







一次网络请求中的流量分发过程 | 京东云技术团队
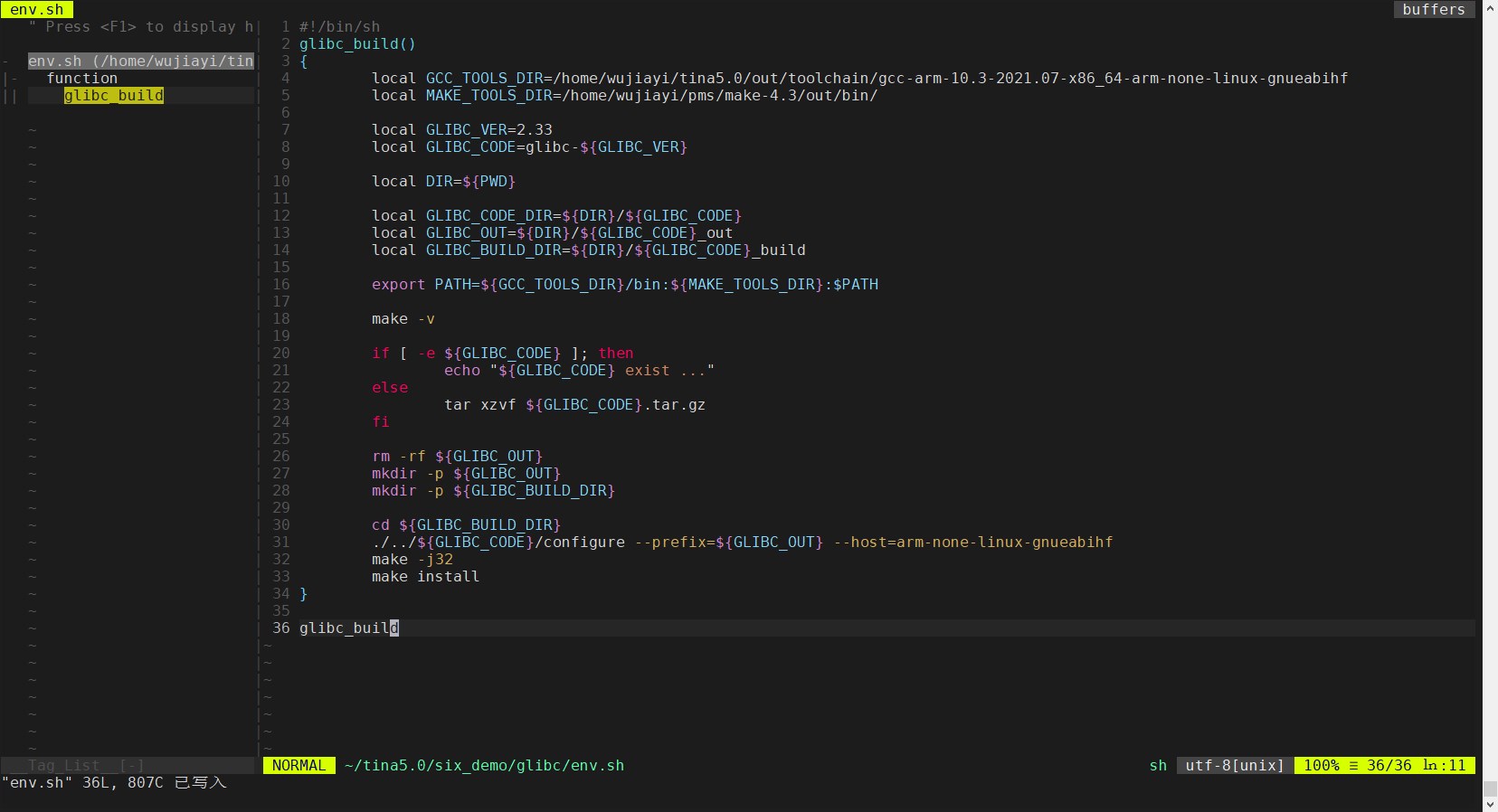
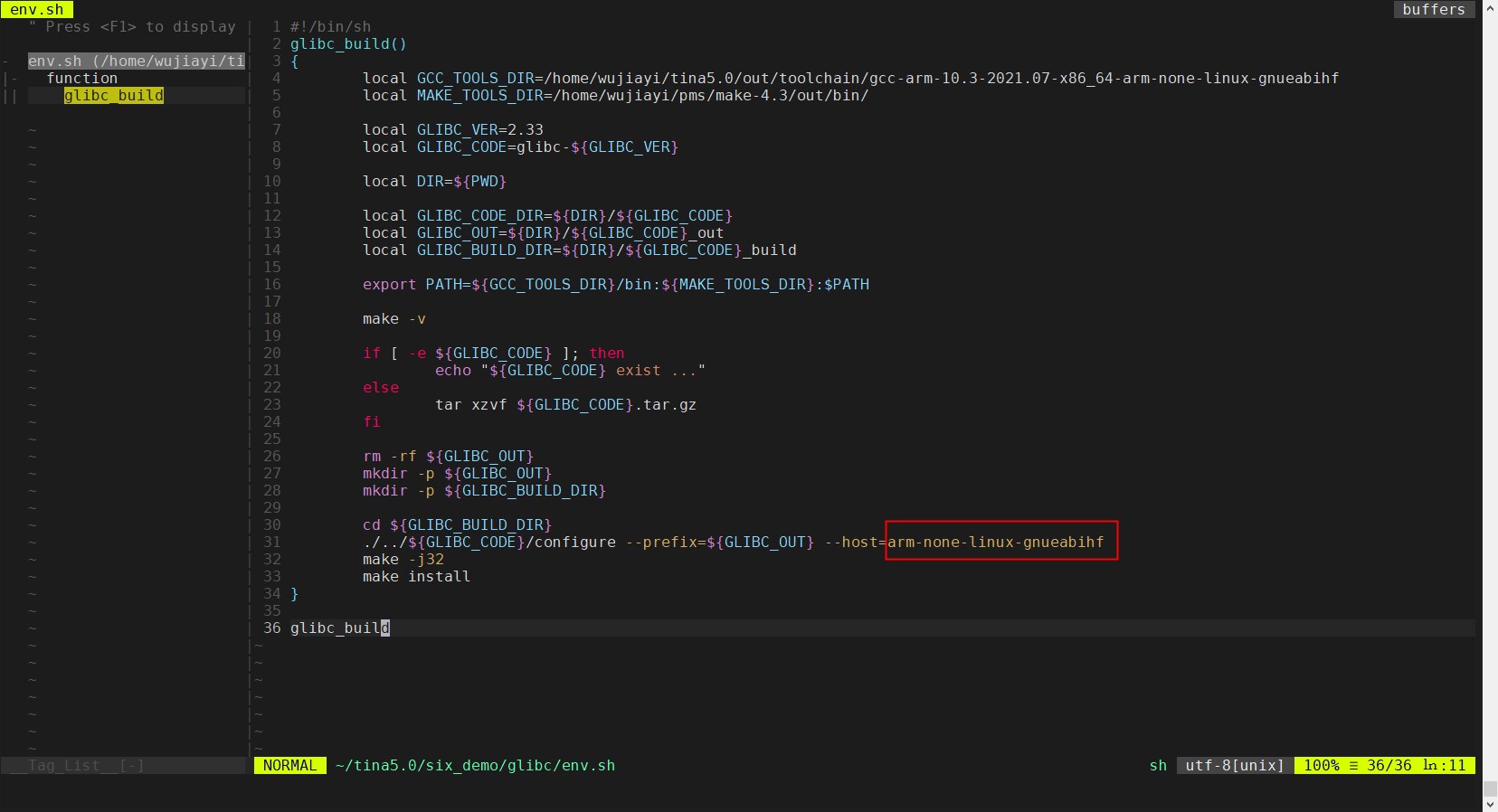
1. 摘要 现代的企业级或互联网系统往往需要进行流量规划,达成透明多级分流。流量从客户端发出到服务端处理这个过程里,流经的与功能无关的技术部件有(达成“透明分流”这个目标所采用的工具与手段):客户端缓存、域名服务器、传输链路、内容分发网络、负载均衡器、服务端缓存。透明分流带来的价值:高可用架构、高并发。 本文主要介绍流量规划中的网络请求过程过程及: 第一部分:对一次网络请求的过程作简要介绍,然后介绍自己目前了解到的前端网络组件搭配方式、后端网络组件搭配方式 第二部分:介绍LB负载系统 、vip与rip 的映射关系 第三部分:介绍内网域名解析及公网域名解析 2. 网络请求过程 通用请求过程及请求过程名词解释来源于: https://cf.jd.com/pages/viewpage.action?pageId=766717554 2.1 通用请求过程 2.2 请求过程名词解释 rip: 真实ip,指虚拟机或容器ip vip: 虚拟ip,不可跨机房,online申请,负载、自动探活等功能,分公网vip与内网vip 内网: 专指机房内部,严格的防火墙策略,内网之间无防火墙,可申请内网vip 提...