![]()
作者 | 刘俊启
导读
在软件开发中,经常会遇到一些代码问题,例如逻辑结构复杂、依赖关系混乱、代码冗余、不易读懂的命名等。这些问题可能导致代码的可维护性下降,增加维护成本,同时也会影响到开发效率。这时通常通过重构的方式对已有代码结构进行改进和优化。在重构的工作中,大部分的工作是人工的方式完成,是一个耗时且容易出错的过程。对于研发人员来讲,在不改变软件的功能和行为的前提下,保证质量和效率完成对已有功能的重构,是一个极大的挑战。本系列以Python实现自动化的工具,支持代码重构过程的实践。
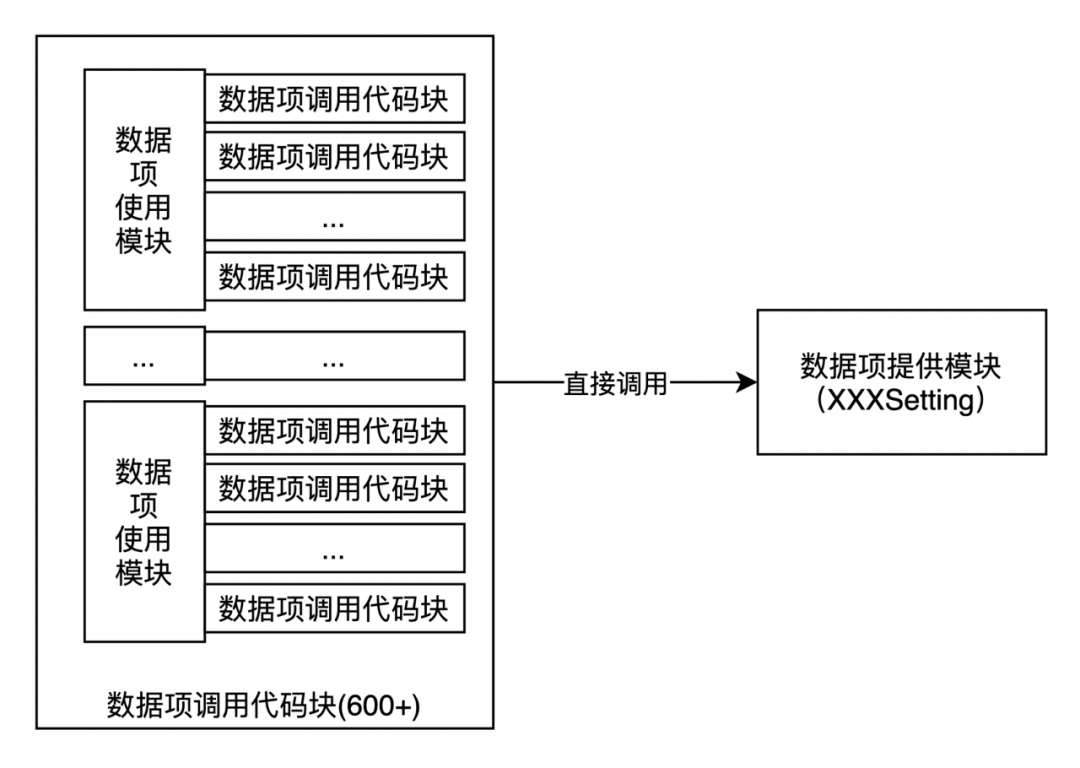
在第一篇《通过Python脚本支持OC代码重构实践(一):模块调用关系分析》的内容中,介绍了使用Python实现模块调用关系的分析,确定了调用数据项的代码块超过了600处,如图-1所示,这些调用点分布在不同的组件中,是直接调用的关系。
![图片]()
△图-1
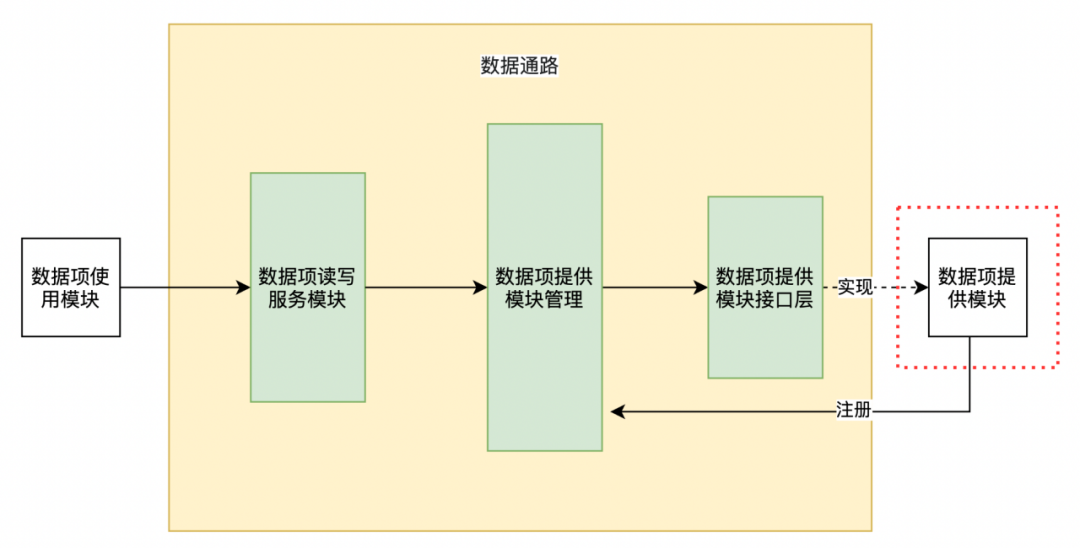
在第二篇《通过Python脚本支持OC代码重构实践(二):数据项提供模块接入数据通路的代码生成》的内容中,重点介绍了使用Python实现了数据项提供模块接入数据通路时,公开数据项相关的代码生成(图-2中的红框部分),这时数据项读写由原来的直接读写方式改为通过数据通路的间接读写方式。
![图片]()
△图-2
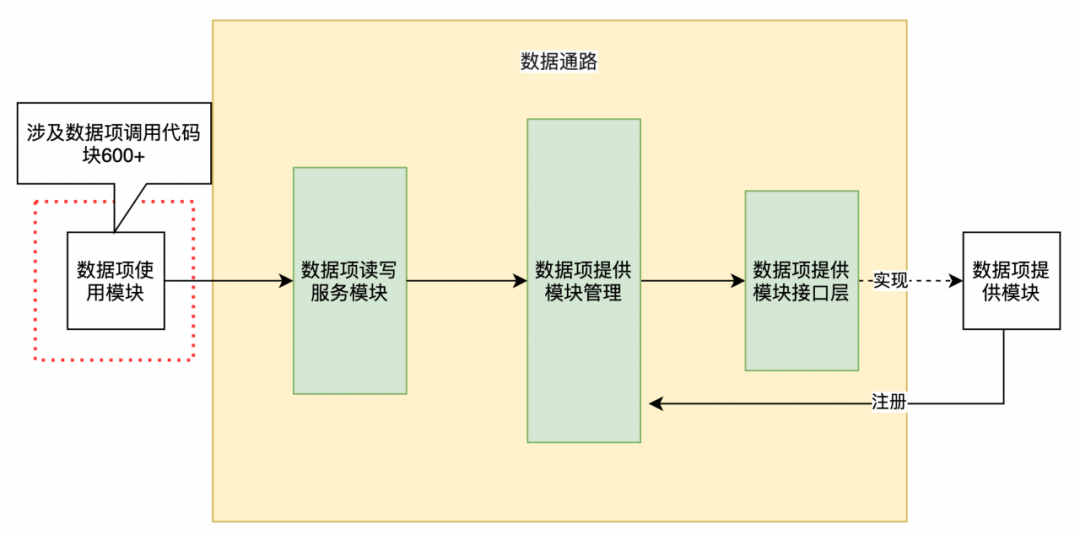
当数据项提供模块接入到数据通路后,数据项使用模块需要进行重构,以符合数据通路的标准。重构涉及到600多处调用代码段的适配(图-3中的红框部分),手工重构方式成本高、出错概率高,并且在测试时需要逐项验证,成本也很高。为了解决这个问题,我们使用Python脚本实现了与数据通路的通讯代码的生成,可自动的为每个数据项封装读写函数,和自动将原有的代码调用替换为升级后的代码调用,支持不同数据项的升级。这样做实现了本次重构工作在测试及上线阶段零 Bug。
![图片]()
△图-3
本篇内容阐述如何利用Python编写的自动化工具,实现将原数据项使用模块中直接对数据项提供模块中数据项的读写方式,升级为通过数据通路间接读写。包括每个数据项读写类的封装和数据项使用模块的调用代码段适配。
01 数据项读写类封装
为了降低数据项的读写调用代码的重构成本,在数据项使用模块中创建一个封装类。每个数据项的读写创建一个静态函数来实现,可被数据项使用模块中的数据项读写类使用。由于需要使用Python脚本实现工具,因此需要有明确的生成规则,以便工具的实现。规则如下:
1、数据项的读取操作,函数返回类型,函数名,均与与数据项相同。
- 如:NSString *value1; 需要转为 +(NSString *)value1,包含函数定义及实现。
2、数据项的更新操作,set_ + 函数名:数据类型,均与数据项相同。
- 如:NSString *value1; 需要转为 +(void)set_value1:(NSString *)value,包含函数定义及实现。注意:参数名均为value
1.1 数据项读取能力封装
基于数据项读取操作生成规则,分别实现函数头、函数声明、函数体,分别输出至.m和.h文件。
# 原代码行示例 NSString value1;
matchObj = re.match(r"(.*)\s+(.*);", line, re.M|re.I)
if matchObj:
valuetype = matchObj.group(1)
valuename = matchObj.group(2)
# 因不同类型修饰的方式不同,在getReadFunReturnType进行类型映射;如NSString :NSString *
funname = '+ (' + getReadFunReturnType(valuetype) + ')' + valuename
# 函数声明 .h文件 + (NSString *)value1;\n\n
hfunname = funname + ';\n\n'
# 函数定义 .m文件 + (NSString *)value1 {\n
mfunname = funname + ' {\n'
- 函数体示例,每个数据项跟据key与数据通路通信,读取数据项
# 定义返回类型的变量,并赋值,代码行为
# funbody为: NSString *res = [DataChannelReaderxxx
funbody = ' ' + getReadFunReturnValueType(valuetype) + 'res = [DataChannelReaderxxx '
# 不同类型的数据,数据通路提供的读取的函数不同,由getReadFunName函数中映射,如:NSString :stringForKey
# funbody 为 NSString *res = [DataChannelReaderxxx stringForKey:@"
funbody += getReadFunName(valuetype) + ':@\"'
# key,类名_数据项名 className_value1
key = className + '_' + valuename
# funbody 为 NSString *res = [DataChannelReaderxxx stringForKey:@"className_value1"];\n
funbody += key + '\"];\n'
# 函数实现完成
funbody += ' return res;\n}\n\n'
# 函数数头 .m文件
file_data += mfunname
# 函数体 .m文件
file_data += funbody
# 函数定义 .h文件
hfile_data += hfunname
- 文件生成:默认以XXXSettingReader作为文件名及类名作为前辍,XXX为使用方模块名称,这样就比较清楚,是那个模块中的数据项读取能力封装。
1.2 数据项更新能力封装
基于数据项更新操作生成规则,分别实现函数头、函数体,及.m和.h文件
# 原代码行示例 NSString value1;
matchObj = re.match(r"(.*)\s+(.*);", line, re.M|re.I)
if matchObj:
valuename = matchObj.group(2)
valuetype = matchObj.group(1)
# funname为: + (void)set_value1
funname = '+ (void)set_' + valuename
# 因不同类型修饰的方式不同,在getValueType进行类型映射;如NSString :NSString *
# funname为:+ (void)set_value1:(NSString *)value
funname += ':(' + getValueType(valuetype) + ')value'
# 函数声明 .h文件 + (void)set_value1:(NSString *)value;\n\n
hfunname = funname + ';\n\n'
# 函数定义 .m文件 + (void)set_value1:(NSString *)value {\n
mfunname = funname + ' {\n'
- 函数体示例,每个数据项跟据key与数据通路通信,更新数据项
# 不同类型的数据,数据通路提供的更新的函数不同,在getUpdateFunName函数中映射,如:NSString :updateString
# funbody 为 [DataChannelWriterxxx updateString:value
funbody = ' [DataChannelWriterxxx ' + getUpdateFunName(valuetype) + ':value '
# key,类名_数据项名 className_value1
key = className + '_' + valuename
# funbody 为 [DataChannelWriterxxx updateString:value forKey:@"className_value1"];\n
funbody += 'forKey:@\"' + key + '\"];\n'
# 函数实现完成
funbody += ' }\n\n'
# 函数数头 .m文件
file_data += mfunname
# 函数体 .m文件
file_data += funbody
# 函数定义 .h文件
hfile_data += hfunname
- 文件生成:默认以XXXSettingWriter作为文件名及类名作为前辍,XXX为使用方模块名称,这样就比较清楚,是那个模块中的数据项更新能力封装。
02 数据项使用模块调用代码段适配
当数据提供模块通过数据通路支持数据项的读写,在数据项使用模块中也需要进行适配。原直接使用数据项,改为使用数据项读写类,这部分的代码使用自动化方式完成。分为两类,数据项更新调用代码段适配和数据项读取调用代码段适配,因数据项更新和数据项读取代码段前辍相似,先执行更新后执行读取。
2.1 数据项更新调用代码段适配
2.1.1 代码转换OC代码示例
数据项读取的更改的主要思路为字符串匹配,查找替换。依次的拼装每个数据项字串,再替换成每个数据项升级之后的写法,如:
[XXXSetting share].value1 = @"str" => [XXXSettingWriter set_value1:@"str"]
2.1.2 关键的代码实现
# 定义个全局的字典
allwritepubvalue = {}
# 原代码行示例 NSString value1;
matchObj = re.match(r"(.*)\s+(.*);", line, re.M|re.I)
if matchObj:
# valuename = value1
valuename = matchObj.group(2)
# key = [XXXSetting share].value1
key = '[XXXSetting share].' + valuename
# value = SettingWriter set_value1:,不同的模块前面加上[XXX ,后面加运算符右侧
value = ' XXXSettingWriter set_' + valuename + ':'
# 赋值 key = [XXXSetting share].value1,value = SettingWriter set_value1:
allwritepubvalue[key] = value
# 获取当前工程中,所有源码文件及对应的组件名
allfileandlib = {}
# allpubvalue 全局变量,字典
for key, value in allwritepubvalue.items():
# filename为文件名,libname为组件名
for filename, libname in allfileandlib.items():
# 当libname为XXX replacevalue = [XXXSettingWriter set_value1:
replacevalue = '[' + libname + value
# 实现个函数 重写这个文件 将文件中 [XXXSetting share].value1 = YYY 替换为 [XXXSettingReader set_value1:YYY]
reWriteFile(filename, key, replacevalue)
- 文件重写函数实现,需要实现全字的匹配,避免数据中存在相互为子串的情况。
# 定义一个输出的数据,初始为空字串
outfiledata = ''
# 使用正则全字匹配,查找替换
regAbKey = fromstr.replace('[', '\[')
regAbKey = regAbKey.replace(']', '\]')
regAbKey = regAbKey.replace('.', '\.')
# pattern 为 .*\[XXXSetting share\]\.value1\s*=\s*([a-zA-Z0-9_\[\]\s\.]+),为了匹配赋值字串,但没有考虑运算符右侧有运算符的情况
pattern = r'.*' + regAbKey + '\s*=\s*([a-zA-Z0-9_\[\]\s\.]+)'
# 依次从文件中读,正则全字查找及规换
for line in f:
matchObj = re.match(pattern, line, re.M|re.I)
if matchObj:
# 代码中真实的写法,去掉前面的一些代码,比如 [XXXSetting share].value1 = YYY,变为[XXXSetting share].value1 = YYY
eqcode = re.sub(r'.*' + regAbKey, fromstr, matchObj.group())
# 如原代码为 [XXXSetting share].value1 = YYY ,则 matchObj.group(1) 为YYY
# 把 [XXXSetting share].value1 = YYY 替换为 [XXXSettingWriter set_value1:YYY]
newline = line.replace(eqcode, tosrt + matchObj.group(1) +']')
outfiledata += newline
2.2 数据项读取调用代码段适配
2.2.1 代码转换OC代码示例
数据项读取的更改的主要思路为字符串匹配,查找替换。依次的拼装每个数据项字串,再替换成每个数据项升级之后的写法,如:
[XXXSetting share].value1 => [XXXSettingReader value1]
2.2.2 关键的代码实现
# 定义个全局的字典
allreadpubvalue = {}
# 原代码行 NSString value1; 4.1生成的类型及变量名
matchObj = re.match(r"(.*)\s+(.*);", line, re.M|re.I)
if matchObj:
# valuename = value1
valuename = matchObj.group(2)
# key = [XXXSetting share].value1
key = '[XXXSetting share].' + valuename
# value = SettingReader value1] ,不同的模块再加上[XXX
value = 'SettingReader ' + valuename + ']'
# 赋值 key = [XXXSetting share].value1,value = SettingReader value1]
allreadpubvalue[key] = value
# 获取当前工程中,所有源码文件及对应的组件名
allfileandlib = {}
# allpubvalue 全局变量,字典
for key, value in allreadpubvalue.items():
# filename为文件名,libname为组件名
for filename, libname in allfileandlib.items():
# 当libname为XXX replacevalue = [XXXSettingReader value1]
replacevalue = '[' + libname + value
# 实现个函数 重写这个文件 将文件中 [XXXSetting share].value1 替换为 [XXXSettingReader value1]
reWriteFile(filename, key, replacevalue)
- 文件重写函数实现,需要实现全字的匹配,避免数据中存在相互为子串的情况。
# 定义一个输出的数据,初始为空字串
outfiledata = ''
# 使用正则全字匹配,查找替换
regAbKey = fromstr.replace('[', '\[')
regAbKey = regAbKey.replace(']', '\]')
regAbKey = regAbKey.replace('.', '\.')
# \[XXXSetting share\]\.value1\b
pattern = r'' + fromstr + r'\b'
# 依次从文件中读,正则全字查找及替换
for line in f:
newline = re.sub(pattern, tosrt , line)
outfiledata += newline
03 小结
本篇是本系列的最后一篇,在本系列第一篇内容中介绍了通过Python脚本实现公开接口及调用关系的分析,用来支持重构工作量及影响面的评估。在第二扩篇内容中,介绍了通过Python脚本实现数据项提供模块接入数据通路的代码转换。
本篇内容介绍使用 Python 编写自动化工具,实现了将原数据项使用模块中直接对数据项提供模块中数据项的读写方式,升级为通过数据通路间接读写。包括每个数据项读写类的封装和数据项使用模块的调用代码段适配。通过封装每个数据项的读写类,并为每个数据项封装了独立的读写函数,和对原有调用代码的自动替换,这些工作是IDE提供的相关工具不可支持及定制的,基于Python编写的自动化工具,降低了重构成本,并在测试及上线阶段实现了零 Bug。
欢迎加入百度搜索大前端团队,持续招聘 iOS/Android/Web前端 研发工程师。简历欢迎投递至joinefe@baidu.com
——END——
推荐阅读
百度搜索深度学习模型业务及优化实践
文生图大型实践:揭秘百度搜索AIGC绘画工具的背后故事!
大模型在代码缺陷检测领域的应用实践
通过Python脚本支持OC代码重构实践(二):数据项提供模块接入数据通路的代码生成
对话InfoQ,聊聊百度开源高性能检索引擎 Puck