11 月 25 日,OSC 源创会杭州站成功举办。本期源创会以“从数据到大模型应用”为主题,邀请到学界、业界多位讲师分享其在数据与 AI 技术方面的研究成果和经验。接下来就一起看看活动现场吧!
依然是人气满满的现场!
小伙伴们都中奖了吗?
源创会老传统,吃披萨 ⬅️ 🌺 ➡️ 源创会新传统,程序员保健操
欢迎小伙伴们多多提问、多多拍照记录呀~
感谢合作伙伴们的大力支持!
进入正题,内容回顾开始!
唐谈:诗画一律--跨模态大模型在古画色彩修复中的探索与实践
浙江大学百人计划研究员(博导)唐谈分享了《诗画一律--跨模态大模型在古画色彩修复中的探索与实践》主题演讲。来自艺术与考古学院的唐谈非常关心一个命题:古人有很多画作保存下来,但是大家去博物馆看都比较旧了,那么我们有没有可能用现在的大模型,对其做色彩的还原?唐谈指出,虽然这个想法比较直观,但是在应用过程中可能不是那么好做。
唐谈介绍了一种数字手段修复古画的工作流:原始图像—收集画作—推测配色—还原色彩—修复图像。但是在第二步,用图搜图的方式收集与原始画作相似的图像时,计算机往往收集到的是与原始画作相似的褪色古画,与最初的目的相悖。此外,第三步往往也需要大量专家人力的介入。
在长期的工作中,唐谈摸索出了一个方法可以解决上述问题——从古画上的元素中找到那个经过很长时间都不会褪色的部分,即文本信息。以元代赵孟頫的《洞庭东山图》为例。画上诗句为:洞庭波兮山崨嶪,川可济兮不可以涉。木兰为舟兮桂为楫,渺余怀兮风一叶。其中前三句中的“波”、“山”、“川”、“木兰”均为可参考的意象,用于帮助还原色彩,诗的第四句则为意境描述,唐谈也正在探索用多模态能力去更好地还原意境。
这种借文本辅助修复古画也有理论依据,苏轼曾在一首诗中写过“诗画本一律,天工与清新。”唐谈指出,书法本身也是一种造型艺术,画上的书法不能简单看做文本,它实际上也是一种图像。为了寻找色彩还原的参考依据,唐谈试图使用诗画融合大模型去召回在意境上一致的其他画作。而实验对照组只考虑图像信息,同样去“召回”画面色彩上相一致的画作。为了衡量召回的效果,常规的做法是计算召回画作与目标画作之间的相似性。最终结果显示,尽管色彩一致召回的图像比意境一致召回的图像看起来表现更好,但对于色彩修复问题,色彩一致也意味着无法提供丰富的色彩参考信息,而意境一致的召回则一定程度上解决了这个问题。
进一步,通过观察意境一致的画作,唐谈发现了一个有趣的矛盾——画作创作于赵孟頫遭贬期间,其悲凉的近况似乎于明亮鲜绿的色彩不一致。为了解释这一矛盾,唐谈与领域专家展开了更深入的讨论。一个令人激动的猜想是诗画融合大模型学习到了更深层次的意境表征——古诗中借美景抒悲情的意境表达。
此外,唐谈还分享了更多关于通过大模型修复古画的细节,感兴趣的 OSCer 可以查看“OSC 开源社区”视频号直播回放,查看完整分享。
唐谈课题组常年招收计算机(电子信息)、设计学博士,详情请查看 https://person.zju.edu.cn/tangtan
王翔宇:向量数据库-AI 时代的信息检索引擎
Zilliz AI 算法专家王翔宇发表了《向量数据库-AI 时代的信息检索引擎》主题演讲。王翔宇首先介绍了搜索技术的演进,传统信息检索的核心思想是精确匹配,比如主要通过关键词索引自然语言,通过 CV 模型标签索引图像视频,但这种搜索途径难以覆盖完整的内容。而 DNN 驱动的下一代信息检索,核心思想是语义相近,通过文本 embedding 模型、word2vec、text2vec 做自然语言处理,通过图像 embedding、视频 embedding、CNN 做图像视频处理,整体而言通过向量数据库和近似近邻搜索,目的是找到语义上最接近的候选者,而不是精确匹配,其中语义被定义为向量相似。
王翔宇介绍了向量数据库 Milvus 及其云上服务的技术设计。目前 Milvus 已迭代至 2.0 版本,是一款云原生分布式向量数据库。Milvus 2.0 基于 K8s 进行微服务化设计,可实现高可用容灾;存储计算分离设计;离在线一体化。同时还具备超高的性能,查询速度高于 ES 10 倍,高于主流竞品 2 倍;毫秒级延迟响应;查询性能根据物理资源线性扩展。可插拔引擎支持向量与标量混合查询;提供标量倒排索引支持;集成了 FAISS、HNSW、DISKANN 等SOTA 向量索引。云端一体的设计提供从笔记本,到线下机房到云完全一致的使用体验,此外还有丰富的部署方式与可观测性支持。
目前,Milvus 已经被全球超过 1000家 企业用户所信赖,超过 700 万次下载和安装,最大库规模超过 20 亿条向量。
此外,基于开源向量数据库,Zilliz 还打造了云上全托管企业级向量检索服务 Zilliz Cloud,助力全球企业构建云上全托管向量检索服务。基于 Zilliz 自研的向量检索引擎Cardinal,性能成本相比于开源提升 3X。同时,Zilliz Cloud 分为 SaaS 和 BYOC 两个版本,面向不同需求和不同部署环境。Zilliz Cloud 还提供大量企业级功能,助力用户聚焦业务逻辑,目前已经登陆 AWS,GCP , Azure 和阿里云。
Zilliz Cloud 还具备多个优点,如维护成本低,可一键创建实例资源、动态扩缩容、完善的监控报警、多云支持;用门槛低,具备免费实例、可视化界面、多语言 SDK、丰富的生态支持、数据迁移能力;此外还具备丰富的企业级特性,如 7 * 24 服务支持、99.9 SLA 保障;通过 RBAC 权限管理、TLS、白名单等提升安全性。
沙雨辰:知识增强领域大模型:原理与实践
网易杭州研究院人工智能算法专家沙雨辰发表了《知识增强领域大模型:原理与实践》主题演讲。沙雨辰对知识增强领域大模型的概念做了通俗解释。类似 ChatGPT 的通用大模型,通常认为对比到人身上可能是高中生的水平,因为其接受的通识教育。再往下,领域大模型可以看成是一位大学生,选择一个专精的研究方向深入学习。下一阶段则是企业员工,大学生在某一领域往往用的也是固定的相似教材,而进入企业之后便会接触到企业产品、技术、运营等个性化业务数据,这便对应了知识增强大模型。
通常以通用大模型为基座,通过 Prompt 优化,输入更多信息,提升效果。沙雨辰和其团队认为,在这个基础上,再叠加知识增强和领域大模型的训练,可以提升大模型的智能化解决率,最终达成软件智能化升级。
沙雨辰详细讨论了两个问题,第一,那么为什么要训练领域大模型?首先是专业方面,通用大模型虽然具备涌现能力,但对差异性大的行业理解还是存在局限性,似懂非懂。此外每个领域都有大量未公开的行业数据,通用大模型难以满足垂直领域需求,容易形成数据孤岛。而垂类应用是大模型落地主战场,专注于本领域数据和知识的领域大模型。其次,领域大模型使用成本更低,其参数规模通常在 20B 以下,部署成本在数万元的级别。最后,更安全稳定。较小规模的领域大模型,低成本私有化部署,可将该风险降至零。同时垂直领域模型,可训练其回答特定的内容,可在一定程度上缓解幻觉风险。
第二个问题是知识增强技术到底是什么?知识增强技术可以理解成是给大模型外挂知识库。未联网的 ChatGPT 等大模型全靠模型记忆知识,缺陷在于新的知识学不到,更新模型成本高,以及事实型内容容易乱编。而知识增强技术的优势在于其可解释性、可减少幻觉以及低成本人工干预。
通过领域大模型可以做到知识内化,再结合知识增强技术实现知识外挂,二者结合便是网易【杭研】人工智能研究院现下的知识增强领域大模型技术路线。目前也已经有了一些落地应用,如智能数据分析 有数ChatBI 【产品】实现了【对话式智能取数】,门槛更低效率更优。
张家庆:如何打造基于开源大模型的核心竞争力
OpenCSG 联合创始人兼 CMO 张家庆发表了《如何打造基于开源大模型的核心竞争力》的主题演讲,主要从商业化和技术两方面讲述了如何看待大模型市场、如何找到自己的核心竞争力去做一家公司并获得成功。
张家庆指出,从去年起,大模型市场的热度不断攀升,结合了开源模型、数据使用权和场景的商业机会丰富地涌现,大模型也逐渐从技术驱动转变为业务需求驱动。张家庆认为,通过云服务中小企业、为政府保障数据安全这两大方向,在接下来都有广大的市场,关键就看如何跟场景结合。另外,从做软件开发的经验来看,由于大模型本身的交互方式发生了变化,在软件开发的流程方面也会发生很大的变革。如今,大模型已逐渐向开源倾斜,也给大模型创业提供了更多机会。
而目前的大模型市场,主要存在4大问题:需求确认和沟通繁琐,业务难和大模型结合,大模型安全风险,缺乏端到端解决方案。如果能够有效解决这些问题,那么将能获得许多创业机会。
张家庆认为,未来每家公司都将拥有自己的模型、自己的机器学习能力。届时,开源大模型生态会被迅速激活,业态百花齐放,但是马太效应也会更明显,排名前1%的模型会拥有99%的下载量。同时,迭代的速度也会非常快,真正拉开差距的,将会是数据,优质数据集和数据科学团队价值凸显,也决定了训练出来的模型是否具备真正的商业价值。
张家庆所在的 OpenCSG 的核心理念为开放 AI 基础设施、应用、模型。作为平台建设方,OpenCSG 通过通过 OpenCommunity 社区平台,提供了模型数据集管理平台 LLM 应用框架 Galaxy Hub、StarChain,帮助用户构建更好的大模型应用。最后张家庆也分享了几个关于大模型创业的 tips:开源模型不需要变得更好,只需要变得更小和更专用;数据决定了训练出来的模型是否具备真正的商业价值;如果开源模型能够在轻量级的同时保持高质量,这就是未来市场的机会所在。
谢亚东:从模型到服务:如何高效率部署模型
Lepton AI Founding Member 谢亚东发表了《从模型到服务:如何高效率部署模型》主题演讲。模型部署是让模型从实验环境走向生产服务的重要一环。谢亚东认为,AI 的供给不断增加,从业者对 AI 的需求也在增长,越来越多非 AI 从业人员也会加入使用 AI 的行列。但 API 逐渐已不能满足人们的需求,那么,如何快速把一个模型,变成一个 API ?怎么把模型 serving 起来?
谢亚东讲述了谷歌的常规 architecture,一个机器模型上线的过程:数据抽取、数据准备、模型训练、模型评估和验证,最后训练模型。但如果只是要做一个 POC,完全可以跳开前面的步骤,直接找到线上的模型,把它 serving 起来,做成 API 和 Application,快速测试其热度。如果不火,则接着测试下一个。
如今,模型的提供商和开源模型的火爆,已使这件事变为可能。
谢亚东认为,在 AI 领域创业,就是一件比速度的事情。API 虽好,但还不够。一方面,API 发布的时间太慢,等到做成应用上线,热度早就过了;其次,如果真的想要做一款 AI 产品,需要的模型是非常多样的,因为不同的模型有不同的特性,有可能还得自己定制。开源大模型更新迭代很快,商业公司发布 API 的速度跟不上,如果是大公司,还会有安全顾虑,不希望泄露数据给商业卖家。那么如何跟上步伐,就成了最关键的事。
随后,谢亚东以 Lepton AI 和 Gpt2 为例,现场演示了如何用开源模型制作一个 model。只需要5分钟,就能在本机写出一个 service,调试好一个开源模型,并快速地把它发布到线上。这就是 Lepton AI 的云端服务。
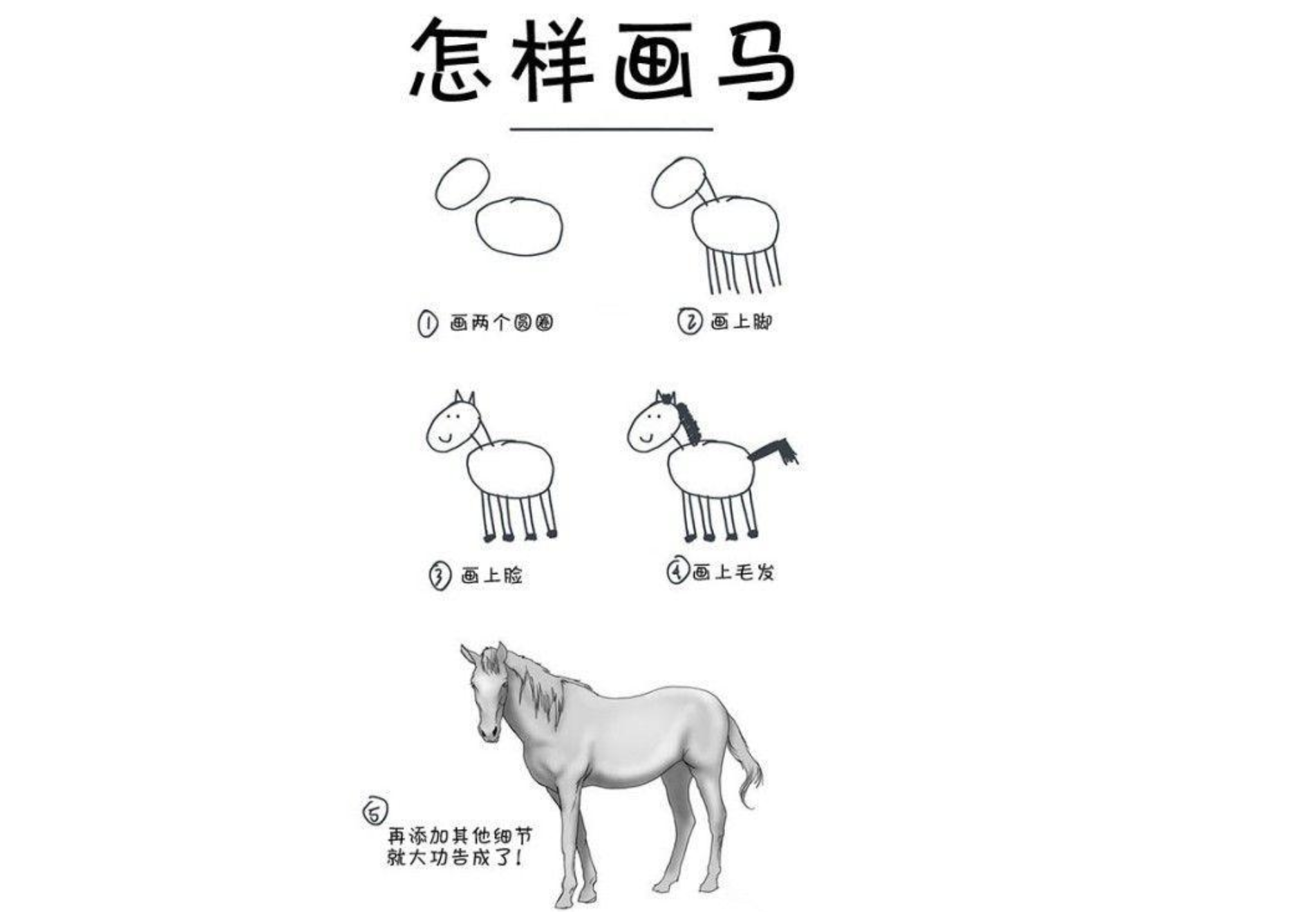
最后,谢亚东演示了刚刚自己写的开源项目:ImgPilot。之前,大家画马是按照这样的步骤:
![]()
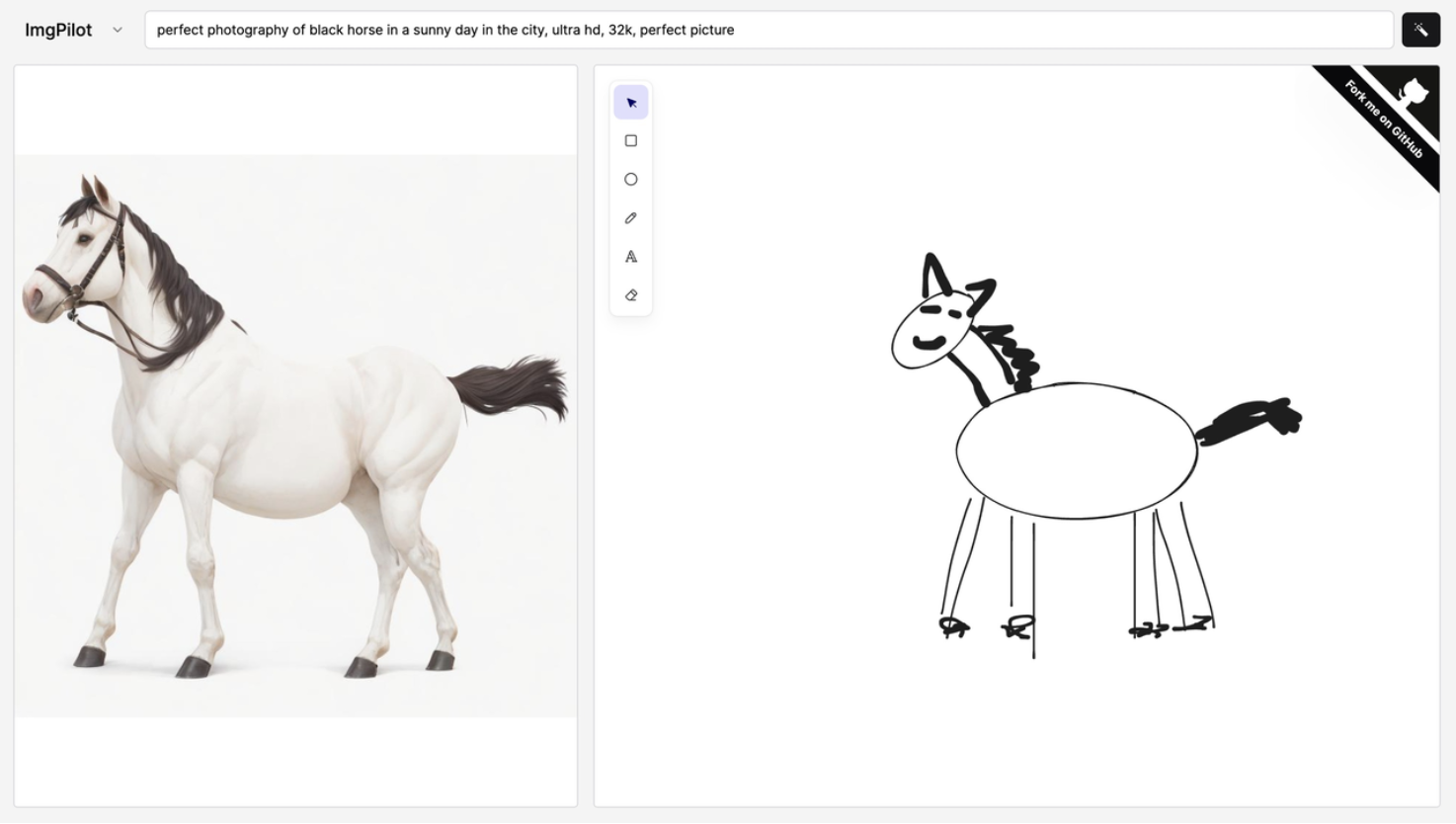
但现在,在这个项目里面,真的只需要画个简笔画,就能实现栩栩如生的马图了。谢亚东按照上图的步骤,只在右边的画布上画了寥寥几笔的圆形、三角组成的“马”,AI 就能自动在左边渲染出想要的真●马图,甚至还能随着笔画的变化自动变换样式,供你选择。
![]()
谢亚东认为,未来,每个人都有可能成为 AI Application 开发者,在这个过程中,model 的 serving 会变得非常重要,如何把一个模型用最短的时间变成 API,这可以成为后续业务和开发的重点。
彭博:如何在本地做“简单”的模型微调
Gitee AI 产品负责人彭博发表了《如何在本地做“简单”的模型微调》的主题分享。
目前,本地模型微调面临着很多难题,从配置 Python 源、获取模型和数据集,到本地运行、编写脚本、微调模型、集成到产品,都遇到了或硬件或软件的阻碍。
对此,彭博介绍了 Gitee 推出的应用和案例。在 Gitee 企业版上有个任务管理功能,积累了许多历史任务的数据,如今如果要新建任务,就可以利用大模型进行分析推荐,帮助决策。如:这个任务谁来负责比较好?
彭博选择了一种文本分类的模型 Bert 进行演示,从配置 Python 源、加载数据集、训练模型,到评估结果的全过程。与本地训练相比,Hugging Face 准确度更高,成本也更低,耗时也短。训练好之后,用一个任务进行测试,结果推荐的人选,也很符合彭博的印象。模型最后不仅能列出该人选的准确率,还能给出选择的理由,作为辅助决策是成功的。
Gitee AI 也在做跟 Hugging Face 一样的事情,期望能给国内的开发者扫除使用模型的障碍,降低使用 AI 的成本,未来也会推出对标的产品。主要分三类:一是模型引擎,二是应用引擎,三是训练引擎。其中,模型引擎对应 Hugging Face 的 Inference API 和 Inference Endpoints,覆盖测试和生产的模型推理部署。应用引擎将辅助做 Demo 做演示。训练引擎将基于应用引擎提供模型微调能力。未来,Gitee AI 还会考虑做 web 版本的 AI 开发环境,供大家测试和使用。
目前,Gitee AI 已同步了 Hugging Face 最受欢迎、下载量最多的几千个模型和数据集,并提供了对 huggingface_hub API 的基础适配,能兼容模型和数据集的下载。应用引擎可以让用户轻松的运行 AI 应用 Demo 以及进行模型微调。
![]()
11 月源创会到此就结束啦,小伙伴们下期见!