在最近结束的VMware Explore 2023 拉斯维加斯大会上,VMware推出了新的 Private AI产品,以促进企业采用生成式人工智能并挖掘可信数据的价值。VMware 宣布了以下几点:
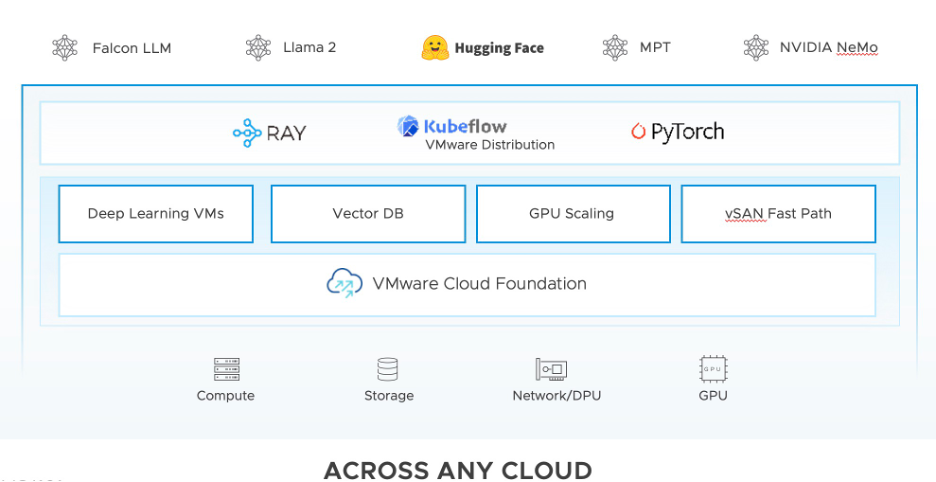
其中,VMware Private AI 开源参考架构(如下图所示)为客户和合作伙伴提供了灵活性,使他们能够:
-
利用最佳模型、框架、应用程序和数据服务、工具和适合其业务需求的硬件,基于标准化的VMware验证体系,实现快速、可重复、安全的部署。
-
通过利用完全记录的架构和相关代码示例以及通过消除系统设计、测试、启动、配置和供应过程中的复杂性,实现快速的交付价值。
-
在共同的本地云基础设施堆栈上运行所有AI工作负载,最大化资源利用率,从而提高投资回报率。
-
利用流行的开源项目,如 ray.io、Kubeflow、PyTorch、pgvector 以及Hugging Face 提供的模型。
![]()
Kubeflow专为在Kubernetes环境中进行机器学习工作而设计的开源机器学习平台,目前已被 CNCF 接受作为其孵化项目。它的主要功能如下:
-
提供一系列工具和组件,帮助用户更轻松地部署、管理和扩展机器学习工作负载。
-
帮助开发人员和数据科学家在容器化的环境中构建、训练和部署机器学习模型。
-
提供自动化的资源调度、监控和日志记录等功能,使机器学习任务更加高效和可管理性。
-
提供安全工作组、集成软件物料清单、基于Serviceaccount的身份验证、对大多数API进行身份验证以及加固lstio和网络策略等安全性特性。
许多 VMware 的客户已经在 vSphere 上投入了大量资源来运行关键应用程序,而如今他们希望将 vSphere 扩展为支持 AI/ML 工作负载,并都希望在他们的知识库上训练一个大语言模型。通过VMware提供经过优化的Kubeflow 发行版Kubeflow VMware Distribution,VMware客户可以充分利用经过验证的 VMware 技术栈,来解决这些挑战。这使得企业更容易在 vSphere 上安全地进行大规模的 Kubeflow 部署和管理,并且在值得信任的虚拟化基础之上高效地实现客户的AI/ML工作负载需求。
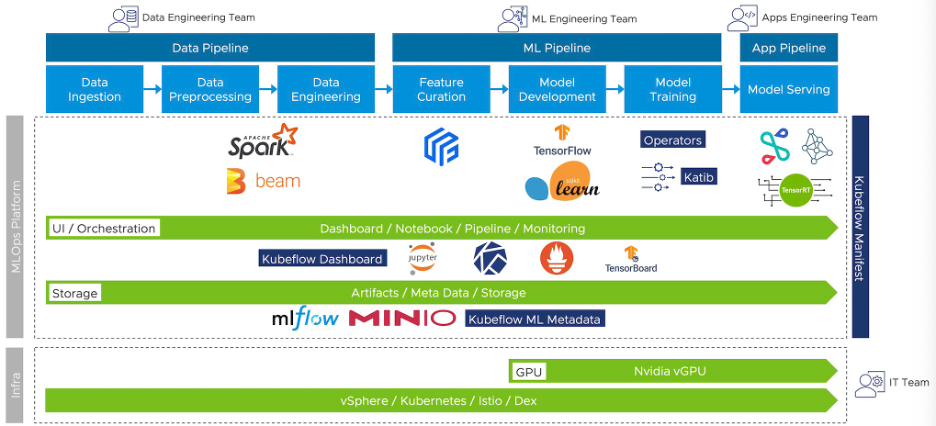
Kubeflow VMware Distribution的架构图如下所示:
![]()
Kubeflow VMware Distribution的主要特点包括:
-
通过与VMware基础架构的无缝集成,允许客户在现有VMware投资基础上更快地部署Kubeflow,从而利用成熟的vSphere、VMware NSX、vSAN等企业特性,高效地部署人工智能/机器学习项目。
-
使用Carvel打包技术将Kubeflow核心组件与Tanzu Kubernetes Grid自然集成,打造vSphere上的一站式Kubeflow部署经验。
-
提供了与vSphere集成的Pinniped的统一身份管理,先进的GPU动态管理、集成监控堆栈、多租户控制访问等企业级功能和产品就绪能力。
-
支持不同类型的机器学习工作负载,包括自然语言处理(NLP)、图像分类、视频识别等,特别是时下流行的开源大语言模型部署、微调及预训练。
未来,Kubeflow VMware Distribution将持续改进,与更多VMware产品特性进行深度融合,充分利用来自 VMware 合作伙伴的众多商业 MLOps 工具(例如 Anyscale、cnvrg.io、Domino Data Lab、NVIDIA、One Convergence、Run:ai 和 Weights & Biases等),在中国我们也将与浪潮、超聚变等合作伙伴在此领域进行合作。让我们共同期待!
本文作者:贺黎,VMware高级项目经理;刘奇,VMware高级工程师;曹磊,VMware工程师。
内容来源|公众号:VMware 中国研发中心
有任何疑问,欢迎扫描下方公众号联系我们哦~