作者:静择
MCP(Model Context Protocol)协议是一个用于 AI 模型和工具之间通信的标准协议。随着 AI 应用变得越来越复杂并被广泛部署,原有的通信机制面临着一系列挑战。近期 MCP 仓库的 PR #206【1】 引入了一个全新的 Streamable HTTP 传输层替代原有的 HTTP+SSE 传输层。本文将详细分析该协议的技术细节和实际优势。
要点速览
- Streamable HTTP 相比 HTTP + SSE 具有更好的稳定性,在高并发场景下表现更优。
- Streamable HTTP 在性能方面相比 HTTP + SSE 具有明显优势,响应时间更短且更稳定。
- Streamable HTTP 客户端实现相比 HTTP + SSE 更简单,代码量更少,维护成本更低。
为什么选择 Streamable HTTP?
![]()
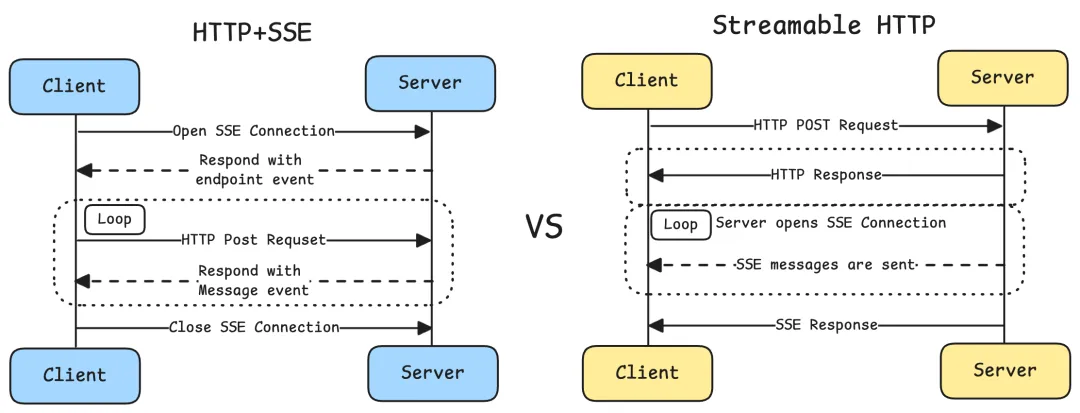
HTTP + SSE 存在的问题
HTTP+SSE 的传输过程实现中,客户端和服务器通过两个主要渠道进行通信:(1)HTTP 请求/响应:客户端通过标准的 HTTP 请求向服务器发送消息。(2)服务器发送事件(SSE):服务器通过专门的 /sse 端点向客户端推送消息,这就导致存在下面三个问题:
- 服务器必须维护长连接,在高并发情况下会导致显著的资源消耗。
- 服务器消息只能通过 SSE 传递,造成了不必要的复杂性和开销。
- 基础架构兼容性,许多现有的网络基础架构可能无法正确处理长期的 SSE 连接。企业防火墙可能会强制终止超时连接,导致服务不可靠。
Streamable HTTP 的改进
Streamable HTTP 是 MCP 协议的一次重要升级,通过下面的改进解决了原有 HTTP + SSE 传输方式的多个关键问题:
- 统一端点:移除了专门建立连接的 /sse 端点,将所有通信整合到统一的端点。
- 按需流式传输:服务器可以灵活选择返回标准 HTTP 响应或通过 SSE 流式返回。
- 状态管理:引入 session 机制以支持状态管理和恢复。
HTTP + SSE vs Streamable HTTP
下面通过实际应用场景中稳定性,性能和客户端复杂度三个角度对比说明 Streamable HTTP 相比 HTTP + SSE 的优势,AI 网关 Higress 目前已经支持了 Streamable HTTP 协议,通过 MCP 官方 Python SDK 的样例 Server 部署了一个 HTTP + SSE 协议的 MCP Server,通过 Higress 部署了一个 Streamable HTTP 协议的 MCP Server。
稳定性对比
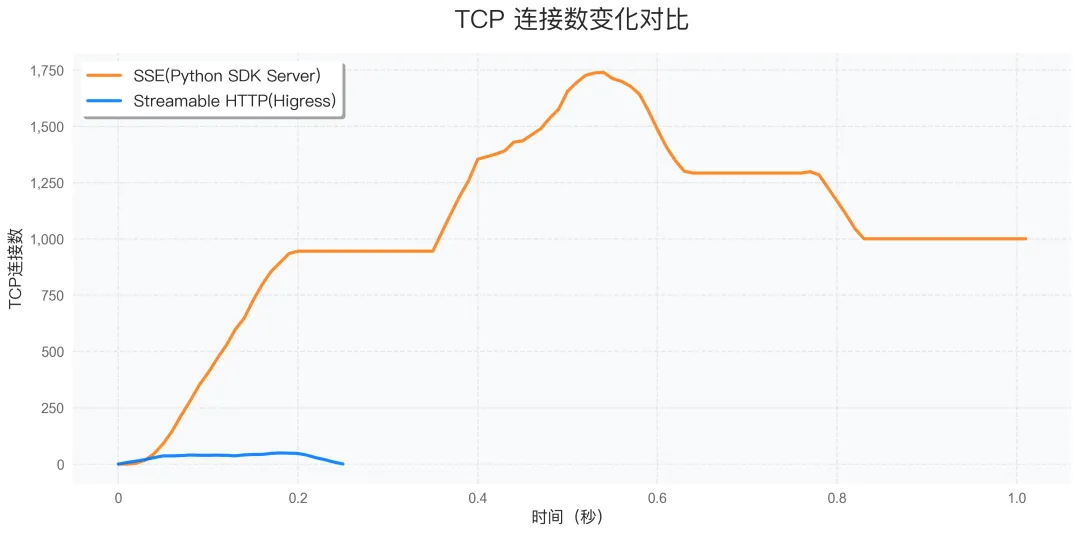
TCP 连接数对比
利用 Python 程序模拟 1000 个用户同时并发访问远程的 MCP Server 并调用获取工具列表,图中可以看出 SSE Server 的 SSE 连接无法复用且需要长期维护,高并发的需求也会带来 TCP 连接数的突增,而 Streamable HTTP 协议则可以直接返回响应,多个请求可以复用同一个 TCP 连接,TCP 连接数最高只到几十条,并且整体执行时间也只有 SSE Server 的四分之一。
![]()
在 1000 个并发用户的测试场景下,Higress 部署的 Streamable HTTP 方案的 TCP 连接数明显低于 HTTP + SSE 方案:
- HTTP + SSE:需要维持大量长连接,TCP 连接数随时间持续增长
- Streamable HTTP:按需建立连接,TCP 连接数维持在较低水平
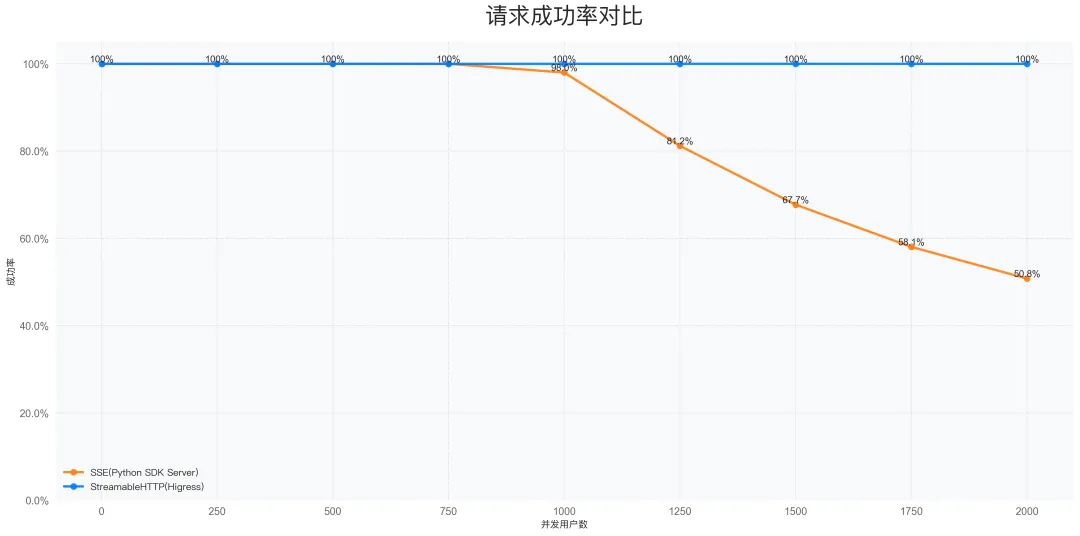
请求成功率对比
实际应用场景中进程级别通常会限制最大连接数,linux 默认通常是 1024。利用 Python 程序模拟不同数量的用户访问远程的 MCP Server 并调用获取工具列表,SSE Server 在并发请求数到达最大连接数限制后,成功率会极速下降,大量的并发请求无法建立新的 SSE 连接而访问失败。
![]()
在不同并发用户数下的请求成功率测试中,Higress 部署的 Streamable HTTP 的成功率显著高于 HTTP + SSE 方案:
- HTTP + SSE:随着并发用户数增加,成功率显著下降
- Streamable HTTP:即使在高并发场景下仍能保持较高的请求成功率
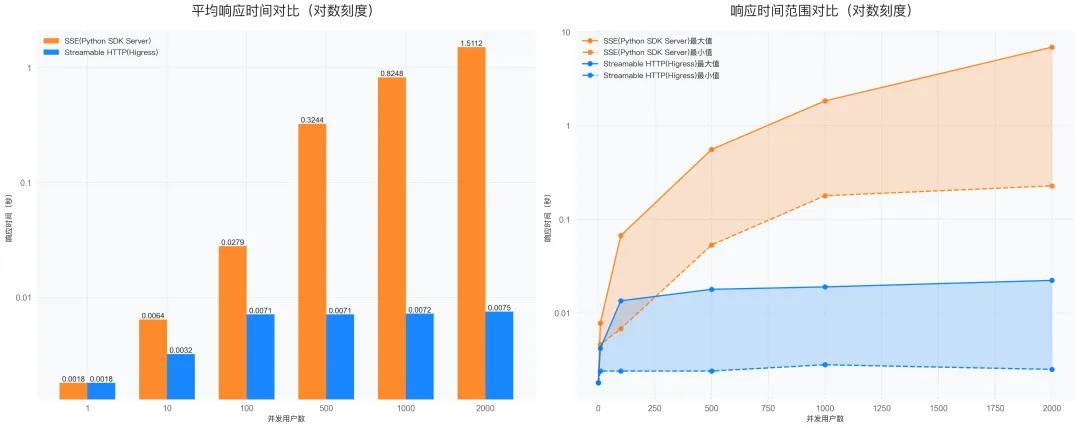
性能对比
这里对比的是社区 Python 版本的 GitHub MCP Server【2】 和 Higress MCP 市场的 GitHub MCP Server
利用 Python 程序模拟不同数量的用户同时并发访问远程的 MCP Server 并调用获取工具列表,并统计调用返回响应的时间,图中给出的响应时间对比为对数刻度,SSE Server 在并发用户数量较多时平均响应时间会从 0.0018s 显著增加到 1.5112s,而 Higress 部署的 Streamable HTTP Server 则依然维持在 0.0075s 的响应时间,也得益于 Higress 生产级的性能相比于 Python Starlette 框架。
![]()
性能测试结果显示,Higress 部署的 Streamable HTTP 在响应时间方面具有明显优势:
- Streamable HTTP 的平均响应时间更短,响应时间波动较小,随并发用户数增加,响应时间增长更平
- HTTP + SSE 的平均响应时间更长,在高并发场景下响应时间波动较大
客户端复杂度对比
Streamable HTTP 支持无状态的服务和有状态的服务,目前的大部分场景无状态的 Streamable HTTP 的可以解决,通过对比两种传输方案的客户端实现代码,可以直观地看到无状态的 Streamable HTTP 的客户端实现简洁性。
HTTP + SSE 客户端样例代码
class SSEClient:
def __init__(self, url: str, headers: dict = None):
self.url = url
self.headers = headers or {}
self.event_source = None
self.endpoint = None
async def connect(self):
# 1. 建立 SSE 连接
async with aiohttp.ClientSession(headers=self.headers) as session:
self.event_source = await session.get(self.url)
# 2. 处理连接事件
print('SSE connection established')
# 3. 处理消息事件
async for line in self.event_source.content:
if line:
message = json.loads(line)
await self.handle_message(message)
# 4. 处理错误和重连
if self.event_source.status != 200:
print(f'SSE error: {self.event_source.status}')
await self.reconnect()
async def send(self, message: dict):
# 需要额外的 POST 请求发送消息
async with aiohttp.ClientSession(headers=self.headers) as session:
async with session.post(self.endpoint, json=message) as response:
return await response.json()
async def handle_message(self, message: dict):
# 处理接收到的消息
print(f'Received message: {message}')
async def reconnect(self):
# 实现重连逻辑
print('Attempting to reconnect...')
await self.connect()
Streamable HTTP 客户端样例代码
class StreamableHTTPClient:
def __init__(self, url: str, headers: dict = None):
self.url = url
self.headers = headers or {}
async def send(self, message: dict):
# 1. 发送 POST 请求
async with aiohttp.ClientSession(headers=self.headers) as session:
async with session.post( self.url, json=message,
headers={'Content-Type': 'application/json'}
) as response:
# 2. 处理响应
if response.status == 200:
return await response.json()
else:
raise Exception(f'HTTP error: {response.status}')
从代码对比可以看出:
- 复杂度:Streamable HTTP 无需处理连接维护、重连等复杂逻辑
- 可维护性:Streamable HTTP 代码结构更清晰,更易于维护和调试
- 错误处理:Streamable HTTP 的错误处理更直接,无需考虑连接状态
【1】PR
#206https://github.com/modelcontextprotocol/modelcontextprotocol/pull/206
【2】GitHub MCP
Serverhttps://github.com/modelcontextprotocol/servers/tree/main/src/github