GitOps 是一种侧重于自动化、协作和持续交付的基础设施管理现代方法。它的核心理念是将 Git 作为配置和代码的唯一真理源。在 GitOps 实践中,对基础设施的任何更改都必须通过 Pull Request(合并请求)来进行,这些合并请求需要在并入主分支之前得到团队其他成员的审查和同意。
在这篇文章里,我们将介绍几款开源的 GitOps 工具:
- 基础设施即代码(IaC):Terraform
- 基础设施即代码(IaC):Pulumi
- 为 Kubernetes 设计的持续交付工具:ArgoCD
- 快速、兼具 Git 友好性的 API 客户端:Bruno
- 全方位人到数据库操作管理:Bytebase
![file]()
Terraform
Terraform 是一款开源的基础设施即代码(IaC)工具,它使得构建、修改以及版本控制基础设施变得既安全又高效。它覆盖了从低级组件(如计算实例、存储和网络)到高级组件(如 DNS 配置和 SaaS 功能)的广泛需求。
Terraform 采用 HashiCorp 配置语言(HCL)作为主要的配置语言,并同时支持 JSON 格式,以满足不同用户的编写习惯。
![file]()
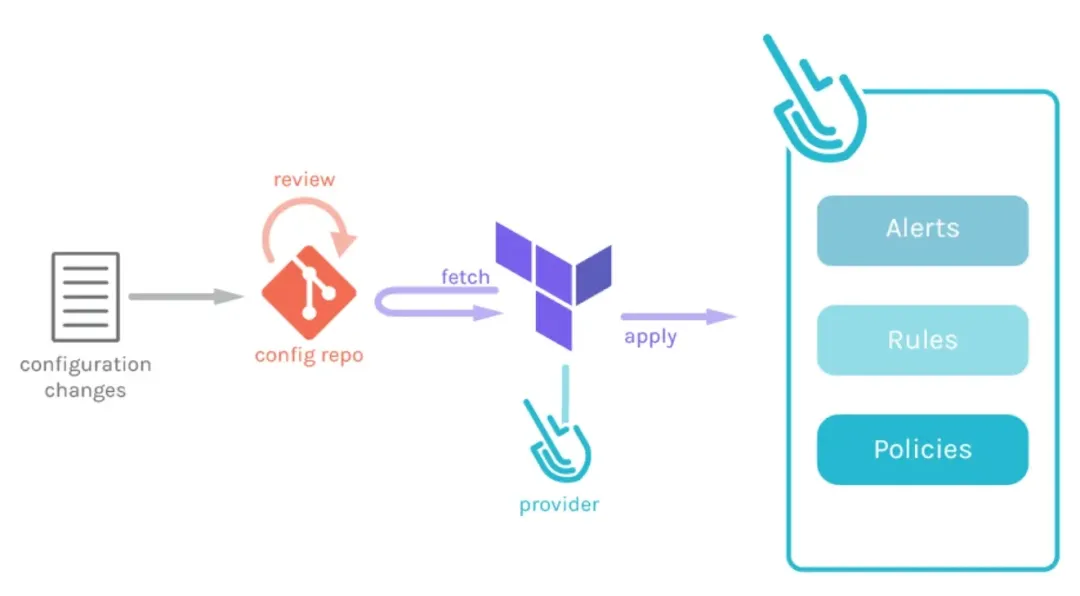
为了实施 GitOps,你需要创建一个含有 Terraform 配置的 Git 仓库,通过 Terraform 定义你的基础设施,并通过流水线和 Pull Request 来管理基础设施的更新。这样不仅能保证基础设施配置的版本控制,还能通过代码审查机制保障更改的质量。
![file]()
Pulumi
Pulumi 是一款开源的基础设施即代码(IaC)工具,它独特之处在于允许开发者使用他们偏好的编程语言——如 Python、JavaScript 或 Go——来创建、部署和管理云基础设施。这一特性使得 Pulumi 与 Terraform 有所不同,后者主要使用专用的配置语言。
![file]()
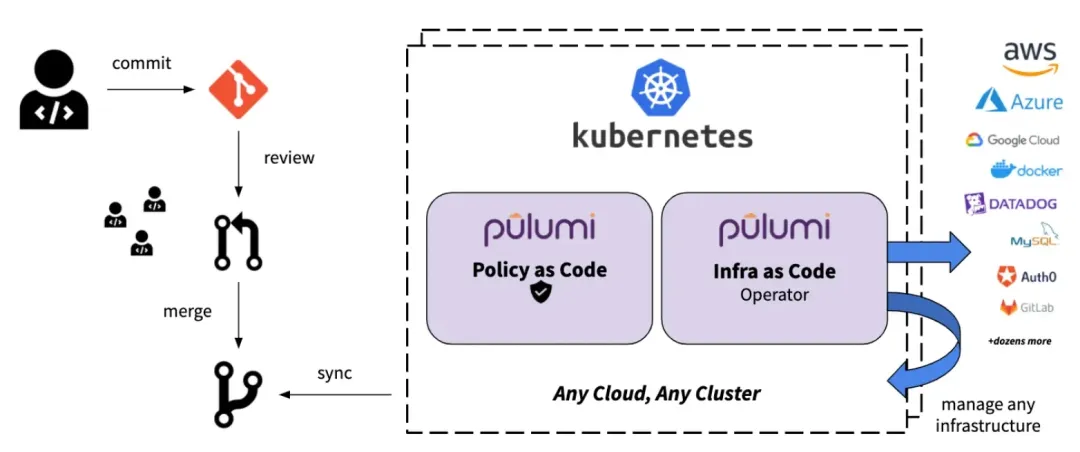
类似于 Terraform,Pulumi 也支持 GitOps 的实施方式。你可以创建一个含有 Pulumi 配置文件的 Git 仓库,利用 Pulumi 定义你的云基础设施,并通过流水线和 Pull Request 来管理这些基础设施的更新。这种方法不仅有助于基础设施配置的版本控制,而且能够通过代码审查机制来提高变更的质量和安全性。
![file]()
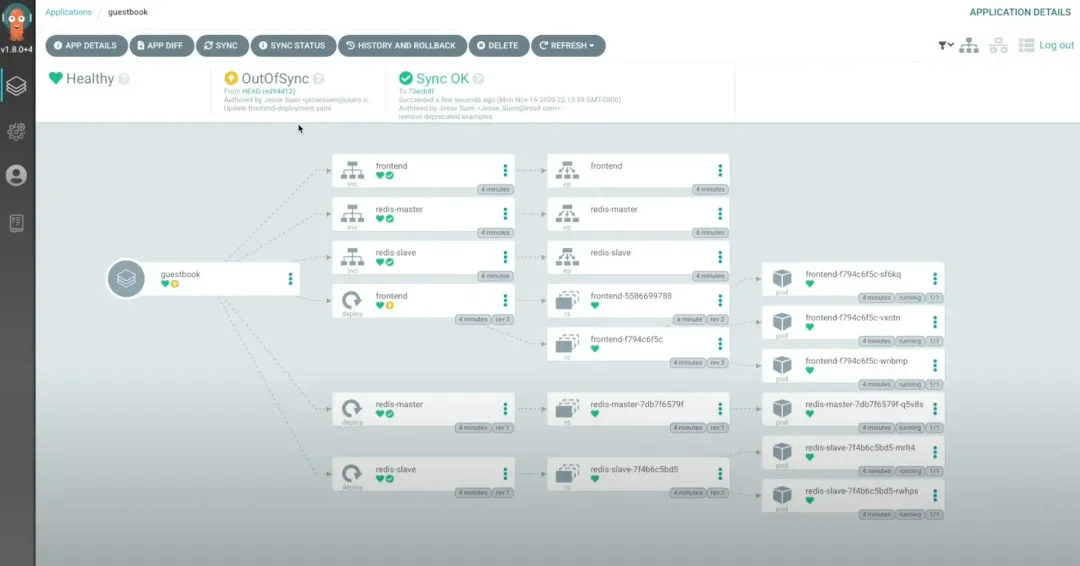
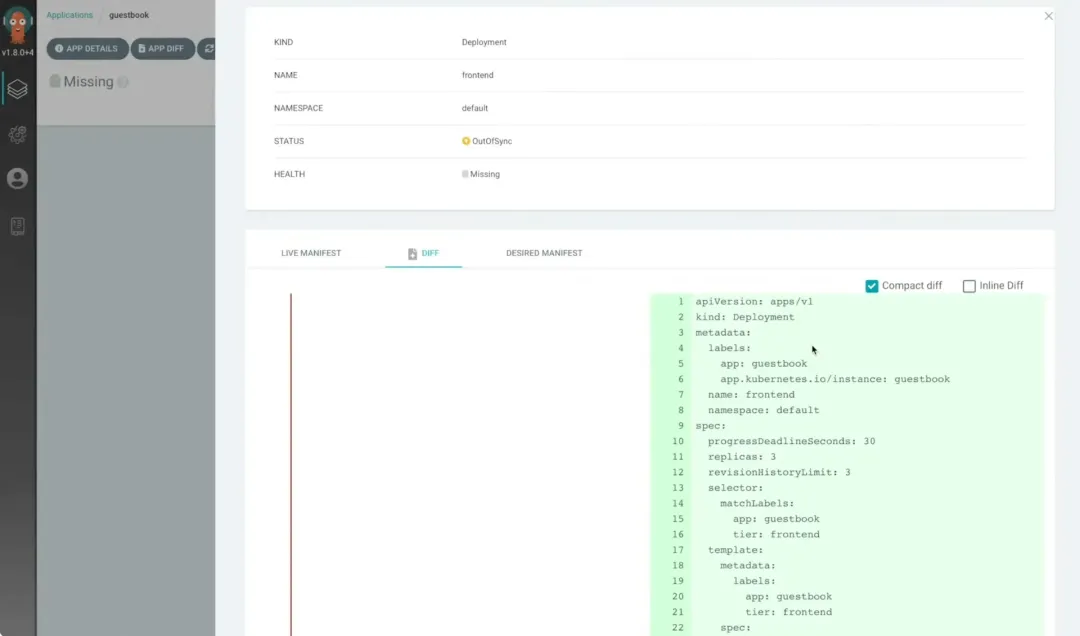
ArgoCD
ArgoCD 是一款专为 Kubernetes 设计的声明式 GitOps 持续交付工具。
![file]()
它采用 GitOps 的方式,将 Git 仓库作为定义应用目标状态的核心依据。Kubernetes 的部署清单可以通过多种形式进行指定,包括但不限于 kustomize 应用、helm 图表以及 jsonnet 文件。
通过 Argo CD,可以自动化地将应用的目标状态部署到特定的运行环境中。这个过程支持跟踪分支、标签的最新更新,或者可以指定部署到某个 Git 提交对应的特定版本,以确保部署的一致性和准确性。
![file]()
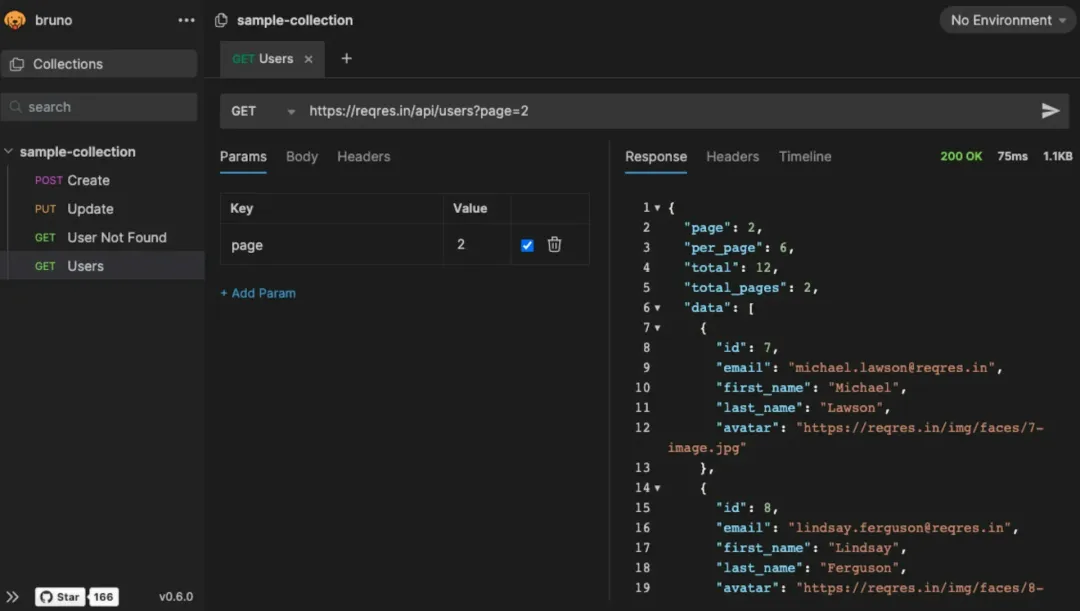
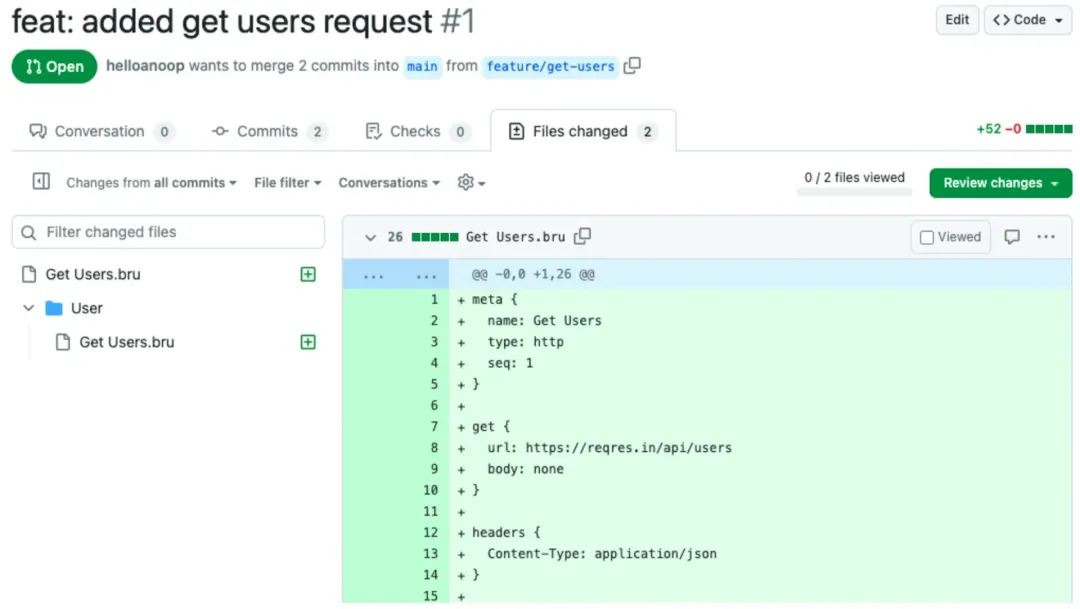
Bruno
Bruno 是一个快速、兼具 Git 友好性的开源 API 客户端,目标是改变 Postman、Insomnia 等流行工具所代表的传统做法。
![file]()
它通过 Bru 这种纯文本标记语言,直接在你的文件系统上的一个文件夹中存储 API 请求相关的信息,使得管理 API 请求集成简洁且高效。
在 GitOps 实践中,Bruno 让你可以通过 Git 或任意版本控制系统,轻松地与团队成员共享和协作开发 API 请求集。这种方式无疑为 API 开发带来了更高的灵活性和团队协作效率。
![file]()
Bytebase
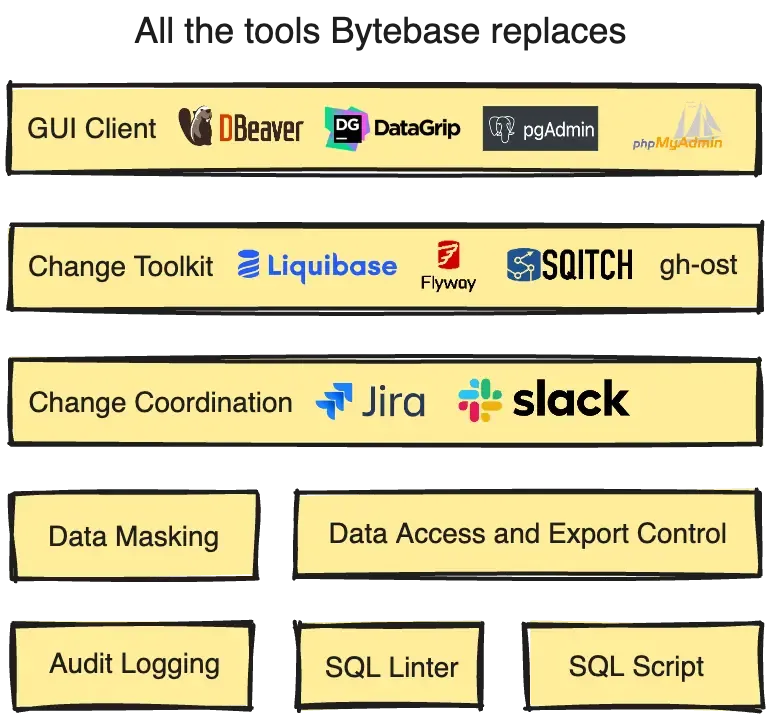
Bytebase 是一款开源的数据库 DevOps 工具,被誉为数据库管理领域的 GitLab/GitHub,它支持应用程序开发生命周期中的数据库管理。这款工具为数据库管理员(DBA)、开发人员和平台工程师提供了一个集中的网络协作平台,将 DBeaver、Liquibase、Flyway 等多种数据库工具整合在一起,方便使用。
![file]()
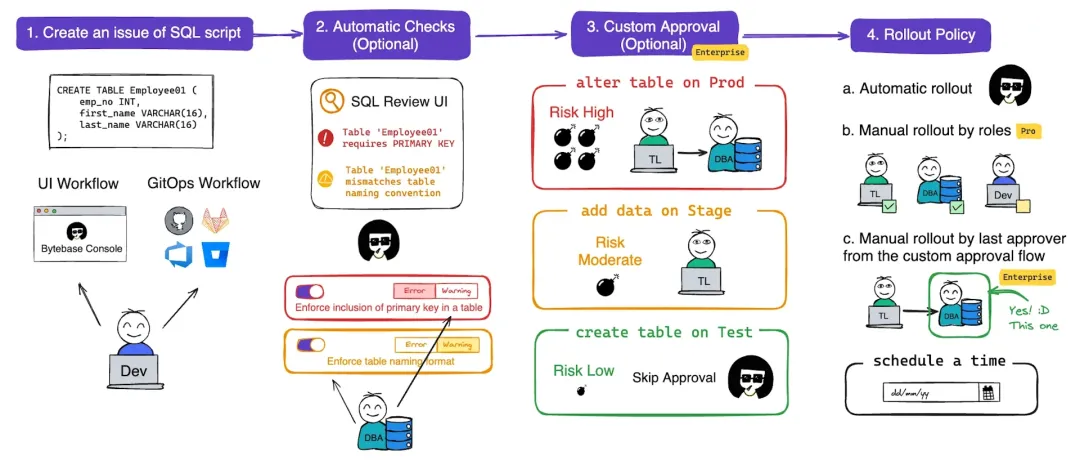
除了直观的 UI 工作流,Bytebase 还引入了 GitOps 工作流程来管理数据库变更。允许通过 Pull Request 来启动数据库变更请求。并且,Bytebase 提供了 SQL 审核、自定义的审批流程以及部署策略,从而能够以更先进的 GitOps 方式来管理数据库变更。这不仅提高了数据库管理的效率和安全性,也为团队协作带来了新的可能性。
![file]()
上述介绍的每一款工具都有其特色和强项。通过了解你的特定需求,可以挑选最适合自己场景的工具。
💡 更多资讯,请关注 Bytebase 公号:Bytebase