网络内核之TCP是如何发送和接收消息的
老规矩,带着问题阅读:
- 三次握手中服务端做了什么?
- 为什么要将accept()单独一个线程而不是和读写的io线程共用一个线程池?netty分为boss和worker
- 当调用send()返回后数据就一定到对方或者在网线中传输了呢?
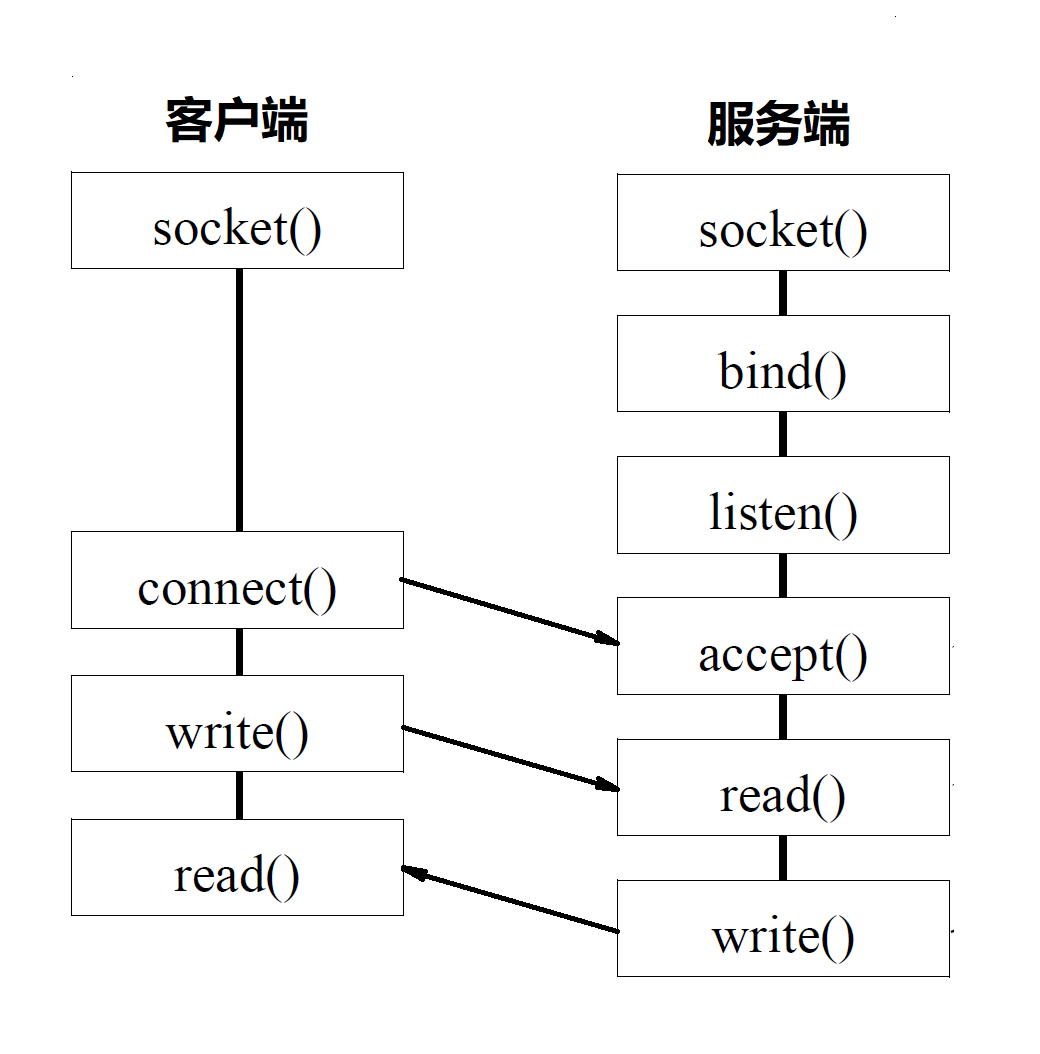
我们先来回顾一下,我们编写一个网络程序有哪些步骤? 基于socket的编程:
代码如下:
public class Server {
public static void main(String[] args) throws Exception {
//创建一个socket套接字,开始监听某个端口 对应了 socket() bind() listen()
ServerSocket serverSocket = new ServerSocket(8080);
// (1) 接收新连接线程
new Thread(() -> {
while (true) {
try {
// 等待客户端连接,accept() 获取一个新连接
Socket socket = serverSocket.accept();
new Thread(() -> {
try {
byte[] data = new byte[1024];
InputStream inputStream = socket.getInputStream();
while (true) {
int len;
// 读取字节数组 对应read()
while ((len = inputStream.read(data)) != -1) {
System.out.println(new String(data, 0, len));
}
}
} catch (IOException e) {
}
}).start();
} catch (IOException e) {}
}
}).start();
}
}
public class Client {
public static void main(String[] args) {
try {
//对应 socket() 和 connect() 发起连接
Socket socket = new Socket("127.0.0.1", 8000);
while (true) {
try {
//对应 write() 方法
socket.getOutputStream().write((new Date() + ": hello world").getBytes());
socket.getOutputStream().flush();
Thread.sleep(2000);
} catch (Exception e) {
}
}
} catch (IOException e) {
}
}
}
服务端我们首先会创建一个监听套接字,然后给这个套接字绑定一个ip和端口,这一步对应的方法就是bind(),之后就是调用listen()来监听端口,端口是和应用程序对应的,网卡收到一个数据包的时候后需要知道这个包是给哪个程序用的,当然一个应用程序可以监听多个端口。之后客户端发起连接内核会分配一个随机端口,然后tcp在经历三次握手成功后,客户端会创建一个套接字由connect()方法返回,而服务端的accept()方法也会返回一个套接字,之后双方都会基于这个套接字进行读写操作。所以服务端会维护两种类型的套接字,一种用于监听,另一种用于和客户端进行读写。
![基于socket的网络编程过程]()
而在linux内核中,socket其实是一个文件,挂载于SocketFS文件类型下,有点类似于/proc,不过该文件不能像磁盘上的文件一样进行正常的访问和读写。既然是文件,就会有inode来表示索引,有具体的地方存储数据不管是磁盘还是内存,而socket的数据是存储在内存中的,每个报文的数据是存放在一个叫 sk_buff 的结构体里,要访问文件我们一般会对应一个文件描述符,每个文件描述符都会有一个id,在jdk中也有相关定义。
public final class FileDescriptor {
private int fd;
jvm启动后就是一个独立进程,每个进程会维护一个数组,这个数组存放该进程已经打开的文件的描述符,数组前三个分别是标准输入,标准输出,错误输出三个文件描述符,从第4个开始为用户打开的文件,或者创建的socket,而数组的下标就是文件描述符的id,内核通过文件描述符可以找到对应的inode,然后在通过vfs找到对应的文件,进行read和write操作。
三次握手

linux内核中会维护两个队列,这两个队列的长度都是有限制且可以配置的,当客户端发起connect()请求后,服务端收到syn包后将该信息放入sync队列,之后客户端回复ack后从sync队列取出,放到accept队列,之后服务端调用accept()方法会从accept队列取出生成socket。
如果客户端发起sync请求,但是不回复ack,将导致sync队列满载,之后会拒接新的连接。如果客户端发起ack请求后,服务端一直不调用,或者调用accept队列太慢,将导致accept队列满载,accept队列满了则收到ack后无法从syn队列移出去,导致syn队列也会堆积,最终拒绝连接。所以服务端一般会将accept单独起一个线程执行,避免accept太慢导致数据丢弃。当然accept()方法也有阻塞和非阻塞两种,当accept队列为空的时候阻塞方法会一直等待,非阻塞方法会直接返回一个错误码。
消息发送
连接建立好后,客户端和服务端都有一个socket套接字,双方都可以通过各自的套接字进行发送和接收消息,socket里面维护了两个队列,一个发送队列,一个接收队列。
发送的时候数据在用户空间的内存中,当调用send()或者write()方法的时候,会将待发送的数据按照MSS进行拆分,然后将拆分好的数据包拷贝到内核空间的发送队列,这个队列里面存放的是所有已经发送的数据包,对应的数据结构就是sk_buff,每一个数据包也就是sk_buff都有一个序号,以及一个状态,只有当服务端返回ack的时候,才会把状态改为发送成功,并且会将这个ack报文的序号之前的报文都确认掉,如果长期没有确认,会重新调用tcp_push继续发送,如果发送队列慢了,则从用户空间拷贝到内核空间的操作就会阻塞,并触发清理队列中已确认发送成功的数据包。tcp层会将数据包加上ip头然后发给ip层处理,ip层将数据包加入到一个qdisc队列,网卡驱动程序检测到qdisc队列有数据就会调用DMA Engine将sk_buff拷贝到网卡并发送出去,网卡驱动通过ringbuffer来指向内核中的数据,所以qdisc的长度也会影响到网络发送的吞吐量。


关于mss分片:mtu是数据链路层的最大传输单元,一般为1500字节,而一个ip包的最大长度为65535,所以ip层在发送数据前会根据mtu分片,这样一个tcp包本来对应一个ip包,分片后将对应多个ip包,每个包都有一个ip头,在接收端需要等到所有的ip包到达后,才能确定这个tcp收到然后才发送ack,这种方式无疑是低效的,所以tcp层会尽量阻止ip层进行分片,他会在从用户空间拷贝的时候就会按照mtu进行拆分,将一个数据包拆分成多个数据包。但是链路中mtu是会改变的,为了完全避免ip层进行分片,可以在ip层设置一个df标记,如果一定要分片就慧慧一个icmp报文。
关于流控:
- 滑动窗口:接收方返回的一个最大发送序号。这个不是报文大小,而是一个序号,接收方每次会返回一个下次报文发送的序号不要超过的值。这个值主要和接收方内部缓存大小有关。
- 阻塞窗口:发送方根据网络拥堵情况,根据已经发送到网络但是还未确认的数据包的数量来计算。由于广域网络的复杂所以拥塞控制有一系列算法,如慢启动等。
- nagle算法:为了避免机器发了大量的小数据包,nagle算法限制每次将多个小数据包达到一定大小后在发送。
由于tcp发送的时候会进行各种分片和合并,所以接收方会出现粘包现象,需要应用层进行处理。
消息接收
当服务端网卡收到一个报文后,网卡驱动调用DMA engine将数据包通过ringbuffer拷贝到内核缓冲区中,拷贝成功后,发起中断通知中断处理程序,这时候ip层会处理该数据包,之后交给tcp层,最终到达tcp层的recv buffer(接收队列),这时候就会返回ack给客户端,并没有等到客户端调用read将数据从内核拷贝到用户空间,所以应用层也应该有相关的确认机制。如果recv buffer设置的太小,或者应用层一直不来取,那么也将阻塞数据接收,从而影响到滑动窗口大小,导致吞吐量降低。

tcp在收到数据包后会获取序号,并且看是否应该正好放入接收队列,如果此时收到一个大序号的报文,会将该报文缓存直到接收队列中之前的报文已经插入。
另外如果网卡支持多队列,可以将多个队列绑定到不同的cpu上,这样网卡收到报文后,不同的队列就会通过中断触发不同的cpu,从而可以提高吞吐量。
c10k问题
c10k问题是指怎么支持单机1万的并发请求,我们想到通过select的多路复用模式,用一个单独的线程去扫描需要监听的文件描述符,如果这些文件描述符里面有可读或者可写的就返回(tcp层在收到报文拷贝到内存后会修改这个文件描述符的状态),没有就阻塞,不过这种方式需要对文件描述符进行扫描,效率不高。而epoll方式采用红黑树去管理文件描述符,当文件可读或者可写的时候会通过一个回调函数通知用户进行具体的io操作。