大家好,我是冰河~~
经过四个多月的坚持,《Seckill秒杀系统》终于接近尾声了,也感谢大家这四个多月以来的坚持和陪伴,也相信大家在《Seckill秒杀系统》专栏中,学到了不少知识和技术。接下来,我们就一起对《Seckill秒杀系统》专栏做个总结。
一、总体概述
在《Seckill秒杀系统》专栏中,不仅仅是带着大家从零开始写一个秒杀业务系统,而是从需求立项到架构设计、环境搭建到编码实现、问题重现到代码优化、单体应用架构到微服务架构、秒杀系统极致优化到高并发方案落地、流量治理到链路追踪、防刷方案到风控设计、集群部署到全链路压测,再对秒杀系统整体进行极致优化。
上一章狠图(有点长,认真看,你会了解的更多)。
![]()
整个专栏共38个大的篇章,126+篇文章(每篇文章都会录制对应的视频课程),150+个源码分支,每篇文章都会对应一个源码分支,以便让大家更好的对应专栏文章、视频和小册进行学习和验证。
![]()
通过《Seckill秒杀系统》专栏,让大家从架构设计、编码实现、项目优化、流量治理、风控设计、项目部署、全链路压测、极致优化等多个层面真正掌握高并发、高性能、高可用、高可扩展和高可维护项目的架构设计与实际落地方案。
并且每一篇文章,都会为大家录制对应的视频课程,这样大家结合文章、视频、小册和源码进行学习,会起到事半功倍的效果。
![]()
试问:还有比根据专栏文章、视频、小册、源码学习更爽的事情吗?
二、核心技术
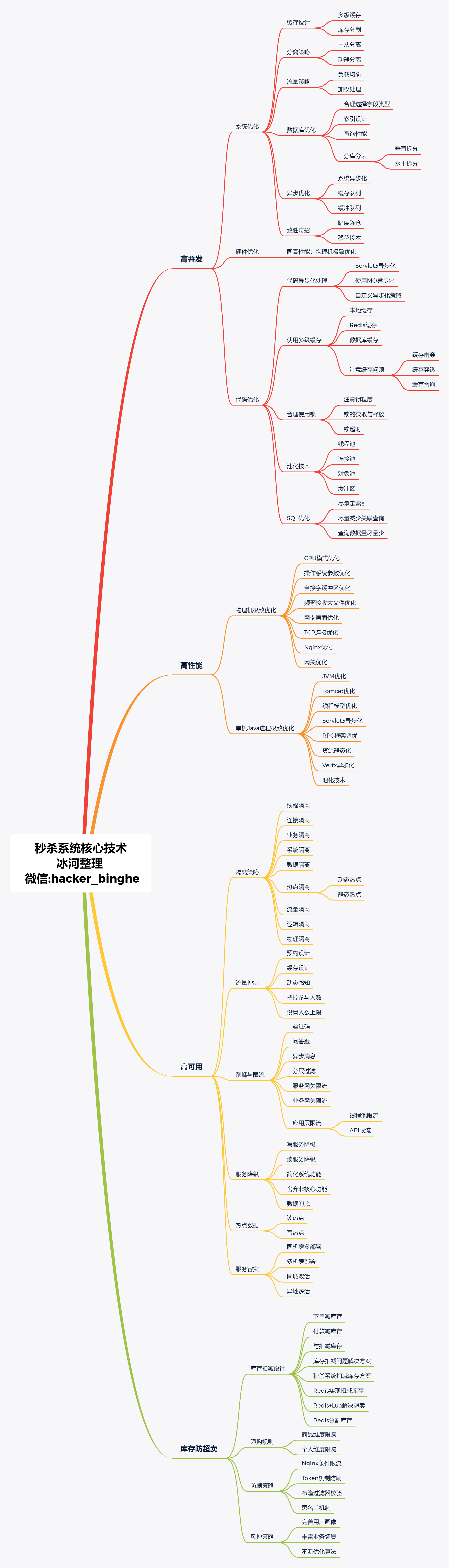
单就秒杀系统本身而言,就是为应对瞬时高并发、大流量场景而设计的支持高并发、大流量的系统,其背后会涉及到众多高并发、高性能、高可用的技术作为基础保障。同时,在系统中,也要重点突破库存与限购、防刷与风控、数据一致、热点隔离、动静分离、削峰填谷、数据兜底、限流与降级、流控与容灾、压测与极致优化等核心技术问题。
所以,冰河总结了秒杀系统所涉及到的最核心的技术内容,整理后如下图所示。
![]()
三、技术选型
在技术选型上,除了采用SpringBoot等基础框架外,也会采用容器化方案。为了尽量降低技术门槛,在整个秒杀系统的技术选型中,主要采用市面上比较主流的技术框架和方案,具体技术选型如下所示。
- 开发框架:SpringBoot、SpringCloud、SpringCloud Alibaba、Dubbo。
- 缓存:Redis分布式缓存+Guava本地缓存。
- 数据库:MySQL。
- 流量网关:OpenResty+Lua。
- 业务网关:SpringCloud Gateway。
- 持久层框架:MyBatis。
- 服务配置与注册发现:Nacos。
- 单机异步:Cola。
- 分布式事务:Hmily、Seata、RocketMQ。
- 分库分表:ShardingSphere。
- 日志治理:ELK(Elasticsearch、Logstash、Kibana)。
- 链路追踪:Sleuth、Zipkin、Prometheus。
- 容器:Docker。
- 容器化管理:Swarm、Portainer。
- 监控:Prometheus、Grafana。
- 系统限流:OpenResty+Lua、Sentinel。
- 消息中间件:RocketMQ。
- 单元测试:Junit。
- 压测工具:JMeter。
所以,通过秒杀系统,可以学习到微服务领域和DDD架构领域的主流核心技术。
四、适应人群
由于秒杀系统是从需求立项和用户故事开始,从零一步步搭建和开发,使用到的技术也是带着大家直接上手的。所以,整个专栏从小白到有一定开发经验的中高级工程师,有一定基础的架构师都可以学习。如果你当前或者长期受如下问题困扰,那你就更需要学习《Seckill秒杀系统》专栏了。
- 一直在小公司做CRUD,并发编程没接触过,更别提如何高并发实际项目了。
- 公司项目没什么并发,在线人数也不多,学了很多并发编程相关的知识不知道怎么用。
- 学了很多并发编程的知识,也知道一些概念,能说出一些简单的方案,但是没实际项目经验。
- 自我感觉掌握了一些高并发编程的技术方案,但是如果真正做项目时,还是不知道如何下手。
- 简历上写了熟悉并发编程,在面试过程中,面试官一般会问秒杀系统,或者其他高并发项目实战问题,不知道怎么回答。
- 在大厂工作多年,参与了一些系统的建设与研发,但是也没机会参与像秒杀系统这样高并发、大流量的系统的整个建设过程。
- 其他问题。。。
可以看到,如果小公司的小伙伴受限于业务,接触不到高并发、大流量的业务场景,大厂的小伙伴由于某些原因没有被分到高并发、大流量业务部门。但更多的是大体掌握了并发编程的基础知识,而没有系统性落地成实际高并发项目的经验,这样的小伙伴更需要学习《Seckill秒杀系统》。
好了,今天就到这儿吧,我是冰河,我们下期见~~