最近,开源中国 OSCHINA、Gitee 与 Gitee AI 联合发布了《2024 中国开源开发者报告》。报告聚焦 AI 大模型领域,对过去一年的技术演进动态、技术趋势、以及开源开发者生态数据进行多方位的总结和梳理。查看完整报告:2024 中国开源开发者报告.pdf
在第二章《TOP 101-2024 大模型观点》中,浙江大学计算机博士、美国南加州大学访问学者傅聪提出,“算力墙”下,模型效果边际收益递减,训练和运营成本高昂,在这个时间节点,最好的AI产品会是智能体。2025 将会是智能体元年。全文如下。
大模型撞上“算力墙”,超级应用的探寻之路
文/傅聪
近日,大模型教父Sam Altman在Reddit上的评论透露出GPT-5难产的隐忧,直言有限的算力约束让OpenAI面临迭代优先级的艰难抉择,在通往AGI的道路上一路高歌猛进的领头羊似乎撞上了“算力墙”。
除此之外,能耗、资金,难以根除的幻觉,有限的知识更新速率、有限的上下文宽度、高昂的运营成本等等,都让外界对大模型的发展忧心忡忡。面对棘手的困境与难题,大模型的未来,又该何去何从呢?
下一代“明星产品”
“算力墙”下,模型效果边际收益递减,训练和运营成本高昂,在这个时间节点,最好的AI产品会是什么?奥特曼、盖茨、小扎、吴恩达、李彦宏等一众大佬给出了一致的答案——智能体(AI Agent)。2025,将会是智能体元年。
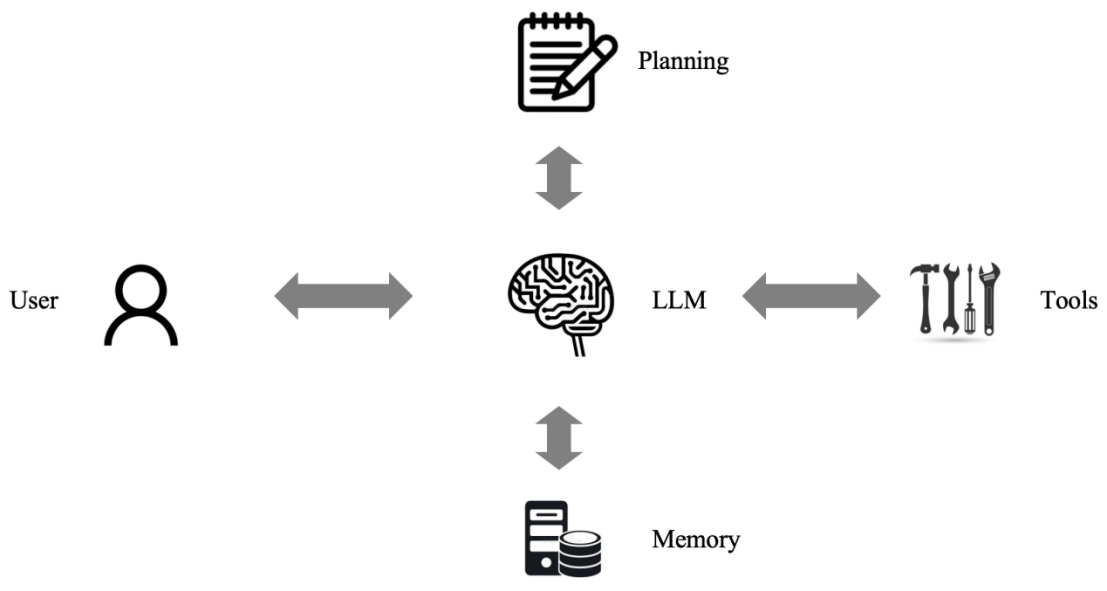
什么是智能体?目前业界一致认可的公式是“智能体=LLM+记忆+规划+工具”:
![]()
大模型充当智能体的“大脑”,负责对任务进行理解、拆解、规划,并调用相应工具以完成任务。同时,通过记忆模块,它还能为用户提供个性化的服务。
智能体为什么是“算力墙”前AI产品的最优解决方案?这一问题的底层逻辑包含两个方面。
- LLM是目前已知最好的智能体底层技术。
智能体作为学术术语由来已久,从上世纪的“符号、专家系统”【1】,到十年前风头无两的强化学习(代表作AlphaGo【3】),再到现在的LLM,agent底层技术经历了三个大的阶段。
符号系统的缺点在于过于依赖人工定义的“符号”和“逻辑”,强化学习苦于训练数据的匮乏和“模态墙”,而LLM一次性解决这些问题。
人类语言就是一种高度抽象、跨模态、表达力充分的符号系统,同时它作为知识的载体,自然地存在大量数据可用于训练,还蕴含了人类的思维模式。
在此基础上训练得到的LLM,自然具备被诱导出类人思考的潜力。在COT(思维链)【4】、TOT(思维树)【5】等技术的加持下,大模型正在学习拆解自己的“思维”,OpenAI的o1就是典型案例,强化了推理能力的同时,也大大缓解了幻觉问题。
2. 大模型做不到的,“现存工具”强势补位。
无法持续更新的知识库,可以通过RAG(Retrieval Augmented Generation,检索增强生成)来解决。
RAG的出现,让各界越来越深刻地认识到,大模型没必要存储那么多知识,只需要如何使用搜索引擎这个外部工具即可。大模型可以在搜索结果上做进一步的信息筛选和优化,而搜索引擎弥补了大模型的知识缺陷,实现了1+1>=2的效果。
RAG可以被理解为智能体的最简单形式。未来的智能体可以实现多种工具的混合使用,甚至多智能体协作,这不是猜想,我们已经在学术界看到了惊艳的早期方案【6,7】。
“四把钥匙”解锁潜力
- 领域模型小型化、平台化会成为新趋势。
“算力墙”是一方面因素,但基座模型的趋同化和运营成本是源动力。GPT、Claude、Gemini虽然各有所长,但实际体验越来越让大家分不出差异,基座模型作为智能体核心,决定了智能体效果下限,人人训练基座的可能性越来越低,“基座服务化”很可能是最合理的商业模式。
甚至,在错误不敏感的应用领域,出现一个开源、无商业限制的基座的可能性也很高。小应用开发商很可能很容易获得一个低成本serving的“量化小基座”。
“7B”是一个magic number!无论是RAG里的向量表征模型,还是文生图、文本识别(OCR)、语音合成(TTS)、人脸识别等等垂直领域,一个1B~7B的小模型已经可以满足很多生产、应用需要,并且效果也在逐步推高【8,9,10】。这些模型,作为智能体的“三头六臂”,不需要太“大”。
同时,从学术角度来讲,各种领域专用模型的技术最优解也在逐渐趋同。应用开发者越来越不需要了解模型的底层技术,只需要懂得如何设计自己应用的任务流,懂一点点COT系列的prompt engineering的技巧,就可以利用Maas(Model as a service)、Aaas(Agent as a service)这样的平台,如玩乐高一般搭建自己的AI云原生应用。
2. 算力层深挖定制化、低能耗的可能性,但固化transformer可能不是最优解
虽说智能体不需要太大的模型,但其运营成本(模型推理计算成本)仍然较高。在短时间内,算力、能源仍然会是大模型领域令人头疼的高墙。
根据报告【1】,能源消耗将会是2030模型scaling最卡脖子的因素。也就是说,在算力到达瓶颈之前,首先可能会出现电能供应不足甚至交不起电费的问题。因此,算力层可以根据大模型底层技术的特性,产出针对性的芯片,尤其是加速运算和降低能耗。这是未来AI芯片领域的最优竞争力。
那么,把transformer“焊死”到板子上就是最佳方案吗?我知道你很急,但你先别急。大模型底层框架还存在底层路线之争。
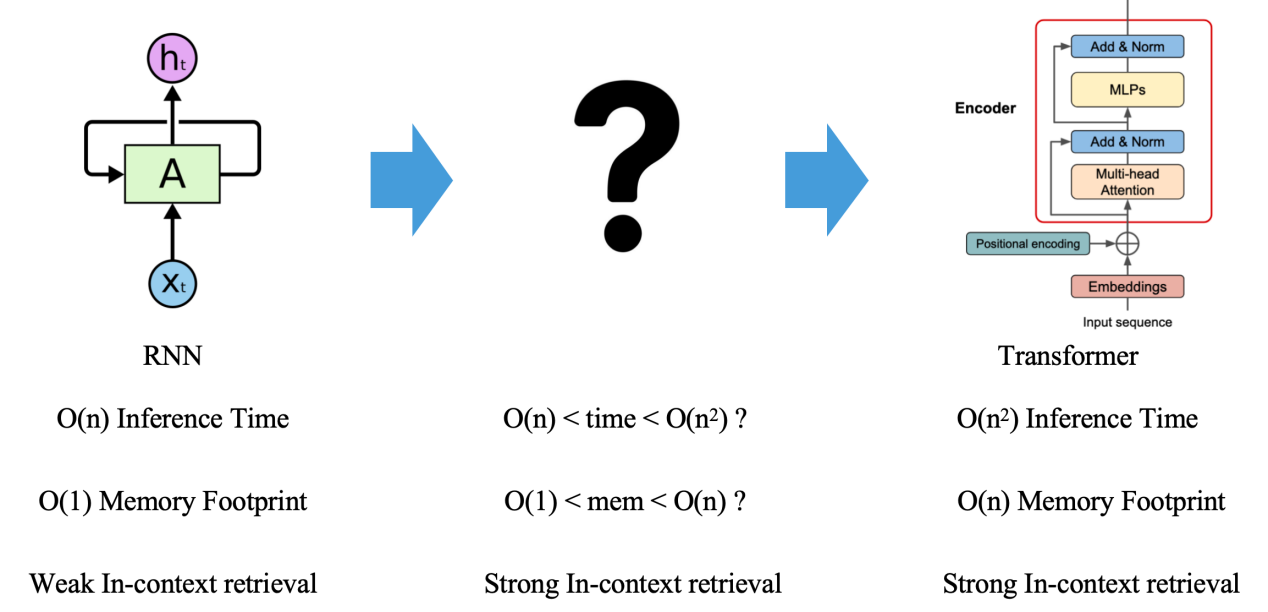
我们知道,Transformer架构呈现了O(n²)的理论计算复杂度,这里的n指的是大模型输入序列的token数量,但其前任语言模型担当RNN只有O(n)的理论计算复杂度。
最近,以Mamba、RWKV为代表的类RNN结构死灰复燃,公开挑战transformer地位。更有最新研究【13】从理论上表明,RNN对比Transformer的表达力,只差一个in-context-retrieval。在这个方向的持续投入下,我们很可能会迎接一个介于RNN和Transformer之间的“新王”。
![]()
因此,算力层短时间内的主题仍然是“半通用化”“高算力”“低能耗”。
3. 合成数据驱动新产业链
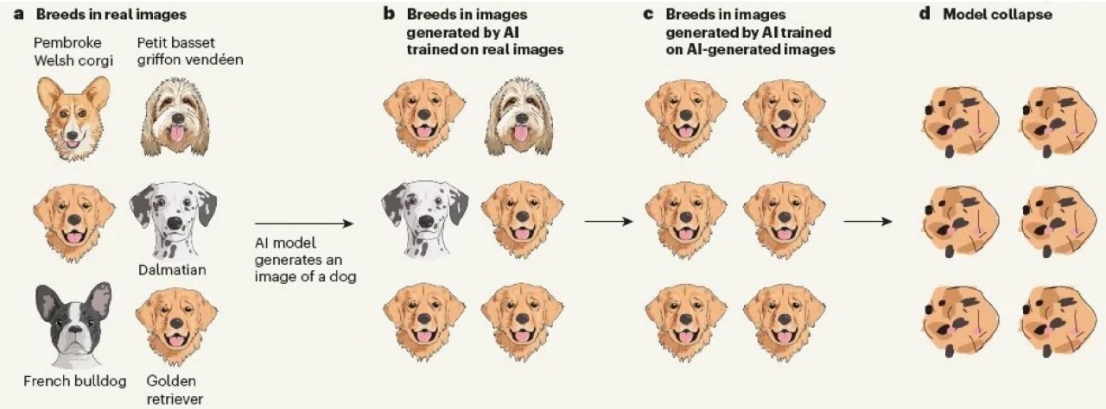
早有机构预测,人类社会可利用训练数据会在2026年耗尽。这可能还是一个乐观估计。光头哥Tibor Blaho还曾爆料,OpenAI用于训练“猎户座“的数据中,已经包含了由GPT-4和O1产出的合成数据。
这不仅是因为自然存在的高质量文本的匮乏,还因为智能体所需的数据很可能需要显式地蕴含任务思考和规划的拆解信息。然而,针对合成数据的问题,学术界早有预警,模型可能会在合成数据上的持续训练中崩坏【14】。
![]()
这是因为合成数据往往携带“错误”和“幻觉”,在一些冷门的知识上尤甚。因此,合成数据的实用秘诀是“去粗取精”,需要一定程度的“人机协同”。在如何构造大批量、高质量的合成数据,让智能体能够在持续地与用户的交互中自我优化而不是劣化,将会成为众多无机器学习技术背景的开发者的头号难题。
因此,面向数据进行定制化合成、评估、测试、标注、人机协同的“纯数据”产业,有可能会走上越来越重要的位置,不仅仅是服务于基座模型厂商。
4. 多模态对齐很可能给基座模型带来质的提升
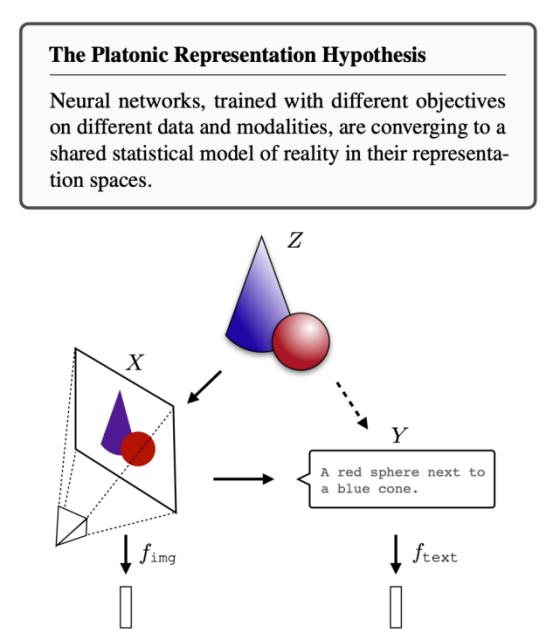
最新研究发现,在没有预先约束和约定下,不同模态领域的最强模型正在向着某个世界模型认知领域收缩【15】,AI模型对不同概念的数字化表达(向量表征)会逐步趋同,构建对这个世界的统一认知。这也符合我们人类对世界的认知:人类通过语言文字这种符号,将不同模态的信号统一地表达,并在脑中构建了某种受限于当前科技水平的统一模型,这是人类意识、社会沟通的前提。
![]()
从这个角度理解,多模态大模型很可能是通向真正AGI的必经之路。将多模态信号统一对齐,是智能体与这个世界“无障碍”交互的前提,换个新潮的词汇,就是我们期待的“具身智能”。谁不想拥有一台自己专属的“Javis”呢?而多模态大模型的突破,也同样依赖前文所述的算力和数据上的沉淀。
参考文献
【1】https://epoch.ai/blog/can-ai-scaling-continue-through-2030
【2】Newell, A., & Simon, H. A. (1956). The Logic Theory Machine – A Complex Information Processing System. IRE Transactions on Information Theory, 2(3), 61-79.
【3】Silver, David, et al. "Mastering the game of Go with deep neural networks and tree search." nature 529.7587 (2016): 484-489.
【4】 Wei, Jason, et al. "Chain-of-thought prompting elicits reasoning in large language models." Advances in neural information processing systems 35 (2022): 24824-24837.
【5】Yao, Shunyu, et al. "Tree of thoughts: Deliberate problem solving with large language models." Advances in Neural Information Processing Systems 36 (2024).
【6】Karpas, Ehud, et al. "MRKL Systems: A modular, neuro-symbolic architecture that combines large language models, external knowledge sources and discrete reasoning." arXiv preprint arXiv:2205.00445 (2022).
【7】Schick, Timo, et al. "Toolformer: Language models can teach themselves to use tools." Advances in Neural Information Processing Systems 36 (2024).
【8】https://huggingface.co/spaces/mteb/leaderboard
【9】https://github.com/deep-floyd/IF
【10】https://developer.nvidia.com/blog/pushing-the-boundaries-of-speech-recognition-with-nemo-parakeet-asr-models/
【11】Mamba: Linear-time sequence modeling with selective state spaces
【12】Peng, Bo, et al. "Rwkv: Reinventing rnns for the transformer era." arXiv preprint arXiv:2305.13048 (2023).
【13】Wen, Kaiyue, Xingyu Dang, and Kaifeng Lyu. "Rnns are not transformers (yet): The key bottleneck on in-context retrieval." arXiv preprint arXiv:2402.18510 (2024).
【14】AI Models Collapse When Trained on Recursively Generated Data’
【15】The Platonic Representation Hypothesis
作者简介:
![]()
傅聪
浙江大学计算机博士,美国南加州大学访问学者,《业务驱动的推荐系统:方法与实践》作者。高性能检索算法NSG、SSG的发明者,知乎科技博主“傅聪Cong”。
前阿里巴巴算法专家,目前就职于Shopee(新加坡)任资深算法专家。在顶会和期刊TPAMI、KDD、VLDB、IJCAI、EMNLP、CIKM等发表十余篇论文,同时也是Tpami、TKDE、KDD、ICLR、AAAI、IJCAI、EMNLP、ICLR等会议的审稿人。
查看完整报告:2024 中国开源开发者报告.pdf