hello,大家好,我是张张,「架构精进之路」公号作者。
提到MySQL,想必大多后端同学都不会陌生,提到B+树,想必还是有很大部分都知道InnoDB引擎的索引实现,利用了B+树的数据结构。
那InnoDB 的一棵B+树可以存放多少行数据?它又有多高呢?
到底是哪些因素会对此造成影响呢,今天我们就来展开聊一下。
1 InnoDB引擎数据存储
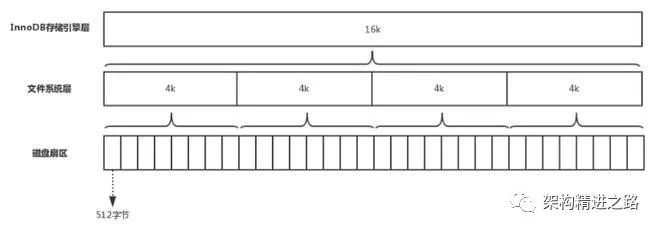
在计算机中,磁盘存储数据最小单元是扇区,一个扇区的大小是512字节,而文件系统(例如XFS/EXT4)的最小单元是块,一个块的大小是4k,在InnoDB存储引擎中,也有页(Page)的概念,默认每个页的大小为16K,也就是每次读取数据时都是读取4*4k的大小!
![]()
在MySQL中,InnoDB页的大小默认是16k,当然也可以通过参数设置:
![]()
2 InnoDB引擎数据操作
接下来,为了让大家能更好地理解数据存储逻辑,我们来进行一个数据操作实例进行讲解。
假设我们现在有一个用户表,我们往里面写入数据。
![]()
这里需要注意的一点是,在某个页内插入新数据行时,为了减少数据的移动,通常是插入到当前行的后面或者是已删除行留下来的空间,所以在某一个页内的数据并不是完全有序的。但是为了为了数据访问顺序性,在每个记录中都有一个指向下一条记录的指针,因此构成了一条单向有序链表。
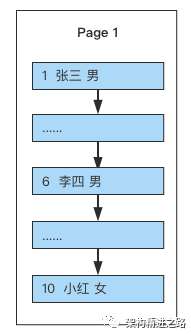
当数据还比较少时,一个页就能容下,所以只有一个根结点,主键和数据也都是保存在根结点(左边的数字代表主键,右边姓名、性别代表具体的记录数据)。
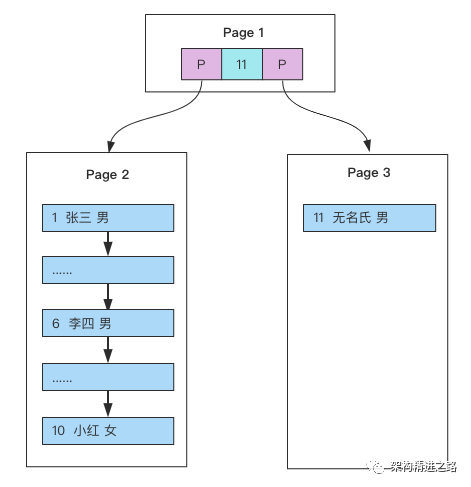
假设我们写入10条数据之后,Page1满了,再写入新的数据会怎么存放呢?
![]()
有个叫“无名氏”的朋友来了,但是Page1已经放不下数据了,这时候就需要进行页分裂,产生一个新的Page页。
在InnoDB 中的页分裂流程是怎么样的呢?
1、产生新的Page2,然后将Page1的内容复制到Page2。
2、产生新的Page3,“无名氏”的数据放入Page3。
3、原来的Page1依然作为根结点,但是变成了一个不存放数据只存放索引的页,并且有两个子结点Page2、Page3。
看到这里,大家可能会有两个问题:
Q1:为什么要复制Page1为Page2呢?直接创建一个新的页作为根结点,这样不就少了一次复制的开销么?
A:如果是新创建根结点,那根结点存储的物理地址可能经常会变,不利于查找。并且在InnoDB中根结点是会预读到内存中的,所以结点的物理地址固定会比较好。
Q2:原来Page1有10条数据,在插入第11条数据的时候进行页裂变,根据对B-Tree、B+Tree特性的了解,那这至少是一颗11阶的树,裂变之后每个结点的元素至少为11/2=5个,那是不是应该页裂变之后主键1-5的数据还是在原来的页,主键6-11的数据会放到新的页,根结点存放主键6呢?
A:如果是这样的话,新的页空间利用率只有50%,并且会导致更为频繁的页分裂。所以InnoDB对这一点做了优化,新的数据放入新创建的页,不移动原有页面的任何记录。
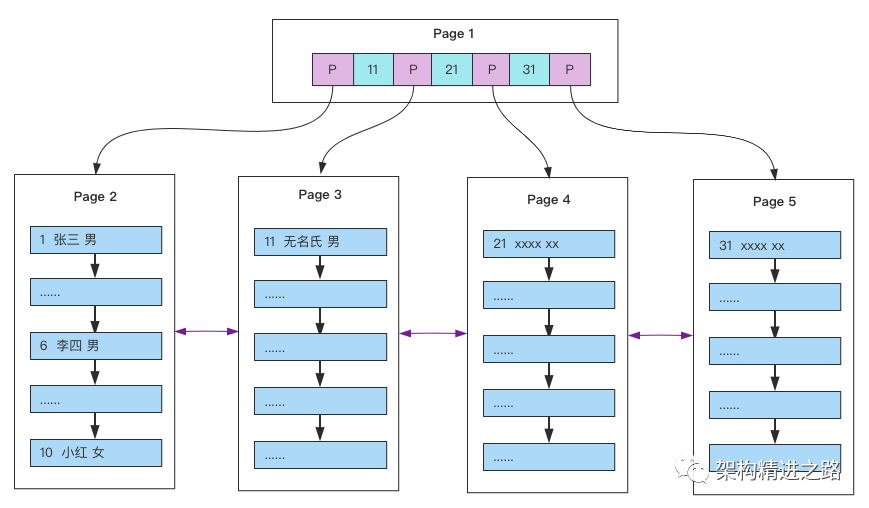
随着数据的不断写入,这棵树也逐渐枝繁叶茂,如下图:
![]()
每次新增数据,都是将一个页写满,然后新创建一个页继续写,这里其实是有个隐含条件的,那就是主键自增!主键自增写入时新插入的数据不会影响到原有页,插入效率高!且页的利用率高!但是如果主键是无序的或者随机的,那每次的插入可能会导致原有页频繁的分裂,影响插入效率!降低页的利用率!这也是为什么在InnoDB中建议设置主键自增的原因!
这棵树的非叶子结点上存的都是主键,那如果一个表没有主键会怎么样?在InnoDB中,如果一个表没有主键,那默认会找建了唯一索引的列,如果也没有,则会生成一个隐形的字段作为主键!
有数据插入那就有删除,如果这个用户表频繁的插入和删除,那会导致数据页产生碎片,页的空间利用率低,还会导致树变的“虚高”,降低查询效率!这可以通过索引重建来消除碎片提高查询效率!
3 InnoDB引擎索引高度
回到开篇的问题:InnoDB 的一棵B+树可以存放多少行数据?它又有多高呢?
这个需要区分叶子节点和非叶子节点:
InnoDB 存储引擎默认一个数据页大小为16kb,非叶子节点存放(key,pointer),假设主键ID为bigint类型,长度为8字节,而指针大小在InnoDB源码中设置为6字节,这样一共14字节,即非叶子节点能存放 16kb/14 左右的key,pointer。
单个叶子节点(页)中的记录数 = 16K/1K = 16。
这里我们假设一行记录的数据大小为1k左右
总结一下:
如果B+树高度为2的话,那么这棵B+树的存放总记录数为:根节点指针数*单个叶子节点记录行数 = 16kb/14 * 16 大约 1.8w+ 数据。
如果B+树高度为3的话,那么这棵B+树的存放总记录数为:根节点指针数*单个叶子节点记录行数 = 16kb/14 * 16kb/14 * 16 大约2kw+数据。
因此常见 InnoDB存储引擎B+树的高度基本为2-3。
希望今天的讲解对大家有所帮助,谢谢!
Thanks for reading!
关注公众号,免费领学习资料
如果您觉得还不错,欢迎关注和转发~
![]()