腾讯混元新一代快思考模型 Turbo S 正式发布。
公告称,区别于 Deepseek R1、混元T1等需要“想一下再回答”的慢思考模型,混元 Turbo S 能够实现“秒回”,更快速输出答案,吐字速度提升一倍,首字时延降低44%。在知识、数理、创作等方面,混元 Turbo S 也有不错表现。
通过长短思维链融合,混元 Turbo S 在保持文科类问题快思考体验的同时,基于自研混元 T1 慢思考模型合成的长思维链数据,显著改进了理科推理能力,实现模型整体性能明显提升。
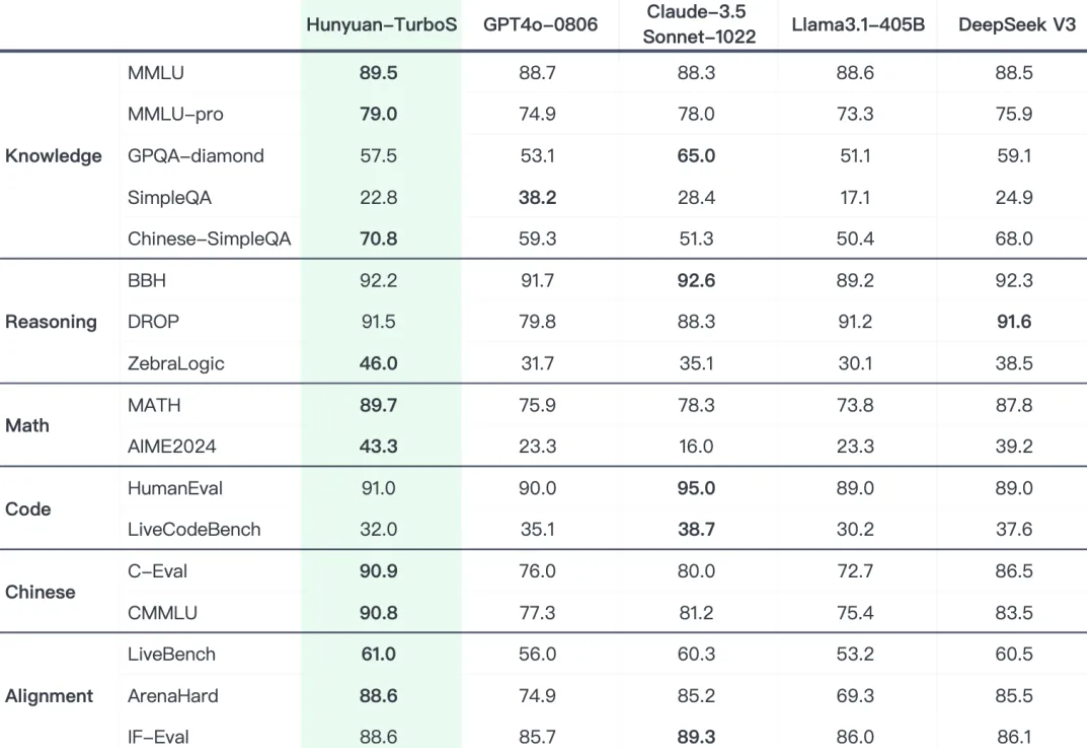
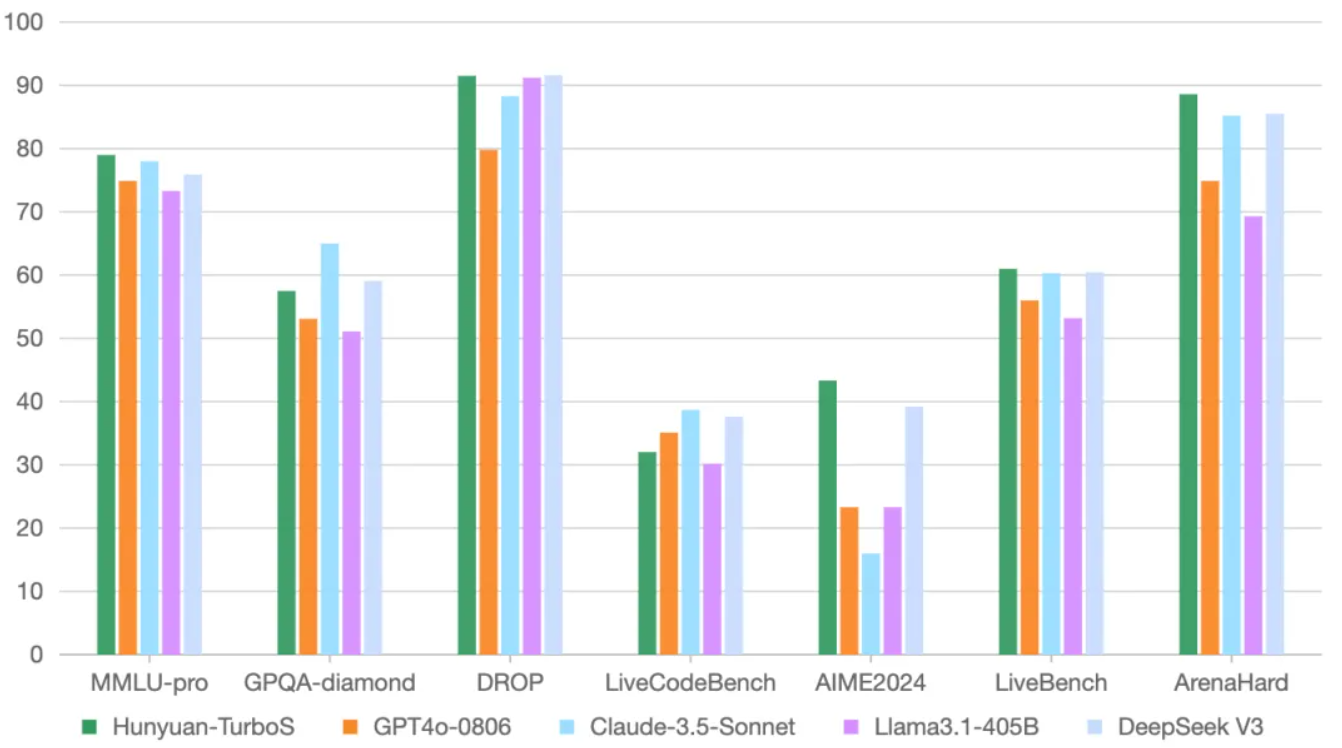
在业界通用的多个公开 Benchmark 上,混元 Turbo S 在知识、数学、推理等多个领域,展现出对标 DeepSeek V3、GPT 4o、Claude等一系列业界领先模型的效果表现。
架构方面,创新采用 Hybrid-Mamba-Transformer 融合模式,混元Turbo S有效降低了传统 Transformer 结构的计算复杂度,减少了KV-Cache缓存占用,实现训练和推理成本的下降。
新的融合模式突破了传统纯 Transformer 结构大模型面临的长文训练和推理成本高的难题。一方面,发挥了 Mamba 高效处理长序列的能力;另一方面,也保留 Transformer 擅于捕捉复杂上下文的优势,最终构建了显存与计算效率双优的混合架构。
这也是工业界首次成功将 Mamba 架构无损地应用在超大型MoE模型上。通过模型架构上的技术创新,混元 Turbo S 部署成本大幅下降,持续推动大模型应用门槛降低。
![]()
![]()
作为旗舰模型,混元 Turbo S 未来将成为腾讯混元系列衍生模型的核心基座,为推理、长文、代码等衍生模型提供基础能力。
基于 Turbo S,通过引入长思维链、检索增强和强化学习等技术,混元也推出了具备深度思考的推理模型 T1。
该模型此前已在腾讯元宝全量上线(腾讯混元T1模型面向所有用户开放),用户可以选择Deepseek R1 或腾讯混元T1模型进行回答。腾讯混元T1模型正式版也将很快上线,对外提供 API 接入等服务。
当前,开发者和企业用户已经可以在腾讯云上通过 API 调用腾讯混元 Turbo S ,即日起一周内免费试用。(腾讯混元turbos模型API免费试用申请: https://cloud.tencent.com/apply/p/i2zophus2x8)
定价上,Turbo S 输入价格为0.8元/百万tokens,输出价格为2元/百万tokens,相比前代混元 Turbo 模型价格下降数倍。腾讯元宝即将逐步灰度上线混元 Turbo S,用户在元宝内选择“Hunyuan” 模型并关闭深度思考即可体验使用。