- GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源。
- GreatSQL是MySQL的国产分支版本,使用上与MySQL一致。
- 作者:KAiTO
- 文章来源:GreatSQL社区原创
什么是慢查询日志
MySQL 的慢查询日志,用来记录在 MySQL 中响应时间超过阀值的语句,具体指运行时间超过 long_query_time 值的SQL,则会被记录到慢查询日志中。long_query_time 的默认值为10,意思是运行10秒以上(不含10秒)的语句,认为是超出了我们的最大忍耐时间值。
它的主要作用是,帮助我们发现那些执行时间特别长的SQL查询,并且有针对性地进行优化,从而提高系统的整体效率。当我们的数据库服务器发生阻塞、运行变慢的时候,检查一下慢查询日志,找到那些慢查询,对解决问题很有帮助。比如一条sq|执行超过5秒钟,我们就算慢SQL,希望能收集超过5秒的sql,结合explain进行全面分析。
默认情况下,MySQL数据库没有开启慢查询日志,需要我们手动来设置这个参数。如果不是调优需要的话,一般不建议启动该参数,因为开启慢查询日志会或多或少带来一定的性能影响
慢查询日志支持将日志记录写入文件。
如何开启慢查询日志
开启slow_query_log
mysql> show variables like '%slow_query_log%';
+-----------------------------------+--------------------------------+
| Variable_name | Value |
+-----------------------------------+--------------------------------+
| slow_query_log | OFF |
| slow_query_log_always_write_time | 10.000000 |
| slow_query_log_file | /var/lib/mysql/KAiTO-slow.log |
| slow_query_log_use_global_control | |
+-----------------------------------+--------------------------------+
4 rows in set (0.00 sec)
# 开启慢查询
mysql > set global slow_query_log='ON';
Query OK, 0 rows affected (0.12 sec)
然后我们再来查看下慢查询日志是否开启,以及慢查询日志文件的位置:
mysql> show variables like '%slow_query_log%';
+-----------------------------------+--------------------------------+
| Variable_name | Value |
+-----------------------------------+--------------------------------+
| slow_query_log | ON |
| slow_query_log_always_write_time | 10.000000 |
| slow_query_log_file | /var/lib/mysql/KAiTO-slow.log |
| slow_query_log_use_global_control | |
+-----------------------------------+--------------------------------+
4 rows in set (0.00 sec)
你能看到这时慢查询分析已经开启,同时文件保存在 /var/lib/mysql/KAiTO-slow.log 文件中。
修改long_query_time阈值
接下来我们来看下慢查询的时间阈值设置,使用如下命令:
mysql> show variables like '%long_query_time%';
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| long_query_time | 10.000000 |
+-----------------+-----------+
1 row in set (0.00 sec)
意思就是超过10秒的SQL语句就会被记录慢查询日志中,那要如何修改这个阈值呢?
mysql> set global long_query_time = 1;
mysql> show global variables like '%long-query_time%';
或修改 my.cnf 文件,[mysqld]下增加或修改参数long_query_time、slow_query_log和slow_query_log_file后,然后重启MySQL服务器。
[mysqld]
slow_query_log=ON #开启慢查询日志的开关
slow_query_log_file=/var/lib/mysql/my-slow.log #慢查询日志的目录和文件名信息
long_query_time=3 #设置慢查询的阈值为3秒,超出此设定值的SQL即被记录到慢查询日志
log_output=FILE # 一般有两种形式,一种是输出到文件FILE中,一种是写入数据表格table中,会保存到mysql库的slow_log表中
如果不指定存储路径,慢查询日志将默认存储到 MySQL 数据库的数据文件夹下。如果不指定文件名,默认文件名为hostname-slow.log。
补充
除了上述变量,控制慢查询日志的还有一个系统变量: min_examined_row_limit。 这个变量的意思是,查询扫描过的最少记录数。这个变量和查询执行时间,共同组成了判别一个查询是否是慢查询的条件。如果查询扫描过的记录数大于等于这个变量的值,并且查询执行时间超过long_query_time的值,那么,这个查询就被记录到慢查询日志中; 反之,则不被记录到慢查询日志中。
mysql> show variables like 'min%';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| min_examined_row_limit | 0 |
+------------------------+-------+
1 row in set (0.01 sec)
你也可以根据需要,通过修改 my.cnf 文件,来修改min_examined_row_limit的值。
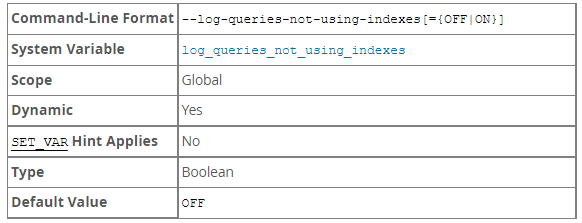
除了记录普通的慢查询之外,MySQL 还提供了两个参数来让我们记录未使用索引的查询,它们分别是:log-queries-not-using-indexes 和 log_throttle_queries_not_using_indexes
log-queries-not-using-indexes
系统变量log-queries-not-using-indexes作用是未使用索引的查询也被记录到慢查询日志中。
![amIpmEdO1DQh2jHqBodZ4NI3NbqlGgb9Yyak2yq15lG]()
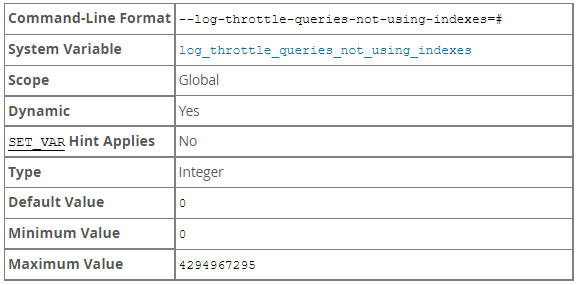
log_throttle_queries_not_using_indexes
可通过设置 log_throttle_queries_not_using_indexes 来限制每分钟写入慢日志中的不走索引的SQL语句个数,该参数默认为 0,表示不开启,也就是说不对写入SQL语句条数进行控制。 ![图片]()
在生产环境下,如果没有使用索引,那么此类 SQL 语句会频繁地被记录到 slow log,从而导致 slow log 文件大小不断增加,我们可以通过调整此参数进行配置。
如果启用 log_slow_extra 系统变量(从 MySQL 8.0.14 开始提供),服务器会在日志写入几个额外字段。若要记录bytes_received 与 bytes_sent这两个字段则需要开启
GreatSQL是源于Percona Server的分支版本,除了Percona Server已有的稳定可靠、高效、管理更方便等优势外,特别是进一步提升了MGR(MySQL Group Replication)的性能及可靠性,以及众多bug修复。这就是为什么在使用GreatSQL查看慢查询日志时,会有Query_time、Lock_time等信息,这些都是我们GreatSQL源于Percona Server的原因,使查询内容更加丰富,更多的数据可以使得我们更好的排查错误。
通过一个简单的案例来展示: 我们先把慢查询日志打开且设置时间阈值大于1秒就记录:
#开启慢查询日志
mysql> set global slow_query_log='ON';
Query OK, 0 rows affected (0.00 sec)
#时间阈值超过1秒就记录
mysql> set global long_query_time = 1;
Query OK, 0 rows affected (0.01 sec)
mysql> show variables like '%long_query_time%';
+-----------------+----------+
| Variable_name | Value |
+-----------------+----------+
| long_query_time | 1.000000 |
+-----------------+----------+
1 row in set (0.00 sec)
#查看已经被记录的慢查询数量
mysql> SHOW GLOBAL STATUS LIKE '%Slow_queries%';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Slow_queries | 3 |
+---------------+-------+
1 row in set (0.01 sec)
写一条SQL语句使得使用时间大于1秒
mysql> SELECT * FROM `student` WHERE id>1000 AND `name`='Yunxi';
+---------+-------+-------+------+---------+
| 9999715 | 707 | Yunxi | 863 | 71 |
.......省略
| 9999999 | 418 | Yunxi | 793 | 734 |
+---------+-------+-------+------+---------+
166949 rows in set (3.94 sec)
mysql> SHOW GLOBAL STATUS LIKE '%Slow_queries%';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Slow_queries | 4 |
+---------------+-------+
1 row in set (0.00 sec)
可以看到此条SQL已经被记录,接下来我们去查看慢查询日志:
# Time: 2022-12-14T15:01:34.892085Z
# User@Host: root[root] @ localhost [] Id: 8
# Query_time: 3.985637 Lock_time: 0.000138 Rows_sent: 165346 Rows_examined: 9900000 Thread_id: 8 Errno: 0 Killed: 0 Bytes_received: 0 Bytes_sent: 4848540 Read_first: 0 Read_last: 0 Read_key: 1 Read_next: 9900000 Read_prev: 0 Read_rnd: 0 Read_rnd_next: 0 Sort_merge_passes: 0 Sort_range_count: 0 Sort_rows: 0 Sort_scan_count: 0 Created_tmp_disk_tables: 0 Created_tmp_tables: 0 Start: 2022-12-14T15:01:30.906448Z End: 2022-12-14T15:01:34.892085Z Schema: slow Rows_affected: 0
# Tmp_tables: 0 Tmp_disk_tables: 0 Tmp_table_sizes: 0
# InnoDB_trx_id: 0
# Full_scan: No Full_join: No Tmp_table: No Tmp_table_on_disk: No
# Filesort: No Filesort_on_disk: No Merge_passes: 0
# InnoDB_IO_r_ops: 27606 InnoDB_IO_r_bytes: 452296704 InnoDB_IO_r_wait: 0.220474
# InnoDB_rec_lock_wait: 0.000000 InnoDB_queue_wait: 0.000000
# InnoDB_pages_distinct: 8191
use slow;
SET timestamp=1671030090;
SELECT * FROM `student` WHERE id>100000 AND `name`='Yunxi';
可以看到慢查询日志记录的非常详细,从上述日志中能看到几个信息:
- 1.这个SQL的耗时3.985637秒。
- 2.返回结果有165346行,总共需要扫描9900000行数据。如果扫描行数很多,但返回行数很少,说明该SQL效率很低,可能索引不当。
- 3.Read_* 等几个指标表示这个SQL读记录的方式,是否顺序读、随机读等。
- 4.Sort_* 等几个指标表示该SQL是否产生了排序,及其代价。如果有且代价较大,需要想办法优化。
- 5.tmp 等几个指标表示该SQL是否产生临时表,及其代价。如果有且代价较大,需要想办法优化。
- 6.Full_scan/Full_join表示是否产生了全表扫描或全表JOIN,如果有且SQL耗时较大,需要想办法优化。
- 7.InnoDB_IO_* 等几个指标表示InnoDB逻辑读相关数据。
- 8.InnoDB_rec_lock_wait 表示是否有行锁等待。
- 9.InnoDB_queue_wait 表示是否有排队等待。
- 10.InnoDB_pages_distinct 表示该SQL总共读取了多少个InnoDB page,是个非常重要的指标。
GreatSQL可以作为MySQL或Percona Server的可选替代方案,用于线上生产环境。完全免费并兼容MySQL或Percona Server。综上,如果在生产环境中已经用上Percona Server的话,那么也可以放心使用GreatSQL。详情可见:(https://greatsql.cn/doc/#!&v=47_6_0)了解更多GreatSQL内容
查看慢查询数目
查询当前系统中有多少条慢查询记录
SHOW GLOBAL STATUS LIKE '%Slow_queries%';
慢查询日志分析工具
在生产环境中,如果要手工分析日志,查找、分析SQL,显然是个体力活,MySQL提供了日志分析工具 mysqldumpslow ,或者是可以使用另一个工具pt-query-digest。 它可以从logs、processlist、和 tcpdump 来分析 MySQL 的状况,logs包括 slow log、general log、binlog。也可以把分析结果输出到文件中,或则把文件写到表中。分析过程是先对查询语句的条件进行参数化,然后对参数化以后的查询进行分组统计,统计出各查询的执行时间、次数、占比等,可以借助分析结果找出问题进行优化。
关闭慢查询日志
作者建议除了调优需要开,正常还是不要开了
MySQL服务器停止慢查询日志功能的方法:
[mysqld]
slow_query_log=OFF
SET GLOBAL slow_query_log=off;
删除慢查询日志
mysql> show variables like '%slow_query_log%';
+-----------------------------------+--------------------------------+
| Variable_name | Value |
+-----------------------------------+--------------------------------+
| slow_query_log | ON |
| slow_query_log_always_write_time | 10.000000 |
| slow_query_log_file | /var/lib/mysql/zhyno1-slow.log |
| slow_query_log_use_global_control | |
+-----------------------------------+--------------------------------+
4 rows in set (0.00 sec)
通过以上查询可以看到慢查询日志的目录,在该目录下手动删除慢查询日志文件即可。或使用命令 mysqladmin 来删除,mysqladmin 命令的语法如下:mysqladmin -uroot -p flush-logs执行该命令后,命令行会提示输入密码。输入正确密码后,将执行删除操作。新的慢查询日志会直接覆盖旧的查询日志,不需要再手动删除。
注意 慢查询日志都是使用mysqladmin flush-logs命令来删除重建的。使用时一定要注意,一旦执行了这个命令,慢查询日志都只存在新的日志文件中,如果需要旧的查询日志,就必须事先备份。
参考文章
Enjoy GreatSQL :)
关于 GreatSQL
GreatSQL是由万里数据库维护的MySQL分支,专注于提升MGR可靠性及性能,支持InnoDB并行查询特性,是适用于金融级应用的MySQL分支版本。
相关链接: GreatSQL社区 Gitee GitHub Bilibili
GreatSQL社区:
捉虫活动详情:https://greatsql.cn/thread-97-1-1.html
社区博客有奖征稿详情:https://greatsql.cn/thread-100-1-1.html
![6440]()
技术交流群:
微信:扫码添加GreatSQL社区助手微信好友,发送验证信息加群。
![image-20221030163217640]() )
)

 )
)