Part 1 - 关于Hint
Hint是嵌入SQL语句的对优化器进行提示的信息,是DBA进行SQL优化的常用手段。SQL语句经过优化器(规则优化(RBO)、代价优化(CBO)),通常会选择正确的查询路径,但是智者千虑,必有一失,有时优化器也会选择一个很差的计划,使得该条SQL查询变得很慢,此时需要DBA人为干预(通过给SQL语句增加一个注释),告诉优化器要选择指定的访问路径(full scan、index scan)或join 类型(merge、hash、lookup),使得该条SQL语句可以高效的运行。
Part 2 - Hint的使用
通过 /*+ ... */ 的注释形式放在 SELECT 关键字之后,多个 hint 之间用逗号隔开。
例如 select /*+use_index(t, index1)*/ * from t where a = 10 and b = 20;
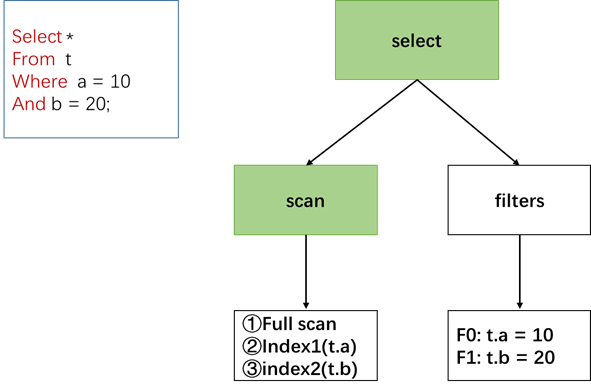
如下图所示,经过RBO会得到如下normalized plan,而/*+ use_index(t, index1)*/ 将作用于scan选择的过程,这将告诉优化器在选择表t的访问路径(① ② ③)时,选择②索引index1。
![]()
Part 3 - Hint在云溪数据库中的
解析和应用流程
整体流程如下图3.1所示:
![]()
图3.1 hint 解析使用流程
第一步:输入带有hint SQL语句,如下所示
| SELECT /*+ use_index(t1, idx1), merge_join(t1, t2) */ count(*) FROM t1, t2 WHERE t1.a = t2.b; |
第二步:parser 编译解析;
第三步:将AST中的hint信息保存在HintSet中;
第四步:Builder从AST中获取hint信息,将对应hint解析到TableHint和IndexHint结构体中;
第五步:normalized plan阶段(RBO),通过调用buildScan为表构建ScanFlags,调用buildJoin为表构建JoinFlags;
第六步:在CBO阶段进行探索时,根据组成员的Flags信息,通过开销大小,来阻止某些等价表达式的生成,并生成hint需要的表达式,从而减小搜索空间;
第七步:生成hint作用之下的最优查询计划。
Part 4 - Hint 在云溪数据库中
不同阶段的表现形式
-
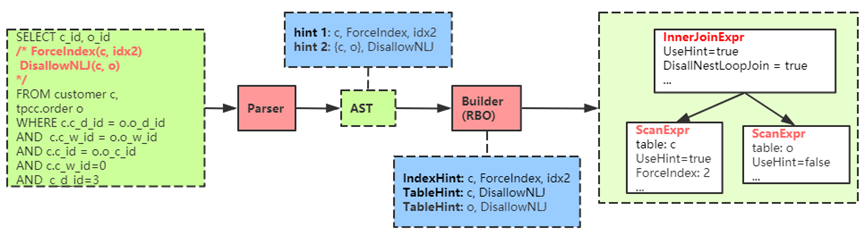
SQL语句中:显示指定要在表c上强制使用idx2,与c和o相关的join操作不允许使用NLJ算子;
-
经过parser后,hint信息保存在HintSet中;
-
在Builder中,hint信息以对象index和table为单位进行保存;
-
在规范化计划树和Memo结构体中,hint信息存在对应的Expr结构体中。
详细流程如下图4.1所示:
![]()
图4.1 hint在不同阶段的表现形式图
Part 5 - Hint对优化器的影响
图5.1结构解释:
![]()
图5.1 hint作用图
| bestHT 存储着每个Group的代价最低的表达式。 exprHT 存储所有探索出来的表达式。 Group为逻辑等价的关系表达式的集合。 |
在云溪数据库中hint 影响计划的手段主要有两个,一个是探索阶段中,减少表达式的生成(例如指定megejoin,正常情况下会生成 merge、lookup、hash 三种连接类型,但是指定了mergejoin,就会直接不生成其他的的表达式),如下①;另一个是代价计算阶段中返回一个很大的代价hugeCost(例如针对t1,指定index1,然后对于其他的访问方法,则会直接返回很大的代价),如下③。
Hint对优化器的影响如下:
① 排除了若干操作,减少了Memo结构体中表达式的个数,如下图X号所示;
② 决定相关Group的最优计划选择, 如下图Group 1;
③ Group 1中,#1作为规范化表达式必然存在于组中,但是,它的代价被设置为hugeCost;
③ 由于使用ForceIndex,在探索阶段使用其它索引的表达式不会被优化器选择;
⑤ 最终影响最优计划树的选择。