单体架构下锁的实现方案
1. ReentrantLock全局锁
ReentrantLock(可重入锁),指的是一个线程再次对已持有的锁保护的临界资源时,重入请求将会成功。
简单的与我们常用的Synchronized进行比较:
| |
ReentrantLock |
Synchronized |
| 锁实现机制 |
依赖AQS |
监视器模式 |
| 灵活性 |
支持响应超时、中断、尝试获取锁 |
不灵活 |
| 释放形式 |
必须显示调用unlock()释放锁 |
自动释放监视器 |
| 锁类型 |
公平锁 & 非公平锁 |
非公平锁 |
| 条件队列 |
可关联多个条件队列 |
关联一个条件队列 |
| 可重入性 |
可重入 |
可重入 |
AQS机制:如果被请求的共享资源空闲,那么就当前请求资源的线程设置为有效的工作线程,将共享资源通过CAScompareAndSetState设置为锁定状态;如果共享资源被占用,就采用一定的阻塞等待唤醒机制(CLH变体的FIFO双端队列)来保证锁分配。
可重入性:无论是公平锁还是非公平锁的情况,加锁过程会利用一个state值
private volatile int state
- state值初始化的时候为0,表示没有任何线程持有锁
- 当有线程来请求该锁时,state值会自增1,同一个线程多次获取锁,就会多次+1,这就是可重入的概念
- 解锁也是对state值自减1,一直到0,此线程对锁释放。
public class LockExample {
static int count = 0;
static ReentrantLock lock = new ReentrantLock();
public static void main(String[] args) throws InterruptedException {
Runnable runnable = new Runnable() {
@Override
public void run() {
try {
// 加锁
lock.lock();
for (int i = 0; i < 10000; i++) {
count++;
}
} catch (Exception e) {
e.printStackTrace();
}
finally {
// 解锁,放在finally子句中,保证锁的释放
lock.unlock();
}
}
};
Thread thread1 = new Thread(runnable);
Thread thread2 = new Thread(runnable);
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println("count: " + count);
}
}
/**
* 输出
* count: 20000
*/
2. Mysql行锁、乐观锁
乐观锁即是无锁思想,一般都是基于CAS思想实现的,而在MySQL中通过version版本号 + CAS无锁形式实现乐观锁;例如T1,T2两个事务一起并发执行时,当T2事务执行成功提交后,会对version+1,所以T1事务执行的version条件就无法成立了。
对sql语句进行加锁以及状态机的操作,也可以避免不同线程同时对count值访问导致的数据不一致问题。
// 乐观锁 + 状态机
update
table_name
set
version = version + 1,
count = count + 1
where
id = id AND version = version AND count = [修改前的count值];
// 行锁 + 状态机
update
table_name
set
count = count + 1
where
id = id AND count = [修改前的count值]
for update;
3. 细粒度的ReetrantLock锁
如果我们直接采用ReentrantLock全局加锁,那么这种情况是一条线程获取到锁,整个程序全部的线程来到这里都会阻塞;但是我们在项目里面想要针对每个用户在操作的时候实现互斥逻辑,所以我们需要更加细粒度的锁。
public class LockExample {
private static Map<String, Lock> lockMap = new ConcurrentHashMap<>();
public static void lock(String userId) {
// Map中添加细粒度的锁资源
lockMap.putIfAbsent(userId, new ReentrantLock());
// 从容器中拿锁并实现加锁
lockMap.get(userId).lock();
}
public static void unlock(String userId) {
// 先从容器中拿锁,确保锁的存在
Lock locak = lockMap.get(userId);
// 释放锁
lock.unlock();
}
}
弊端:如果每一个用户请求共享资源,就会加锁一次,后续该用户就没有在登录过平台,但是锁对象会一直存在于内存中,这等价于发生了内存泄漏,所以锁的超时和淘汰机制机制需要实现。
4. 细粒度的Synchronized全局锁
上面的加锁机制使用到了锁容器ConcurrentHashMap,该容易为了线程安全的情况,多以底层还是会用到Synchronized机制,所以有些情况,使用lockMap需要加上两层锁。
那么我们是不是可以直接使用Synchronized来实现细粒度的锁机制
public class LockExample {
public static void syncFunc1(Long accountId) {
String lock = new String(accountId + "").intern();
synchronized (lock) {
System.out.println(Thread.currentThread().getName() + "拿到锁了");
// 模拟业务耗时
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(Thread.currentThread().getName() + "释放锁了");
}
}
public static void syncFunc2(Long accountId) {
String lock = new String(accountId + "").intern();
synchronized (lock) {
System.out.println(Thread.currentThread().getName() + "拿到锁了");
// 模拟业务耗时
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(Thread.currentThread().getName() + "释放锁了");
}
}
// 使用 Synchronized 来实现更加细粒度的锁
public static void main(String[] args) {
new Thread(()-> syncFunc1(123456L), "Thread-1").start();
new Thread(()-> syncFunc2(123456L), "Thread-2").start();
}
}
/**
* 打印
* Thread-1拿到锁了
* Thread-1释放锁了
* Thread-2拿到锁了
* Thread-2释放锁了
*/
- 从代码中我们发现实现加锁的对象其实就是一个与用户ID相关的一个字符串对象,这里可能会有疑问,我每一个新的线程进来,new的都是一个新的字符串对象,只不过字符串内容一样,怎么能够保证可以安全的锁住共享资源呢;
- 这其实需要归功于后面的
intern()函数的功能;
intern()函数用于在运行时将字符串添加到堆空间中的字符串常量池中,如果字符串已经存在,返回字符串常量池中的引用。
分布式架构下锁的实现方案
核心问题:我们需要找到一个多个进程之间所有线程可见的区域来定义这个互斥量。
一个优秀的分布式锁的实现方案应该满足如下几个特性:
- 分布式环境下,可以保证不同进程之间的线程互斥
- 同一时刻,同时只允许一条线程成功获取到锁资源
- 保证互斥量的地方需要保证高可用性
- 要保证可以高性能的获取锁和释放锁
- 可以支持同一线程的锁重入性
- 具备合理的阻塞机制,竞争锁失败的线程要有相应的处理方案
- 支持非阻塞式的获取锁。获取锁失败的线程可以直接返回
- 具备合理的锁失效机制,如超时失效等,可以确保避免死锁情况出现
Redis实现分布式锁
- redis属于中间件,可独立部署;
- 对于不同的Java进程来说都是可见的,同时性能也非常可观
- 依赖与redis本身提供的指令
setnx key value来实现分布式锁;区别于普通set指令的是只有当key不存在时才会设置成功,key存在时会返回设置失败
代码实例:
// 扣库存接口
@RequestMapping("/minusInventory")
public String minusInventory(Inventory inventory) {
// 获取锁
String lockKey = "lock-" + inventory.getInventoryId();
int timeOut = 100;
Boolean flag = stringRedisTemplate.opsForValue()
.setIfAbsent(lockKey, "竹子-熊猫",timeOut,TimeUnit.SECONDS);
// 加上过期时间,可以保证死锁也会在一定时间内释放锁
stringRedisTemplate.expire(lockKey,timeOut,TimeUnit.SECONDS);
if(!flag){
// 非阻塞式实现
return "服务器繁忙...请稍后重试!!!";
}
// ----只有获取锁成功才能执行下述的减库存业务----
try{
// 查询库存信息
Inventory inventoryResult =
inventoryService.selectByPrimaryKey(inventory.getInventoryId());
if (inventoryResult.getShopCount() <= 0) {
return "库存不足,请联系卖家....";
}
// 扣减库存
inventoryResult.setShopCount(inventoryResult.getShopCount() - 1);
int n = inventoryService.updateByPrimaryKeySelective(inventoryResult);
} catch (Exception e) { // 确保业务出现异常也可以释放锁,避免死锁
// 释放锁
stringRedisTemplate.delete(lockKey);
}
if (n > 0)
return "端口-" + port + ",库存扣减成功!!!";
return "端口-" + port + ",库存扣减失败!!!";
}
作者:竹子爱熊猫
链接:https://juejin.cn/post/7038473714970656775
过期时间的合理性分析:
因为对于不同的业务,我们设置的过期时间的长短都会不一样,太长了不合适,太短了也不合适;
所以我们想到的解决方案是设置一条子线程,给当前锁资源续命。具体实现是,子线程间隔2-3s去查询一次key是否过期,如果还没有过期则代表业务线程还在执行业务,那么则为该key的过期时间加上5s。
但是为了避免主线程意外死亡后,子线程会一直为其续命,造成“长生锁”的现象,所以将子线程变为主(业务)线程的守护线程,这样子线程就会跟着主线程一起死亡。
// 续命子线程
public class GuardThread extends Thread {
private static boolean flag = true;
public GuardThread(String lockKey,
int timeOut, StringRedisTemplate stringRedisTemplate){
……
}
@Override
public void run() {
// 开启循环续命
while (flag){
try {
// 先休眠一半的时间
Thread.sleep(timeOut / 2 * 1000);
}catch (Exception e){
e.printStackTrace();
}
// 时间过了一半之后再去续命
// 先查看key是否过期
Long expire = stringRedisTemplate.getExpire(
lockKey, TimeUnit.SECONDS);
// 如果过期了,代表主线程释放了锁
if (expire <= 0){
// 停止循环
flag = false;
}
// 如果还未过期
// 再为则续命一半的时间
stringRedisTemplate.expire(lockKey,expire
+ timeOut/2,TimeUnit.SECONDS);
}
}
}
// 创建子线程为锁续命
GuardThread guardThread = new GuardThread(lockKey,timeOut,stringRedisTemplate);
// 设置为当前 业务线程 的守护线程
guardThread.setDaemon(true);
guardThread.start();
作者:竹子爱熊猫
链接:https://juejin.cn/post/7038473714970656775
Redis主从架构下锁失效的问题
为了在开发过程保证Redis的高可用,会采用主从复制架构做读写分离,从而提升Redis的吞吐量以及可用性。但是如果一条线程在redis主节点上获取锁成功之后,主节点还没有来得及复制给从节点就宕机了,此时另一条线程访问redis就会在从节点上面访问,同时也获取锁成功,这时候临界资源的访问就会出现安全性问题了。
解决办法:
- 红锁算法(官方提出的解决方案):多台独立的Redis同时写入数据,在锁失效时间之内,一半以上的机器写成功则返回获取锁成功,失败的时候释放掉那些成功的机器上的锁。但这种做法缺点是成本高需要独立部署多台Redis节点。
- 额外记录锁状态:再额外通过其他独立部署的中间件(比如DB)来记录锁状态,在新线程获取锁之前需要先查询DB中的锁持有记录,只要当锁状态为未持有时再尝试获取分布式锁。但是这种情况缺点显而易见,获取锁的过程实现难度复杂,性能开销也非常大;另外还需要配合定时器功能更新DB中的锁状态,保证锁的合理失效机制。
- 使用Zookepper实现
Zookeeper实现分布式锁
Zookeeper数据区别于redis的数据,数据是实时同步的,主节点写入后需要一半以上的节点都写入才会返回成功。所以如果像电商、教育等类型的项目追求高性能,可以放弃一定的稳定性,推荐使用redis实现;例如像金融、银行、政府等类型的项目,追求高稳定性,可以牺牲一部分性能,推荐使用Zookeeper实现。
分布式锁性能优化
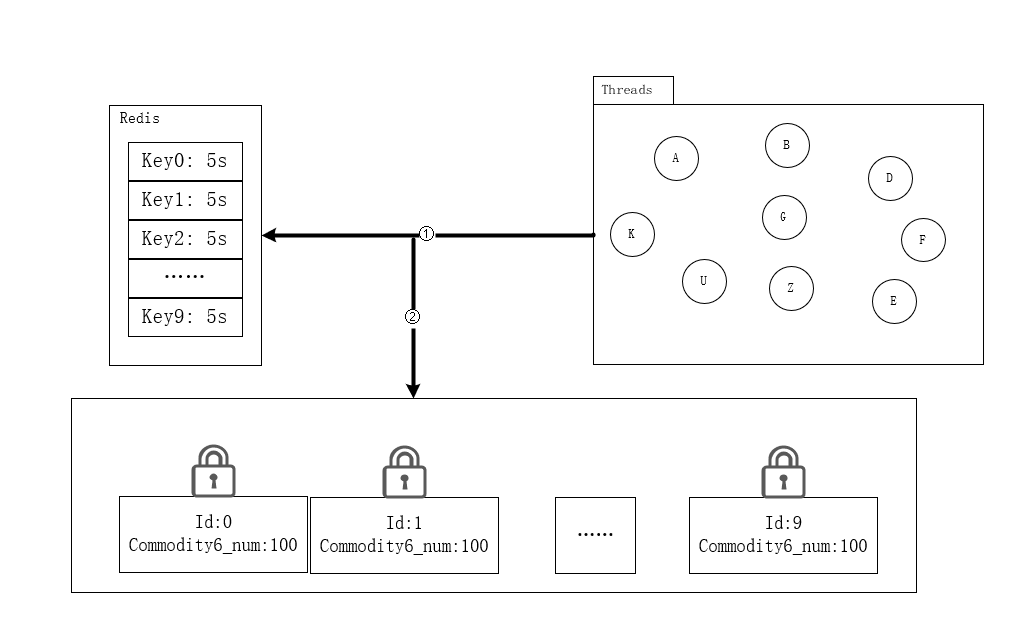
上面加锁确实解决了并发情况下线程安全的问题,但是我们面对100w个用户同时去抢购1000个商品的场景该如何解决呢?
![]()
- 可与将共享资源做一下提前预热,分段分散存储一份。抢购时间为下午15:00,提前再14:30左右将商品数量分成10份,并将每一块数据进行分别加锁,来防止并发异常。
- 另外也需要在redis中写入10个key,每一个新的线程进来先随机的分配一把锁,然后进行后面的减库存逻辑,完成之后释放锁,以便之后的线程使用。
- 这种分布式锁的思想就是,将原先一把锁就可以实现的多线程同步访问共享资源的功能,为了提高瞬时情况下多线程的访问速度,还需要保证并发安全的情况下一种实现方式。
参考文章:
-
https://juejin.cn/post/7236213437800890423
-
https://juejin.cn/post/7038473714970656775
-
https://tech.meituan.com/2019/12/05/aqs-theory-and-apply.html
作者:京东科技 焦泽斌
来源:京东云开发者社区 转载请注明来源