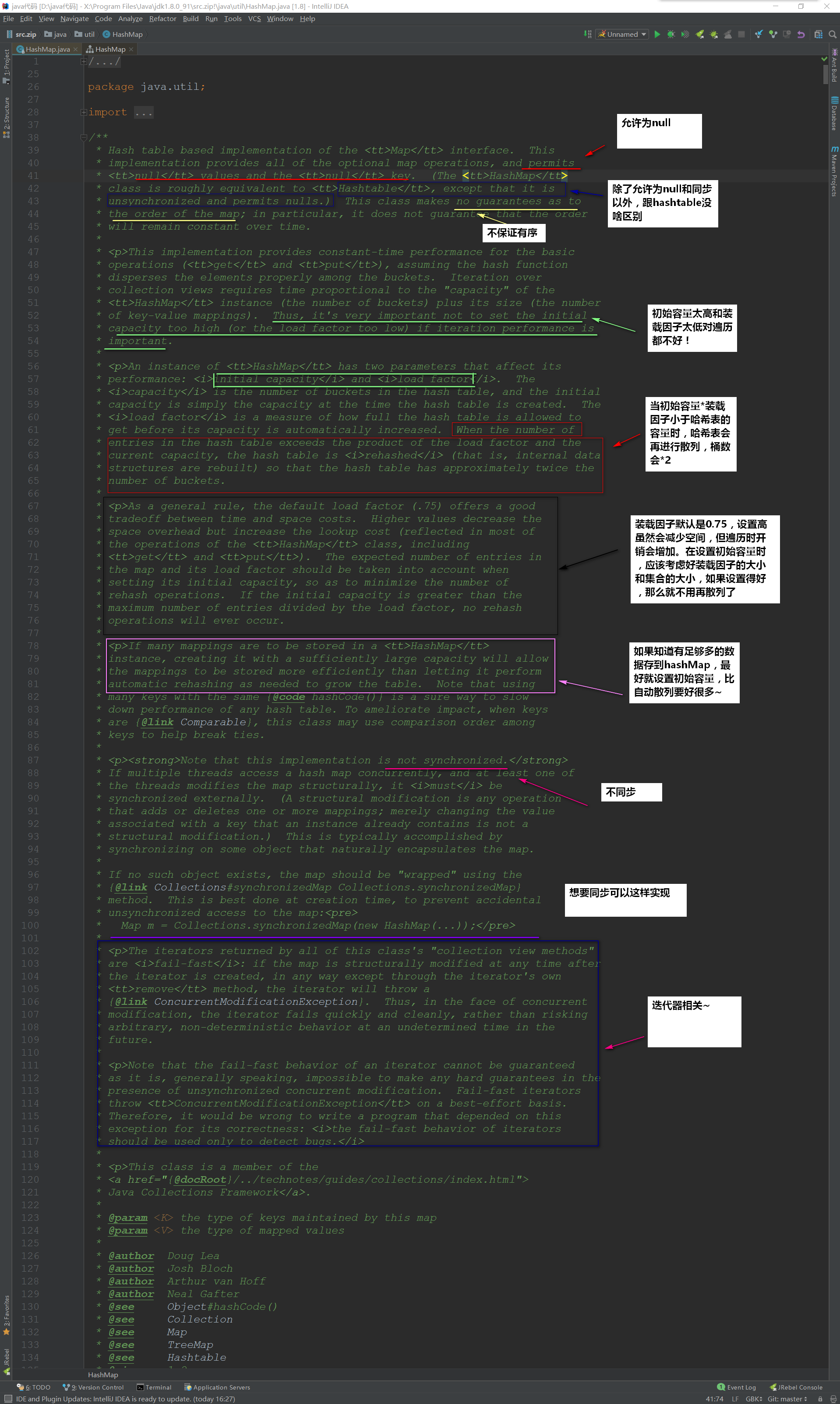
首先看看HashMap的顶部注释说了些什么:
![img_f716d7adc593e8a27f6d0d972fda85eb.png]()
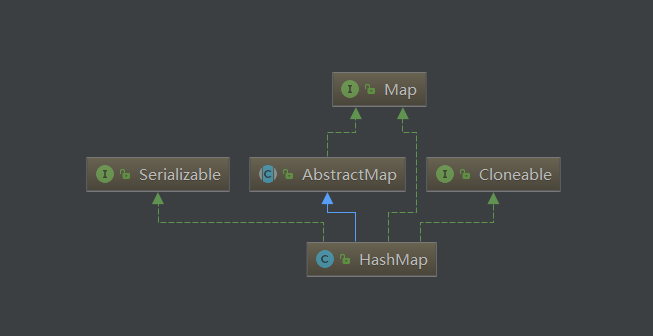
再来看看HashMap的类继承图:
![img_93f5fc9fba1406ce215fedc385c304fd.png]()
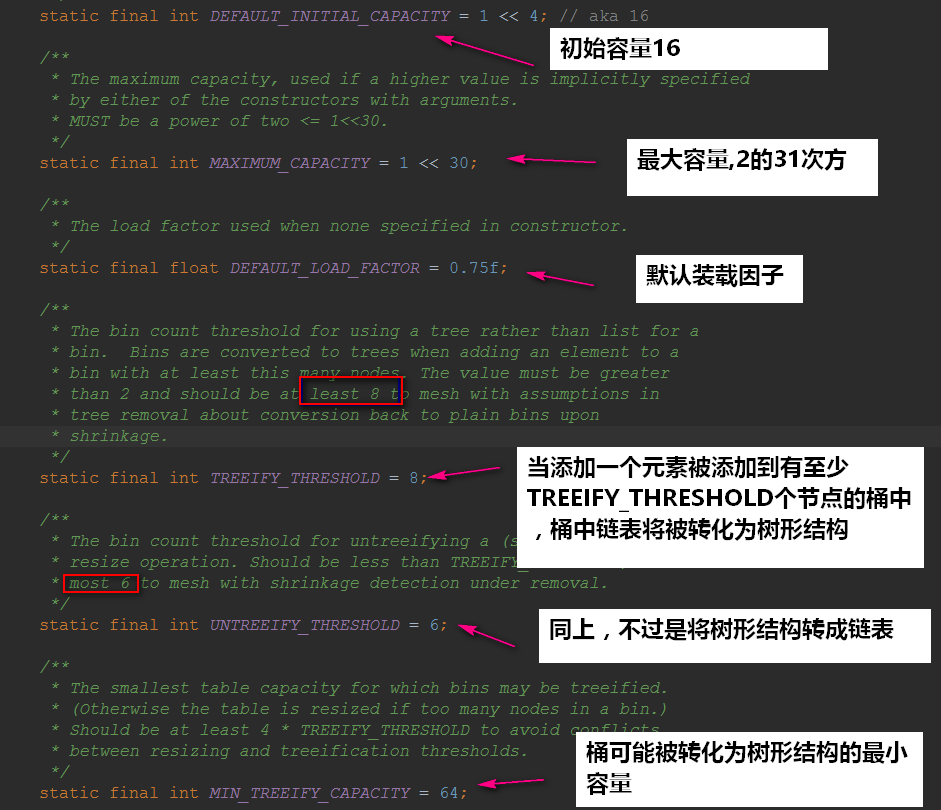
下面我们来看一下HashMap的属性:
![img_62b48e94425bc2491e8a1124abe4f8d9.png]()
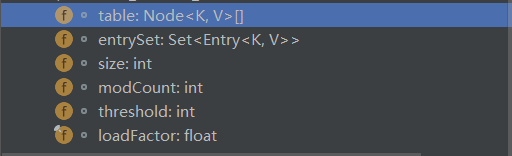
成员属性有这么几个:
![img_9e4771a2fe5d8a7995eb422274564aca.png]()
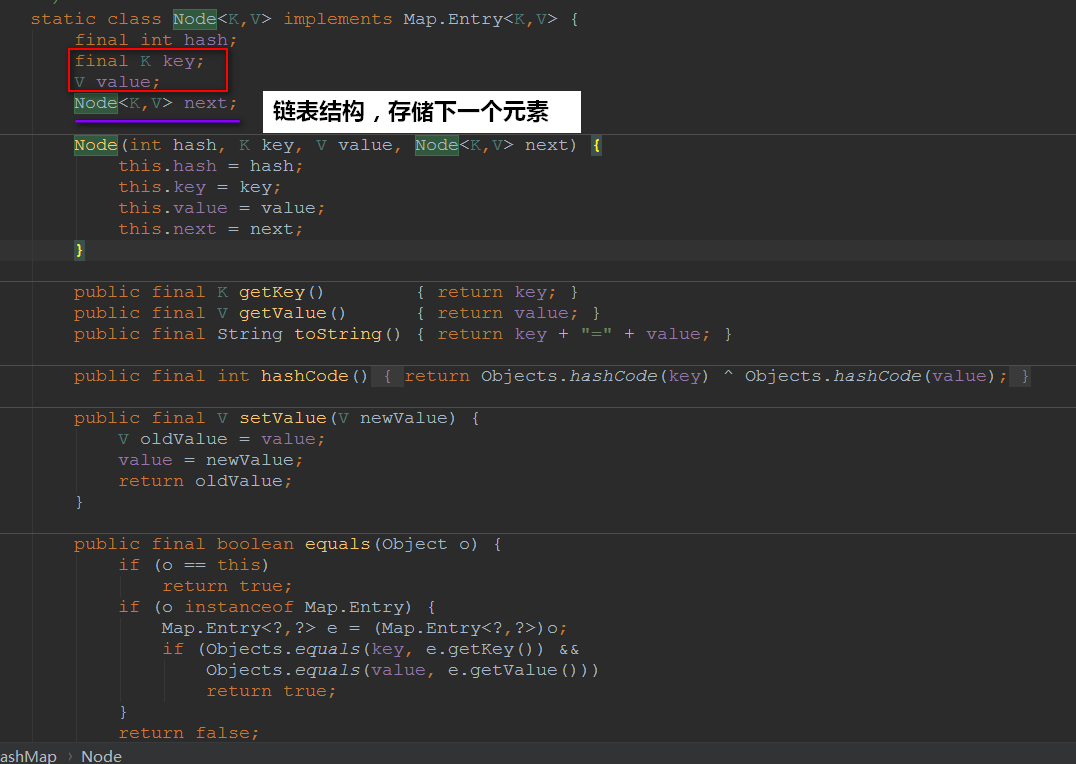
再来看一下hashMap的一个内部类Node:
![img_c549e3c67cee948632e275262c687915.png]()
我们知道Hash的底层是散列表,而在Java中散列表的实现是通过数组+链表的~
再来简单看看put方法就可以印证我们的说法了:数组+链表-->散列表
![img_81277a59a2734d7621ca2f39d964f589.png]()
我们可以简单总结出HashMap:
- 无序,允许为null,非同步
- 底层由散列表(哈希表)实现
- 初始容量和装载因子对HashMap影响挺大的,设置小了不好,设置大了也不好
1.1HashMap构造方法
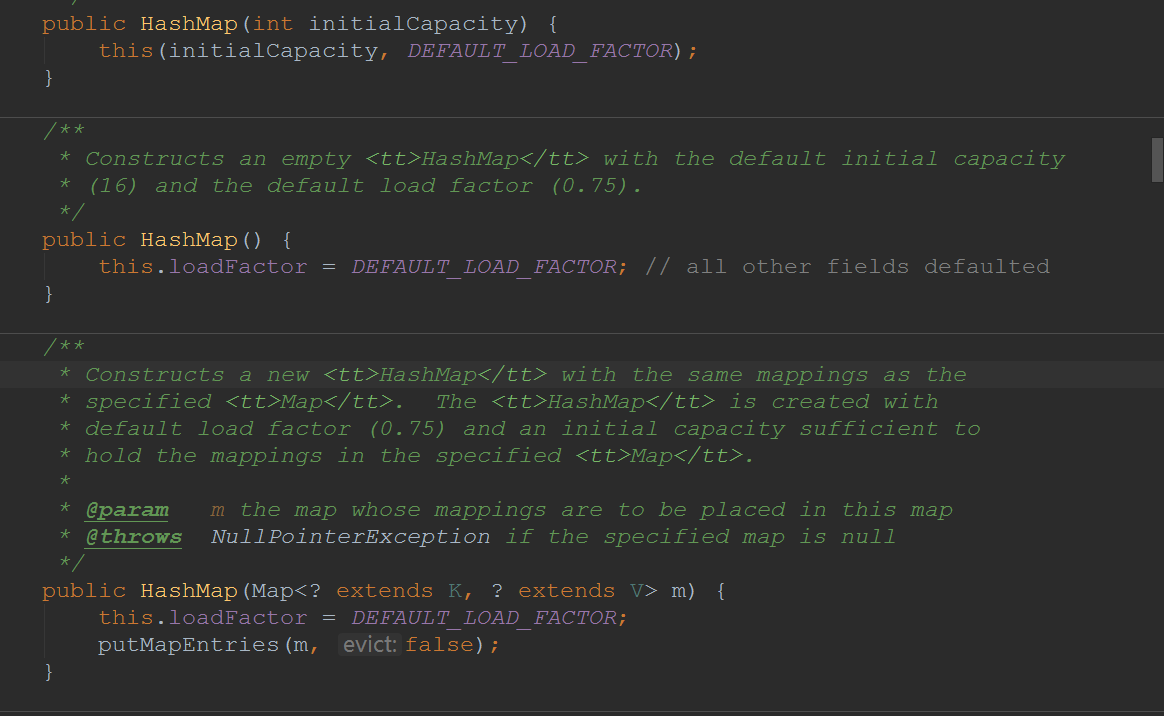
HashMap的构造方法有4个:
![img_d9af2ecd94fb0216226e5f871a38a49f.png]()
![img_57d61f3affb4dfaa4f9bc667ab6924f8.png]()
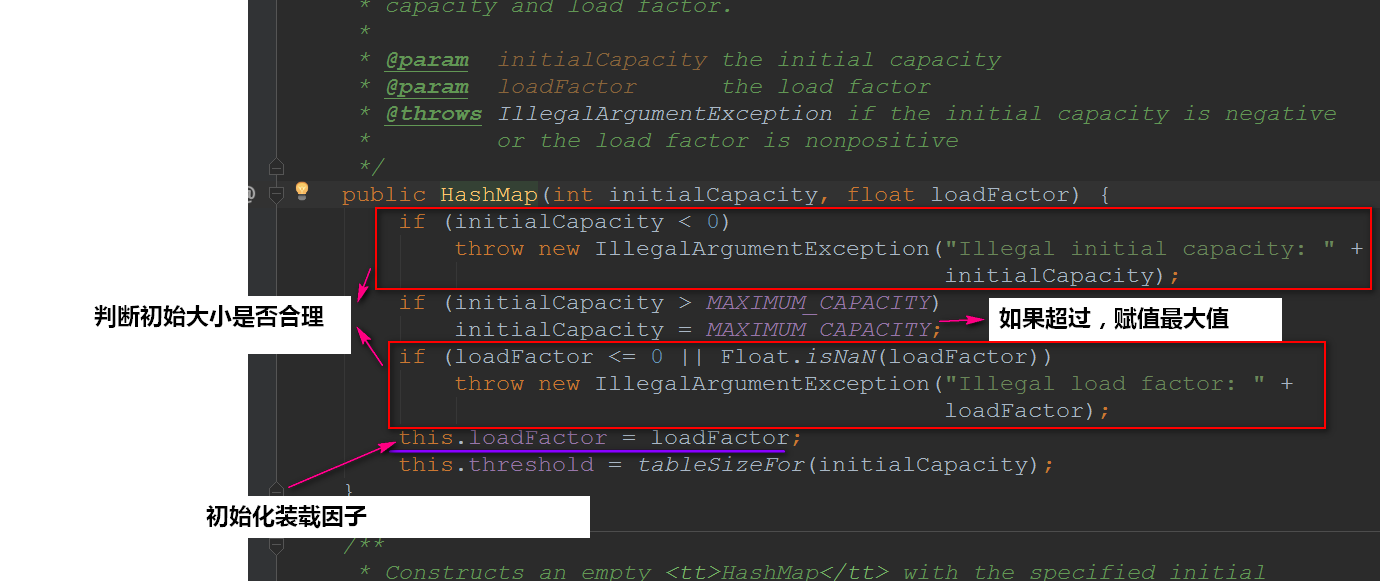
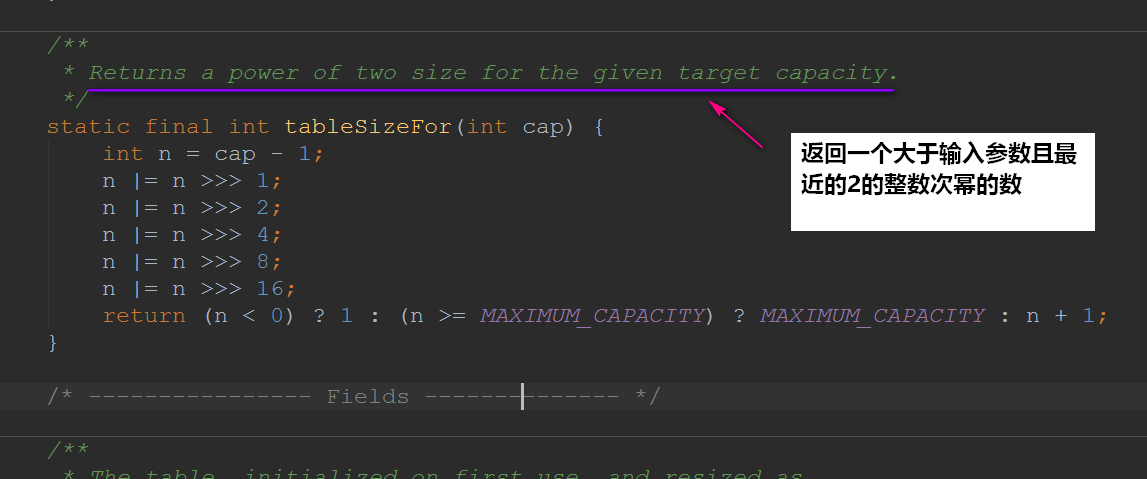
在上面的构造方法最后一行,我们会发现调用了tableSizeFor(),我们进去看看:
![img_994c73b061a28dc7503054556bc84c21.png]()
这是位运算算法,具体流程可参考:
看完上面可能会感到奇怪的是:为啥是将2的整数幂的数赋给threshold?
- threshold这个成员变量是阈值,决定了是否要将散列表再散列。它的值应该是:
capacity * load factor才对的。
其实这里仅仅是一个初始化,当创建哈希表的时候,它会重新赋值的:
![img_27f48b8a6398b76f72911047d3a8daa4.png]()
至于别的构造方法都差不多,这里我就不细讲了:
![img_322867991b0c95f5731eeb25d6aa08f5.png]()
1.2put方法
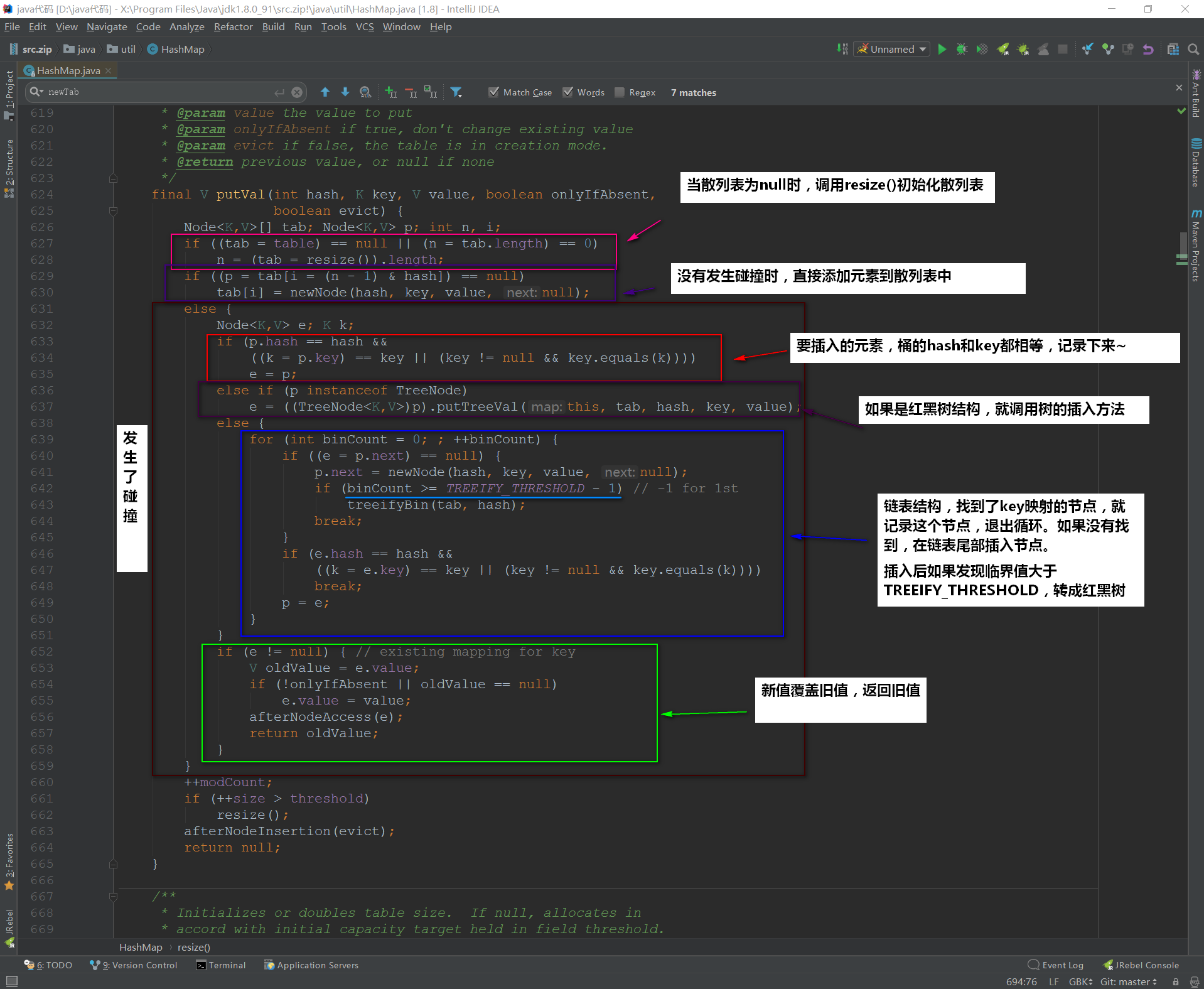
put方法可以说是HashMap的核心,我们来看看:
![img_6eeffb41b402ec89021c1349a5a2457b.png]()
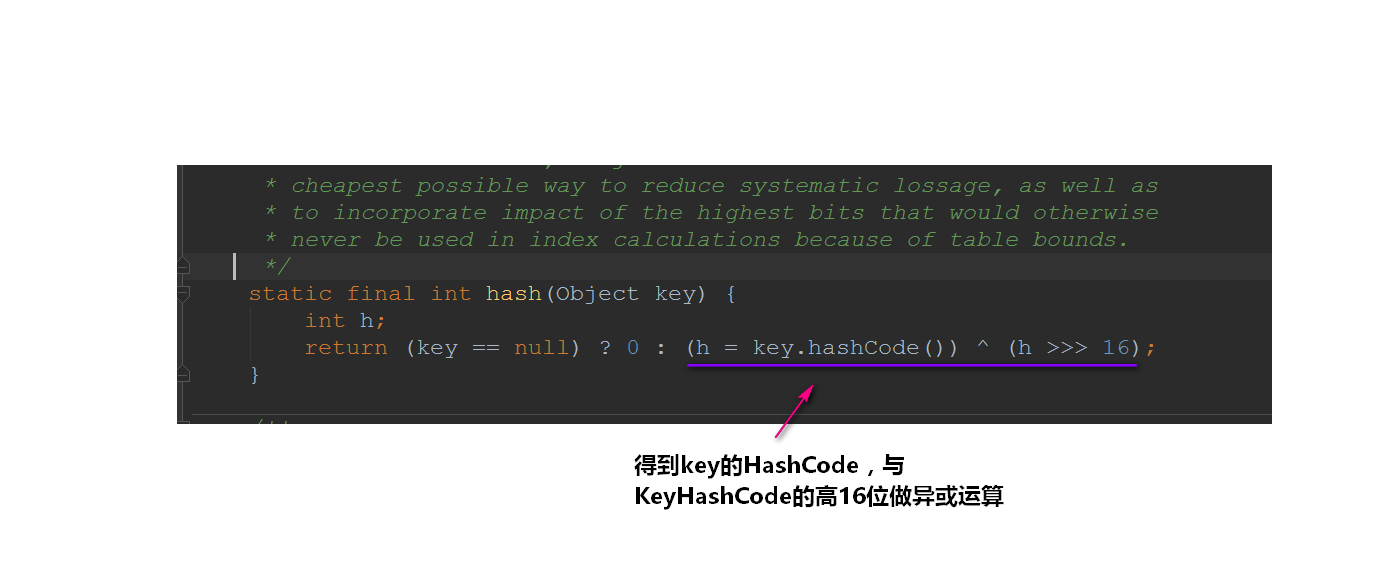
我们来看看它是怎么计算哈希值的:
![img_ceec62462366b722b4f6b241125238cd.png]()
为什么要这样干呢??我们一般来说直接将key作为哈希值不就好了吗,做异或运算是干嘛用的??
我们看下来:
![img_01714dec6def4cc894d7955c6437045d.png]()
我们是根据key的哈希值来保存在散列表中的,我们表默认的初始容量是16,要放到散列表中,就是0-15的位置上。也就是tab[i = (n - 1) & hash]。可以发现的是:在做&运算的时候,仅仅是后4位有效~那如果我们key的哈希值高位变化很大,低位变化很小。直接拿过去做&运算,这就会导致计算出来的Hash值相同的很多。
而设计者将key的哈希值的高位也做了运算(与高16位做异或运算,使得在做&运算时,此时的低位实际上是高位与低位的结合),这就增加了随机性,减少了碰撞冲突的可能性!
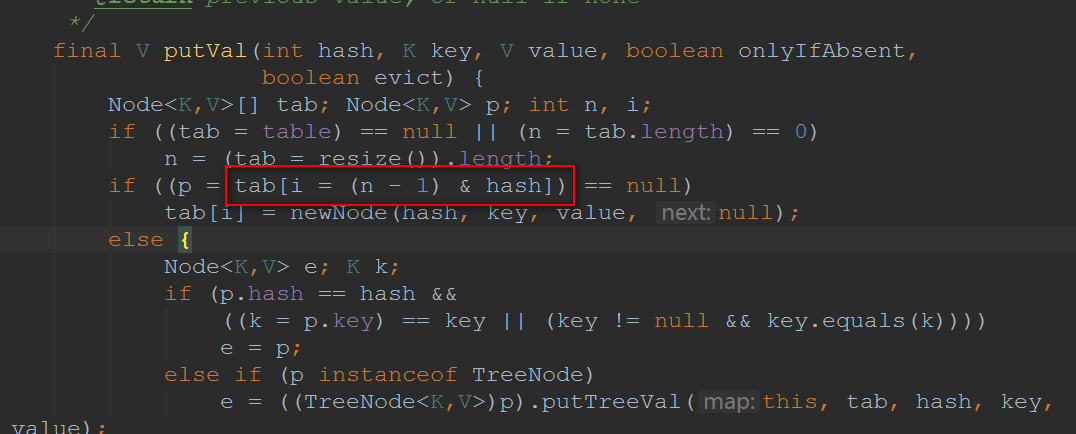
下面我们再来看看流程是怎么样的:
![img_d5308d941e692f4f78fe123984a0084b.png]()
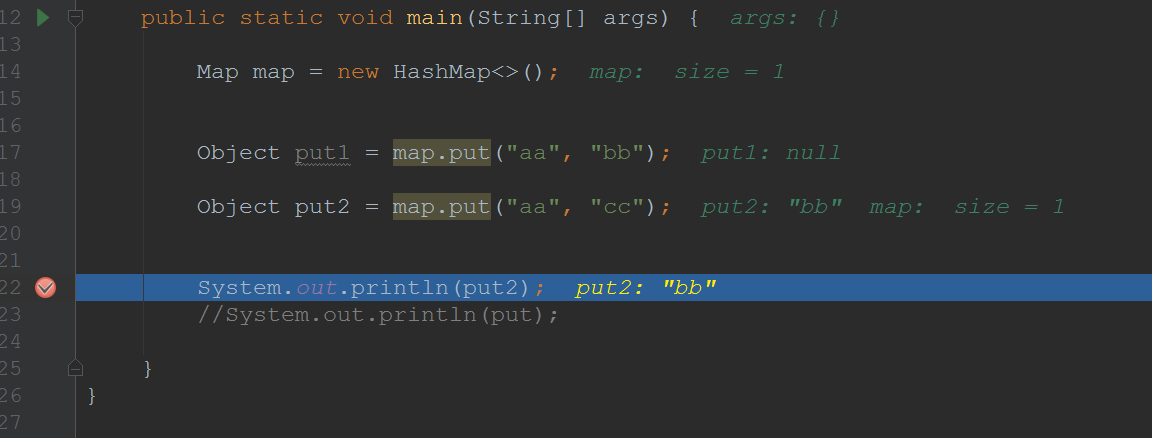
新值覆盖旧值,返回旧值测试:
![img_829164b58d79fb42ff2762120a18d590.png]()
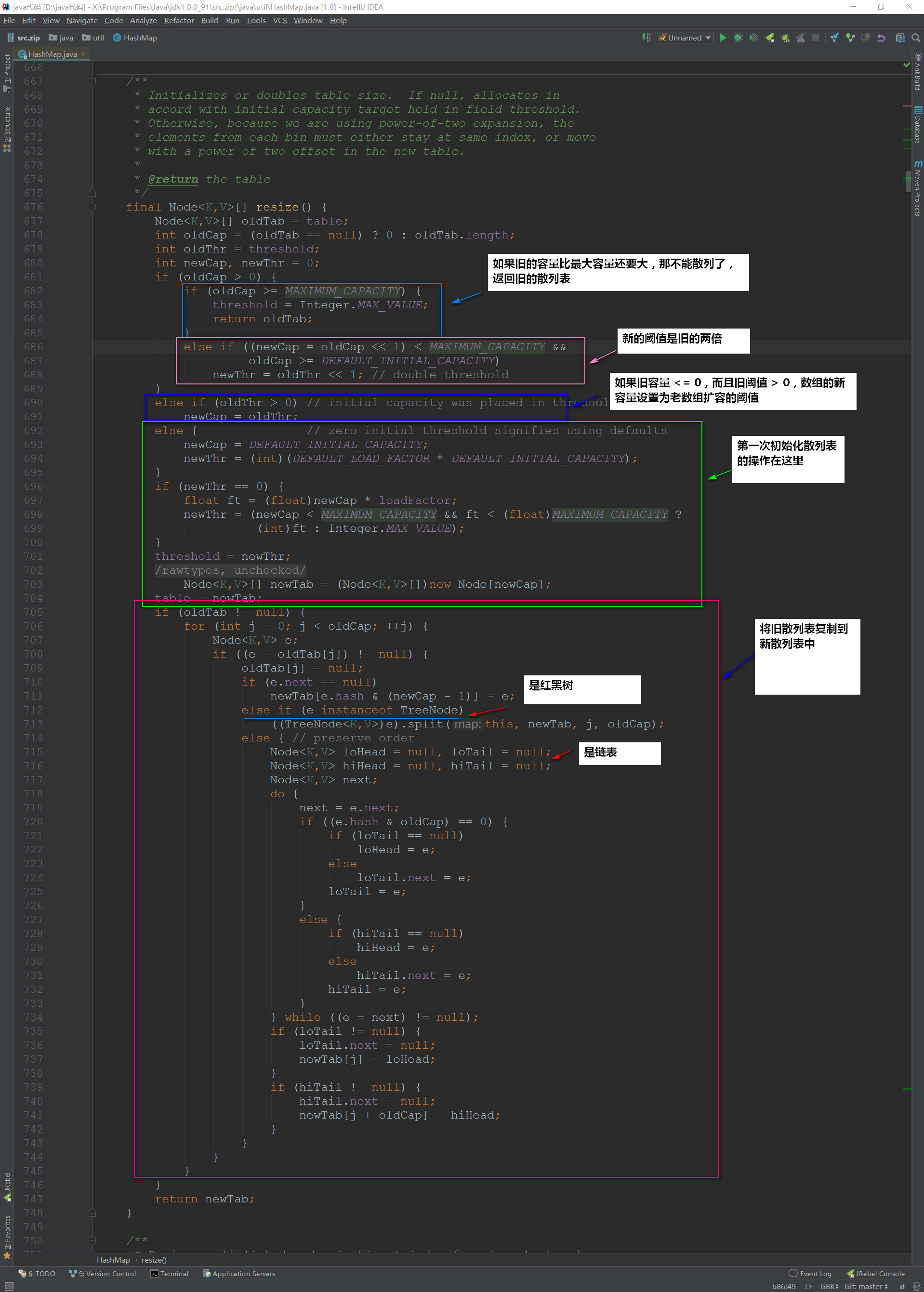
接下来我们看看resize()方法,在初始化的时候要调用这个方法,当散列表元素大于capacity * load factor的时候也是调用resize()
![img_c1c65a321c432db3d0e6d19d2f714054.png]()
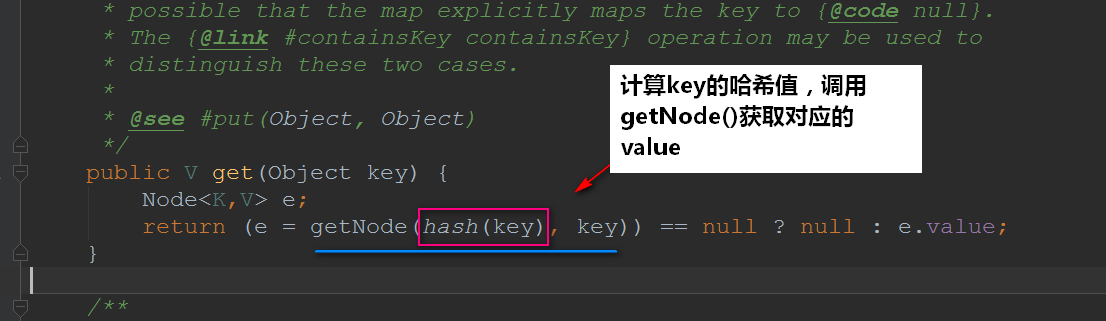
1.3get方法
![img_519d0a2472b3d77b1e354a8c6544727d.png]()
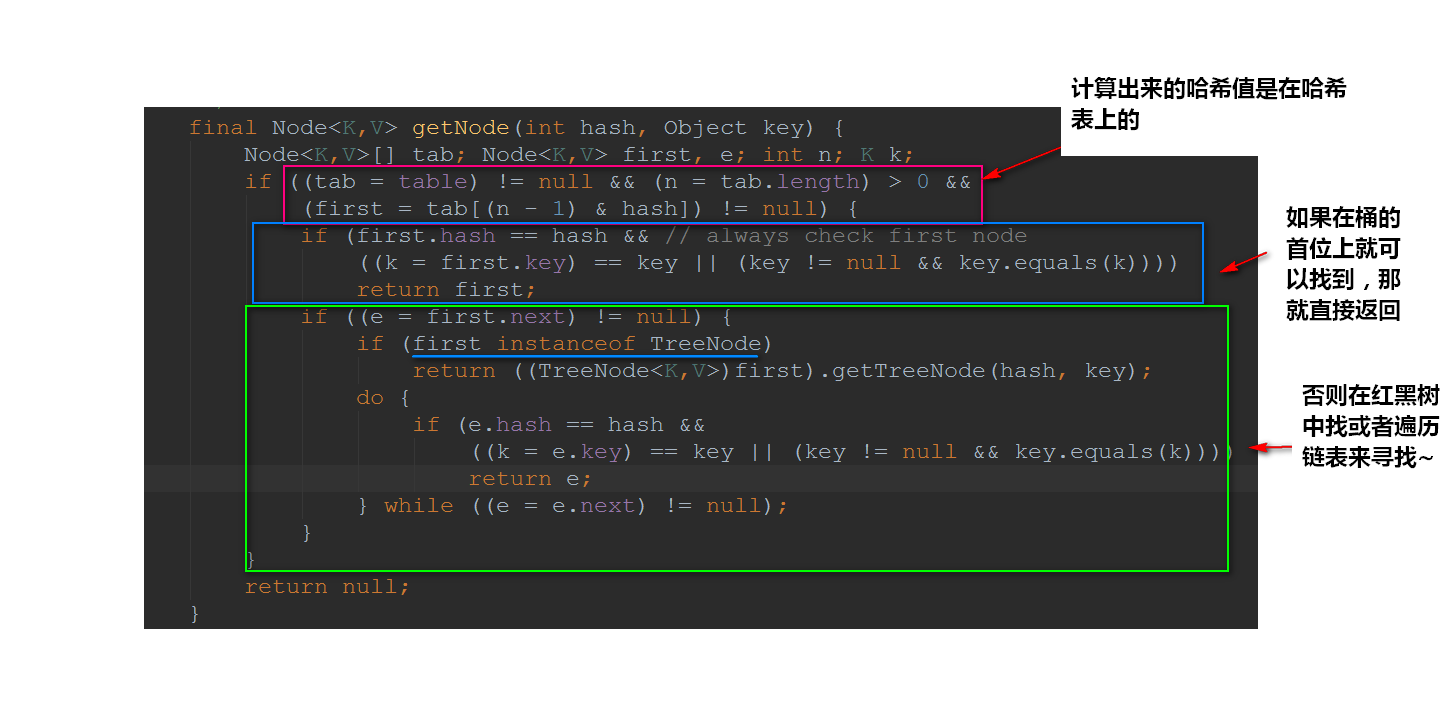
接下来我们看看getNode()是怎么实现的:
![img_7419d764d1d550072542e2dbc7127699.png]()
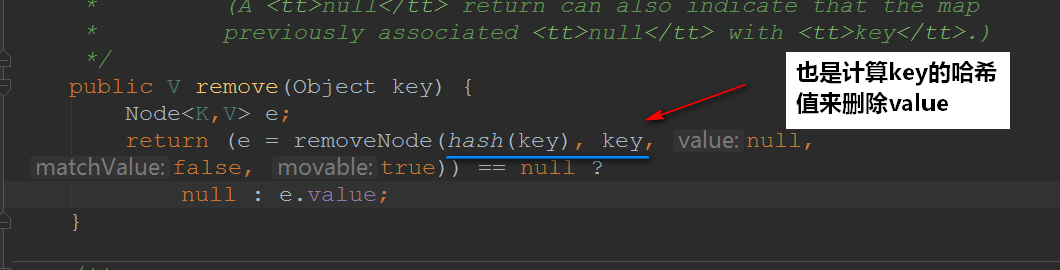
1.4remove方法
![img_fe3cf2f060422e4bef7f3f52d234aa30.png]()
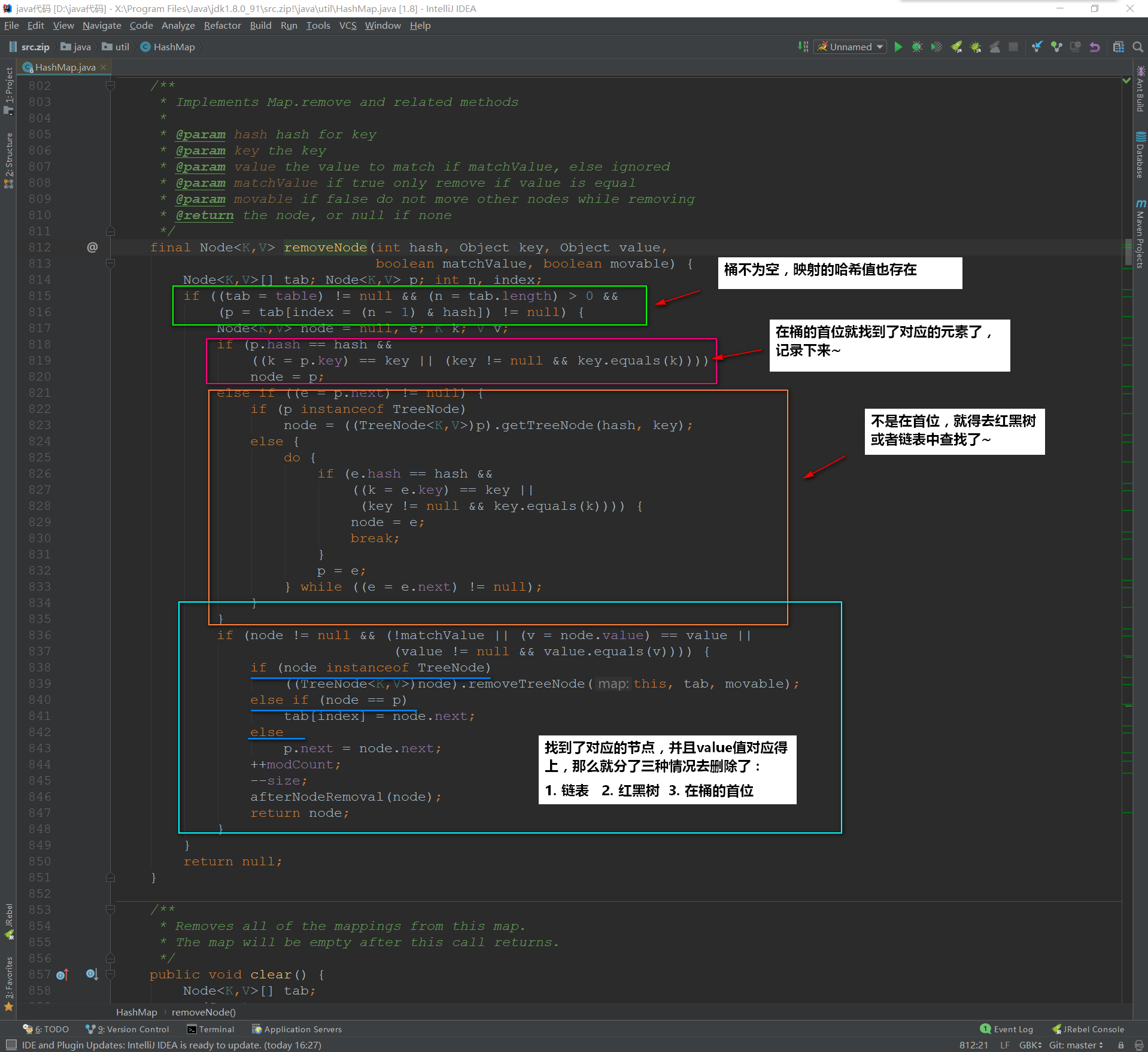
再来看看removeNode()的实现:
![img_757ae4ab956c6cc75ac51cf8376eda11.png]()
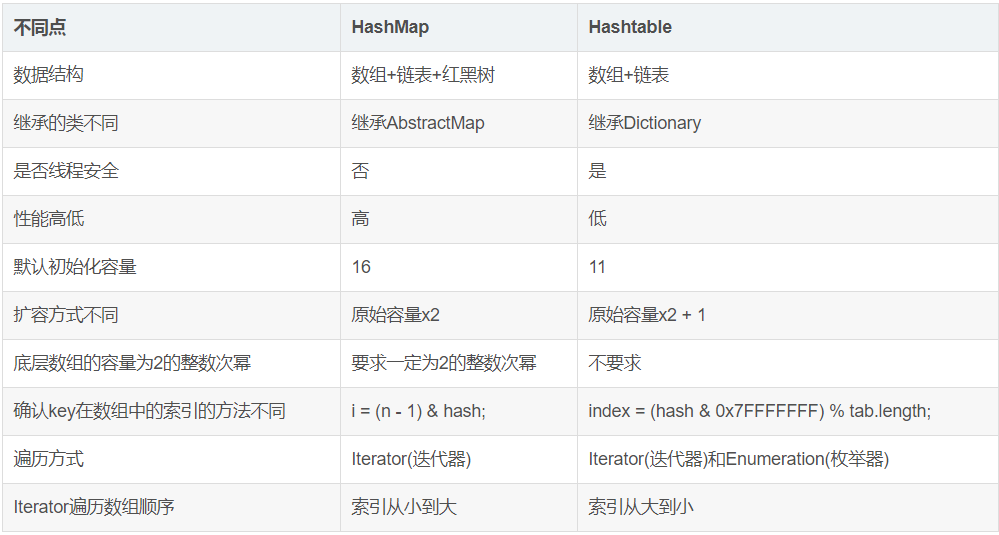
二、HashMap与Hashtable对比
从存储结构和实现来讲基本上都是相同的。它和HashMap的最大的不同是它是线程安全的,另外它不允许key和value为null。Hashtable是个过时的集合类,不建议在新代码中使用,不需要线程安全的场合可以用HashMap替换,需要线程安全的场合可以用ConcurrentHashMap替换
![img_055532ffd728a5b191da63dff0e3c20c.png]()
Hashtable具体阅读源码可参考:
四、总结
在JDK8中HashMap的底层是:数组+链表(散列表)+红黑树
在散列表中有装载因子这么一个属性,当装载因子*初始容量小于散列表元素时,该散列表会再散列,扩容2倍!
装载因子的默认值是0.75,无论是初始大了还是初始小了对我们HashMap的性能都不好
- 装载因子初始值大了,可以减少散列表再散列(扩容的次数),但同时会导致散列冲突的可能性变大(散列冲突也是耗性能的一个操作,要得操作链表(红黑树)!
- 装载因子初始值小了,可以减小散列冲突的可能性,但同时扩容的次数可能就会变多!
初始容量的默认值是16,它也一样,无论初始大了还是小了,对我们的HashMap都是有影响的:
- 初始容量过大,那么遍历时我们的速度就会受影响~
- 初始容量过小,散列表再散列(扩容的次数)可能就变得多,扩容也是一件非常耗费性能的一件事~
从源码上我们可以发现:HashMap并不是直接拿key的哈希值来用的,它会将key的哈希值的高16位进行异或操作,使得我们将元素放入哈希表的时候增加了一定的随机性。
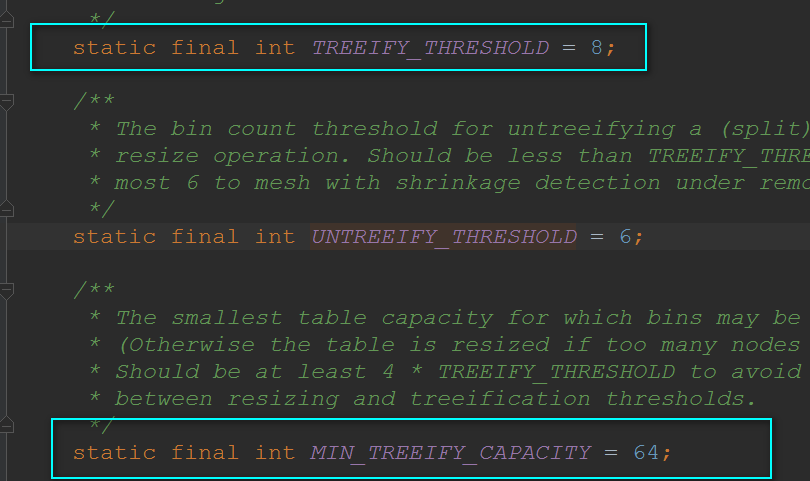
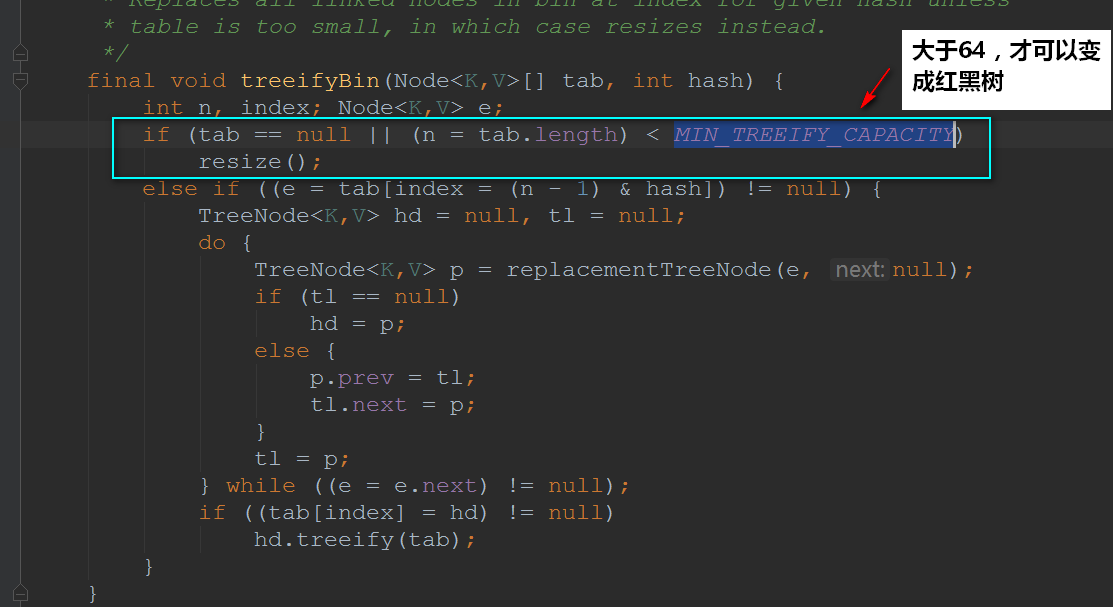
还要值得注意的是:并不是桶子上有8位元素的时候它就能变成红黑树,它得同时满足我们的散列表容量大于64才行的~
![img_7e21b55fa6f4b116bed06298bfc2a47d.png]()
![img_1c021459f93124b541254d49acbafbd3.png]()
明天要是无意外的话,可能会写TreeMap,敬请期待哦~~~~
![img_ba24a2492543840aee7fb40b120472a9.gif]()
如果文章有错的地方欢迎指正,大家互相交流。习惯在微信看技术文章,想要获取更多的Java资源的同学,可以关注微信公众号:Java3y。为了大家方便,刚新建了一下qq群:742919422,大家也可以去交流交流。
谢谢支持了!希望能多介绍给其他有需要的朋友
参考资料:
更多的文章可往:
文章的目录导航