前言
趁着双十一备战封板,终于又有一些时间可以梳理一下最近的心得。
最近这半年跟同事讨论比较多的是分层架构,然后就会遇到两个触及灵魂的问题,一个是如何做好分层架构,二是DDD在架构层面该如何落地。
为了说好分层,我们需要了解架构的意义。
良好的架构是为了保证一下两点:
- 治理应用复杂度,降低系统熵值;
- 从随心所欲的混乱状态,走向井井有条的有序状态。
比如,你去图书馆借阅书籍,对于纷繁杂乱的各类书籍,如果不能很好的管理和分类,必然会导致图书馆管理混乱,效率低下,使得图书馆不能正常运维。而分层架构的意义也在于此,当我们面对复杂的业务需求时,需要更好的规划我们的包结构和依赖规约,可以更好的治理我们的服务,提升服务的可维护性,可扩展性,做到我们的架构以业务为核心,解耦外部依赖,分离业务复杂度和技术复杂度。
传统分层架构有MVC,而这些年流行的六边形架构,也是伴随着DDD的兴起而逐步被大家所接受。如果说DDD和六边形架构的关系,他俩属于不同层级的概念,DDD更偏向方法论,注重领域建模和业务逻辑的设计,强调将业务需求和领域知识转化为软件设计;而六边形架构更注重系统的整体架构和模块化设计,强调分离内部和外部系统的交互。他们俩的结合是一种非常好的实践经验, DDD中的领域模型是核心,其他层(如应用层、基础设施层)依赖于领域模型;而六边形架构正好为DDD提供了一种非常好的分层落地。
浅聊DDD落地
对于DDD,并没有一种所谓的框架或者脚手架能够对应,其根本原因在于,DDD其实是一种方法论,而非所谓的框架,它给我们提供了一种应对业务复杂度时的方法:
- 通过架构设计来分离业务复杂度和技术复杂度;
- 通过限界上下文去做到分而治之,将大系统拆解为若干个高内聚低耦合的子域;
- 通过面向对象的设计模式,将业务子域的知识进行抽象。
总结一下:
- DDD的战略建模注重子域的划分和限界上下文的定义。对应到落地就是包的拆解, 以及包之间的依赖和组合关系。
- 而DDD的战术建模主要关注的是构造块和柔性设计。构造块就是我们常说的,类,对象,组合。而柔性设计就是我们面向对象的设计原则,得到一个高内聚低耦合的系统。所以说,DDD的战术建模落地,一定伴随着开发人员对设计模式的深刻理解和应用。
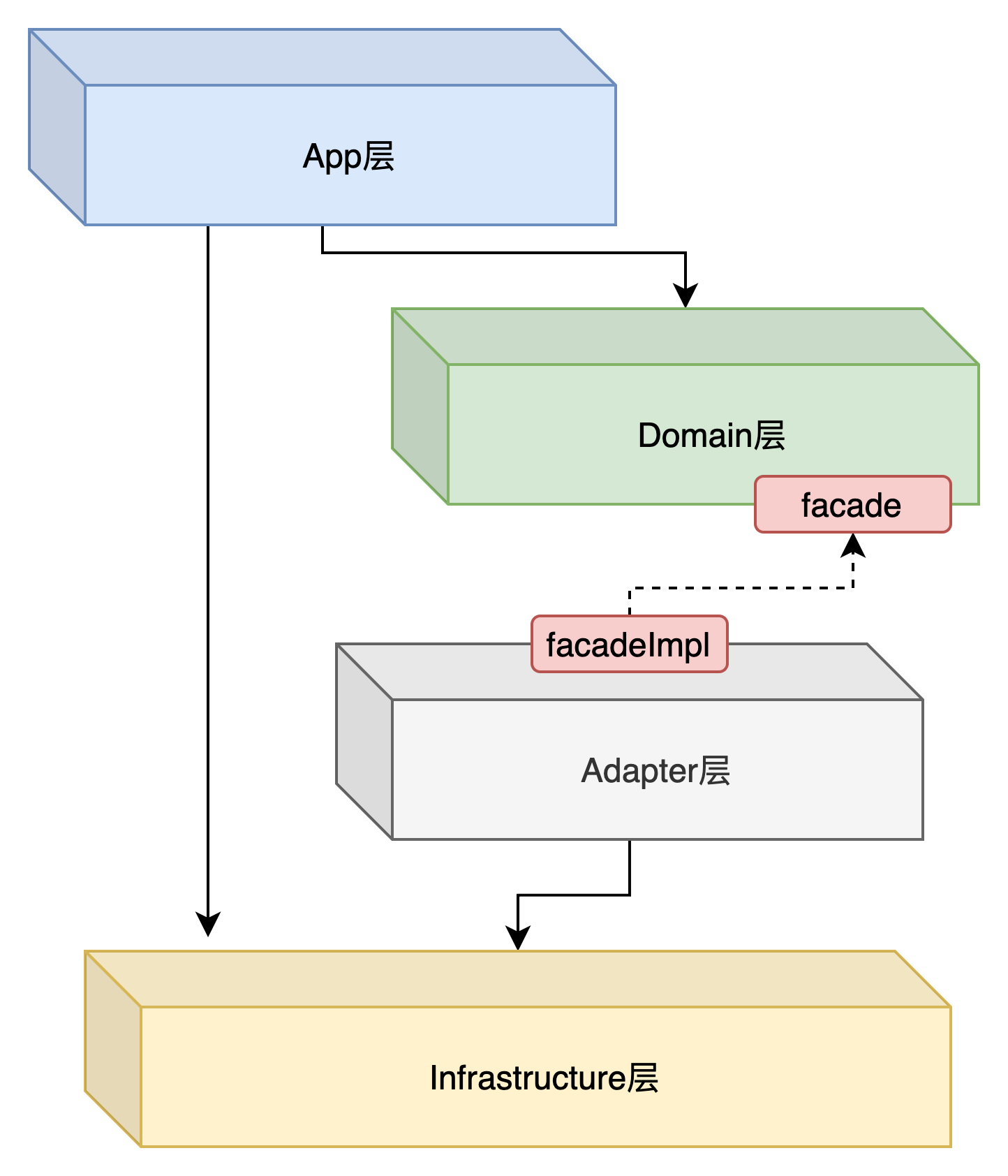
六边形分层架构
1. App层
应用层是DDD中的顶层,负责协调和组织领域对象的交互。它接收来自用户界面或外部系统的请求,并将其转发给领域层进行处理。应用层负责定义应用的用例(Use Cases),处理事务边界和协调领域对象的操作。它不包含业务逻辑,而是将请求转化为领域对象的操作。应用层还可以包含获取输入,组装上下文,参数校验,异常定义,发送事件通知等。
2. Domain层
主要是封装了核心业务逻辑,并通过领域服务(Domain Service)和领域对象(Domain Entity)的方法对App层提供业务实体和业务逻辑计算。领域是应用的核心,不依赖任何其他层次。同时领域层会有一个facade层,当领域服务对外部有调用依赖时,通过定义facade接口实现控制反转。
3. Adapter层
负责与外部系统进行或者服务进行适配和集成,包括通信,数据缓存,接口适配等功能。
此外强调, RPC consumer调用放在适配器层。适配器层专注于与外部系统的集成和适配,将外部系统的接口和数据格式转换为应用程序可以理解和处理的形式。将RPC调用放在适配器层可以更好地将与外部系统相关的技术细节与应用程序的业务逻辑和领域对象进行解耦,提高应用程序的可扩展性和可维护性。
对于所有出站适配层,都需要通过实现facade接口实现控制反转。
4. 基础设施层
负责提供支持应用程序运行的基础设施,包括与具体技术相关的实现。基础设施层通常包括与数据库、消息队列、缓存、外部服务等进行交互的代码,以及一些通用的工具类和配置,也包括filter等实现。
基础设施层和适配器层之间的关系是:
- 基础设施层提供了与具体技术相关的实现,例如数据库访问、消息队列连接、缓存操作等。适配器层可以使用基础设施层提供的功能来与外部系统进行交互。
- 适配器层通过适配器模式或类似的机制,将外部系统的接口和数据格式转换为应用程序可以理解和处理的形式。适配器层还负责将应用程序的请求转发给基础设施层进行具体的操作。
- 基础设施层和适配器层一起工作,使得应用程序能够与外部系统进行集成,并且将与外部系统相关的技术细节与应用程序的业务逻辑和领域对象进行解耦。这样可以实现应用程序的可扩展性、可维护性和可测试性。
对于一些无复杂逻辑的,也可以直接让上游掉基础设施层,不必一定通过Adapter层。
脚手架的落地实践
以上主要是理论介绍,基于以上的说明,在实践中,我搭建了两套分层架构的java脚手架。具体来说分为单module版本和多module版本。对于微服务系统来说,如果你的每个服务业务复杂度不高,建议使用单module版本;如果你是个复杂业务场景的单体应用,建议采用多module版本。
1. 单module脚手架
--root
--application: 应用层是程序的入口,整合和组合domain提供的能力。
--rpc: JSF provider对外提供的接口实现
--controller: springMVC提供的controller
--listener: MQ消息监听器
--task: 调度任务
--translate: 将内部的BO映射为外部的VO/Entity
--model: VO对象
--adapter: 适配器层
--rpc: JSF consumer,外部服务
--mq: 消息队列sender模块
--translate: 将外部数据结构映射为内部的DTO/BO
--domain: 领域层
--service: 领域服务可以按照自己情况灵活设计
--facotry: 工厂
--event/command: 事件驱动
--model: 对象和实体
--translate: 对象实体映射转换
--infrastructure:
--repository: 持久化层,包括db模型,sql读写等
--cache: Redis缓存读写
--producer: MQ消息生成,即发送MQ消息。
--config: 配置信息,例如ducc配置、数据库、缓存配置等
--translate: 将存储层的数据结构PO映射为内部的BO
--utils: 工具集合
--common: 公共层
--exception: 主要分为业务异常和系统异常。系统异常需要研发处理。业务异常需要具备监控能力。
--utils: 工具类
--enums: 枚举类
--common: 全局公共常量池
--worker: 异步服务
--client: JSF SDK
maven私服拉取脚本如下:
单module版本maven私服拉取脚本如下:
mvn archetype:generate \
-DarchetypeGroupId=com.jd.magnus \
-DarchetypeArtifactId=magnus-single-archetype \
-DarchetypeVersion=1.0.0-SNAPSHOT \
-DinteractiveMode=false \
-DarchetypeCatalog=remote \
-Dversion=1.0.0-SNAPSHOT \
-DgroupId=com.jdl.sps \
-DartifactId=bff-single-demo1
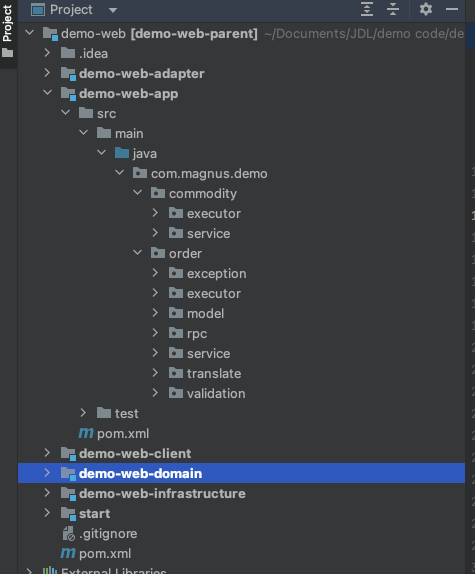
2. 多module脚手架
此处有一个建议,在多module版本下,因为是复杂单体应用,所以建议内部进行拆包处理。每层内也可以基于不同领域场景也可以进行拆包操作,每个场景下层级结构是一样的。如下图举例,其中app层中分别有两个业务场景,包括商品和订单:
多module版本的maven私服拉取脚本如下:
mvn archetype:generate \
-DarchetypeGroupId=com.jd.magnus \
-DarchetypeArtifactId=magnus-multi-ddd-archetype \
-DarchetypeVersion=1.0.0-SNAPSHOT \
-DinteractiveMode=false \
-DarchetypeCatalog=remote \
-Dversion=1.0.0-SNAPSHOT \
-DgroupId=com.jdl.sps \
-DartifactId=bff-demo1
小结
本框架是结合了DDD思想和六边形架构思想,但脚手架不会限制大家能力和发挥。
如果你精通DDD,你可以在domain层采用标准的充血模型和子域拆分模式编写你的代码; 如果你精通MVC,该框架也可以简化为大家熟悉的MVC开发模式。对于model的处理,也可灵活应对,在不影响整体代码架构的情况下,允许不过度设计及对象多度封装,鼓励敏捷迭代和定期重构。
但有一个核心思想需要谨记:
我们尽量保证我们的代码开发符合开闭原则,能够通过增加类和方法的方式实现新功能迭代,尽量就要避免频繁修改某个方法或者某个类,包与包之间要保证高内聚,低耦合。因为DDD思想的核心就是子域的拆分和对设计模式的合理运用。
作者:京东物流 赵勇萍
来源:京东云开发者社区 自猿其说 Tech 转载请注明来源