版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/beliefer/article/details/79688675
本文旨在帮助那些想要对Spark有更深入了解的工程师们,了解Spark源码的概况,搭建Spark源码阅读环境,编译、调试Spark源码,为将来更深入地学习打下基础。
一、项目结构
在大型项目中,往往涉及非常多的功能模块,此时借助于Maven进行项目、子项目(模块)的管理,能够节省很多开发和沟通成本。整个Spark项目就是一个大的Maven项目,包含着多个子项目。无论是Spark父项目还是子项目,本身都可以作为独立的Maven项目来管理。core是Spark最为核心的功能模块,提供了RPC框架、度量系统、Spark UI、存储体系、调度系统、计算引擎、部署模式等功能的核心实现。这些Spark中主要子项目(模块)的功能如下:
- spark-catalyst:Spark的词法、语法分析、抽象语法树(AST)生成、优化器、生成逻辑执行计划、生成物理执行计划等。
- spark-core:Spark最为基础和核心的功能模块。
- spark-examples:使用多种语言,为Spark学习人员提供的应用例子。
- spark-sql:Spark基于SQL标准,实现的通用查询引擎。
- spark-hive:Spark基于Spark SQL,对Hive元数据、数据的支持。
- spark-mesos:Spark对Mesos的支持模块。
- spark-mllib:Spark的机器学习模块。
- spark-streaming:Spark对流式计算的支持模块。
- spark-unsafe:Spark对系统内存直接操作,以提升性能的模块。
- spark-yarn:Spark对Yarn的支持模块。
二、阅读环境准备
准备Spark阅读环境,就需要一台好机器。笔者调试源码的机器的内存是8GB。源码阅读的前提是首先在IDE环境中打包、编译通过。常用的IDE有 IntelliJ IDEA和Eclipse,笔者选择用Eclipse编译和阅读Spark源码,原因有二:一是由于使用多年对它比较熟悉,二是社区中使用Eclipse编译Spark的资料太少,在这里可以做个补充。笔者在Mac OS系统编译Spark源码,除了安装JDK和Scala外,还需要安装以下工具。
1.安装SBT
由于Scala使用SBT作为构建工具,所以需要下载SBT。下载地址: http://www.scala-sbt.org/,下载最新的安装包sbt-0.13.12.tgz并安装。
移动到选好的安装目录,例如:
mv sbt-0.13.12.tgz~/install/
进入安装目录,执行以下命令:
chmod 755 sbt-0.13.12.tgz
tar -xzvf sbt-0.13.12.tgz
配置环境:
cd ~
vim .bash_profile
添加如下配置:
export SBT_HOME=$HOME/install/sbt
export PATH=$SBT_HOME/bin:$PATH
输入以下命令使环境变量快速生效:
source .bash_profile
安装完毕后,使用sbt about命令查看,确认安装正常,如图1所示。
![]()
图1 查看sbt安装是否正常
2.安装Git
由于Spark源码使用Git作为版本控制工具,所以需要下载Git的客户端工具。下载地址:https://git-scm.com,下载最新的版本并安装。
安装完毕后可使用git –version命令来查看安装是否正常,如图2所示。
![]()
图2 查看git是否安装成功
3.安装Eclipse Scala IDE插件
Eclipse通过强大的插件方式支持各种IDE工具的集成,要在Eclipse中编译、调试、运行Scala程序,就需要安装Eclipse Scala IDE插件。下载地址:http://scala-ide.org/download/current.html。
由于笔者本地的Eclipse版本是Eclipse Mars.2 Release (4.5.2),所以选择安装插件http://download.scala-ide.org/sdk/lithium/e44/scala211/stable/site,如图3:
![]()
图3 EclipseScala IDE插件安装地址
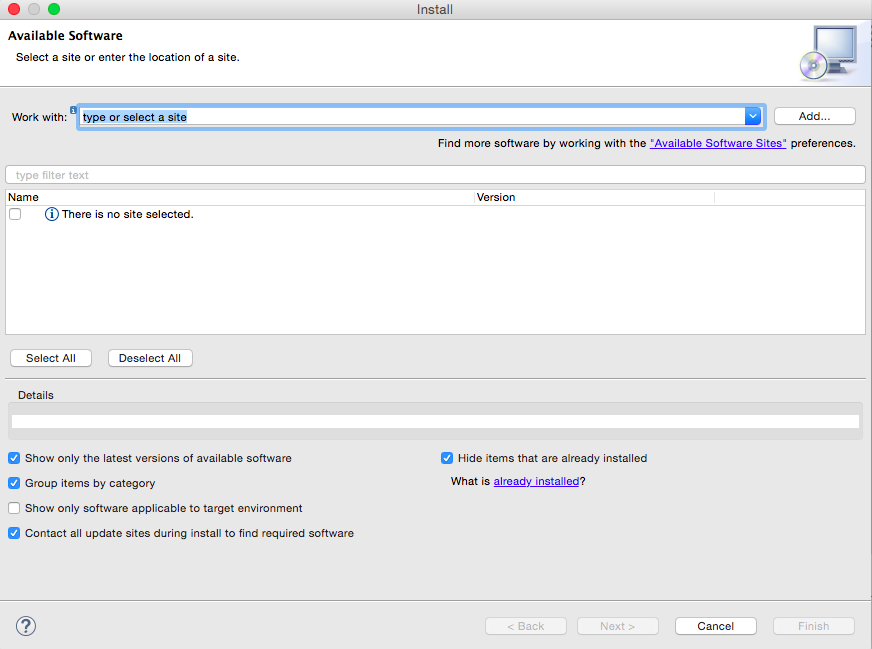
在Eclipse中选择“Help”菜单,然后选择“Install New Software…”选项,打开Install对话框,如图4所示:
![]()
图4 安装Scala IDE插件
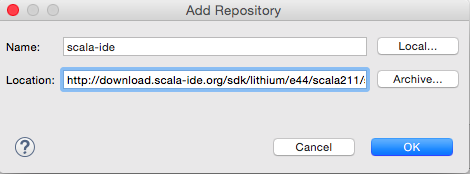
点击“Add…”按钮,打开“Add Repository”对话框,输入插件地址,如5图所示:
![]()
图5 添加Scala IDE插件地址
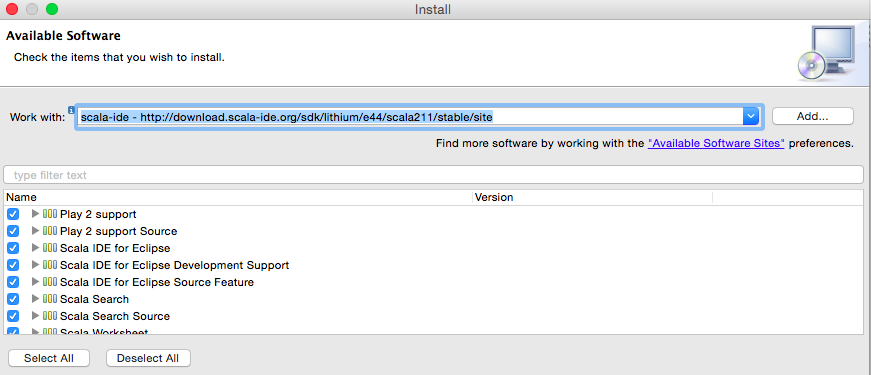
全选插件的内容,完成安装,如图6所示:
![]()
图6 安装Scala IDE插件
三、Spark源码编译与调试
1.下载Spark源码
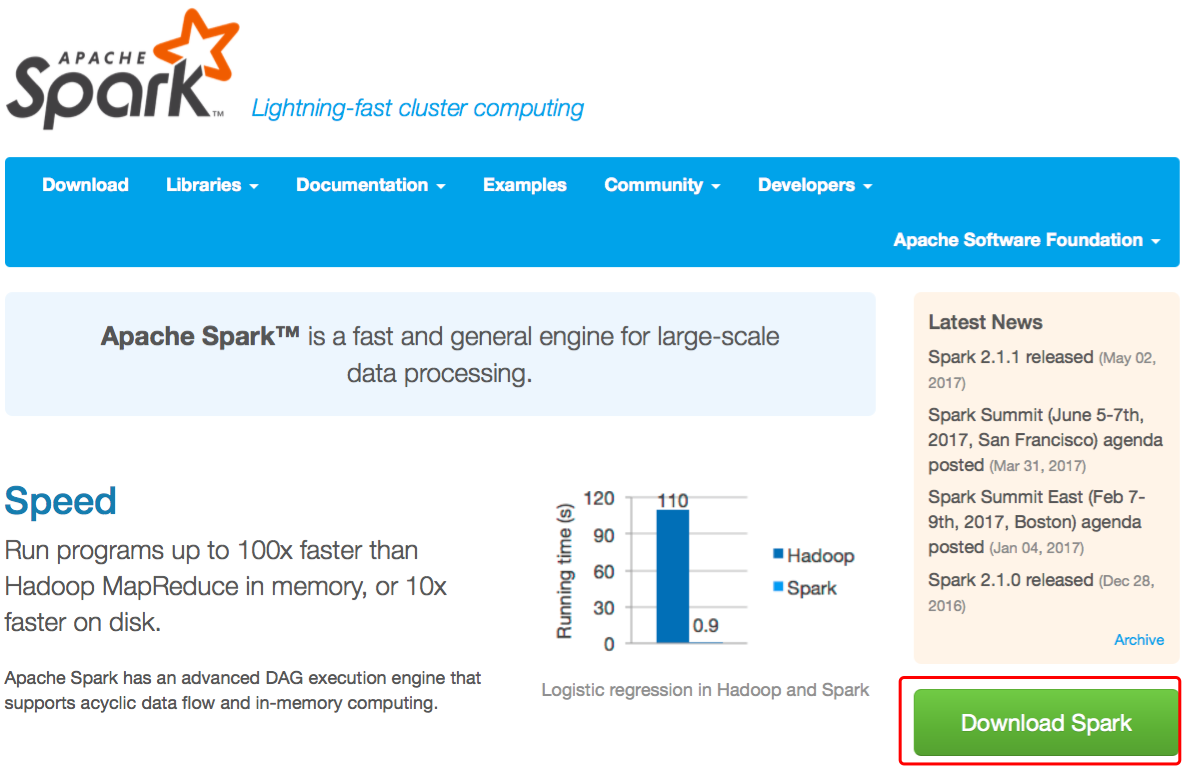
首先,访问Spark官网http://spark.apache.org/,如图7所示。
![]()
图7 Spark官网
点击“Download Spark”按钮,在下一个页面找到Git地址,如图8所示。
![]()
图8 Spark官方Git地址
笔者在当前用户目录下创建Source文件夹作为放置Spark源码的地方,进入此文件夹并输入git clonegit://github.com/apache/spark.git命令将源码下载到本地,如9图所示。
![]()
图9下载Spark源码
2.构建Scala应用
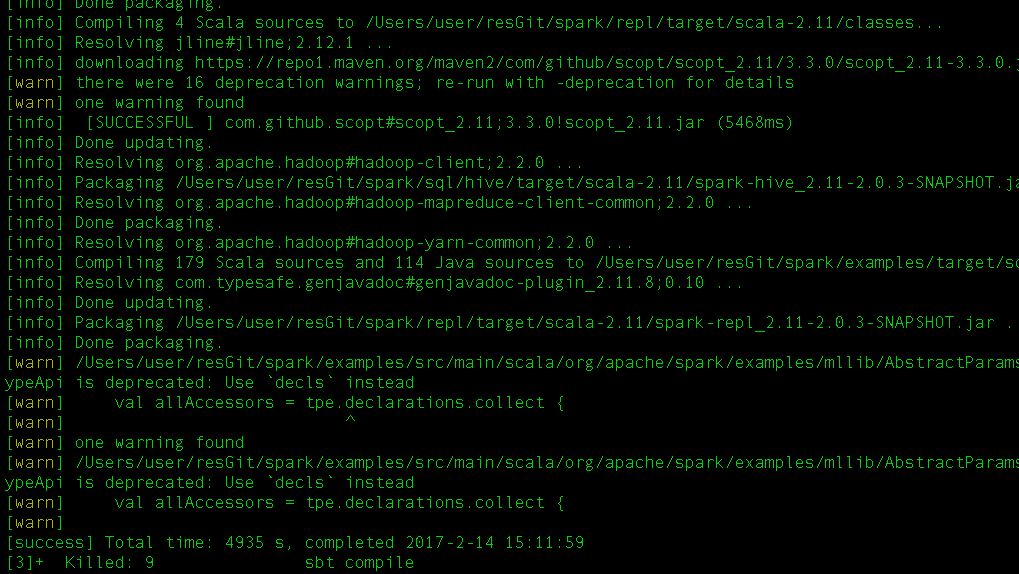
进到Spark根目录,执行sbt命令。会下载和解析很多jar包,要等很长的时间,笔者大概花费了一个多小时,才执行完,如图10所示。
![]()
图10 构建Scala应用
从图10可以看出,sbt构建完毕时会出现提示符>。
3.使用sbt生成eclipse工程文件
在sbt命令出现提示符>后,输入eclipse命令,开始生成eclipse工程文件,也需要花费很长的时间,笔者本地大致花费了40分钟。完成时的状况,如图11所示。
![]()
图11 sbt编译过程
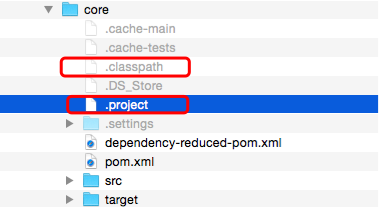
现在我们查看Spark下的子文件夹,发现其中都生成了.project和.classpath文件。比如mllib项目下就生成了.project和.classpath文件,如图12所示。
![]()
图12 sbt生成的项目文件
4. 编译Spark源码
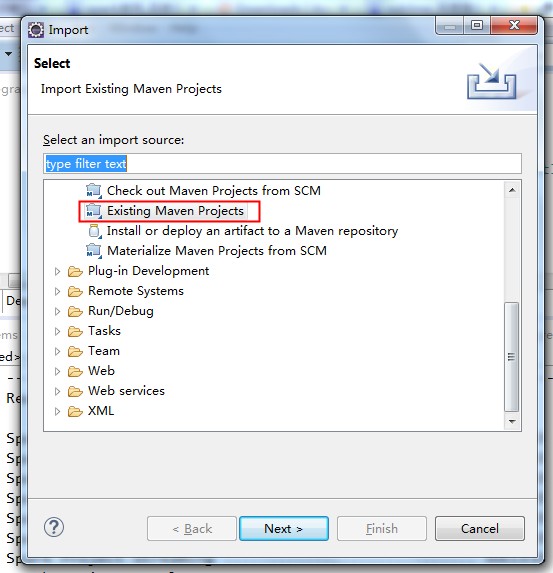
由于Spark使用Maven作为项目管理工具,所以需要将Spark项目作为Maven项目导入到Eclipse中,如13图所示:
![]()
图13 导入Maven项目
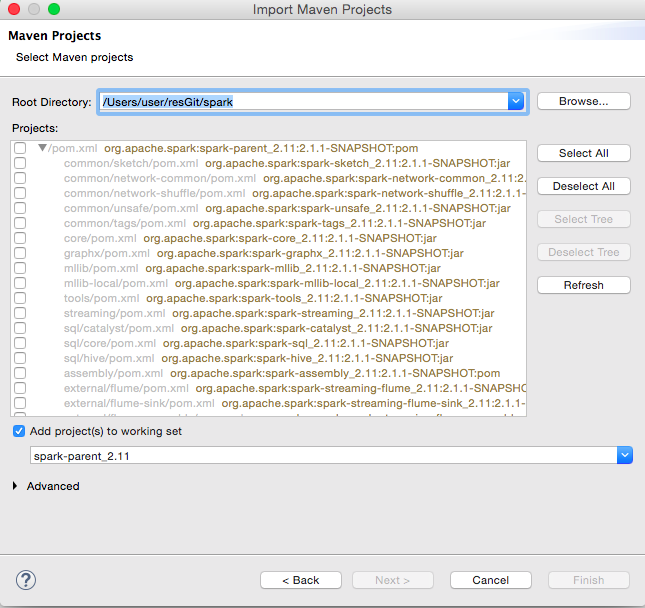
点击Next按钮进入下一个对话框,如图14所示:
![]()
图14 选择Maven项目
全选所有项目,点击finish按钮。这样就完成了导入,如图15所示:
![]()
图15 导入完成的项目
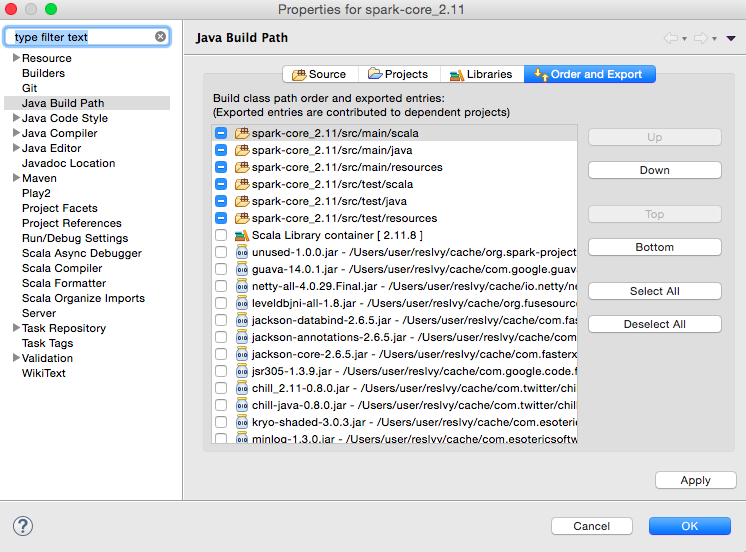
导入完成后,需要设置每个子项目的build path。右键单击每个项目,选择“Build Path”→“Configure BuildPath…”,打开Build Path对话框,如图16:
![]()
图16 Java构建路径
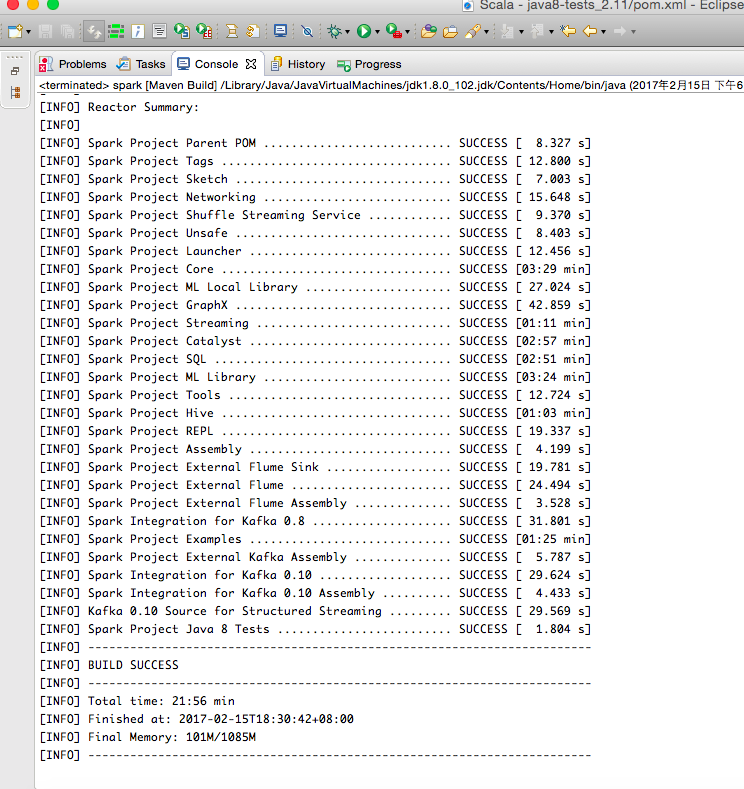
Eclipse在对项目编译时,可能会出现很多错误,只要仔细分析报错原因就能一一排除。所有错误解决后运行mvn clean install,如图17所示:
![]()
图17 编译成功
5.调试Spark源码
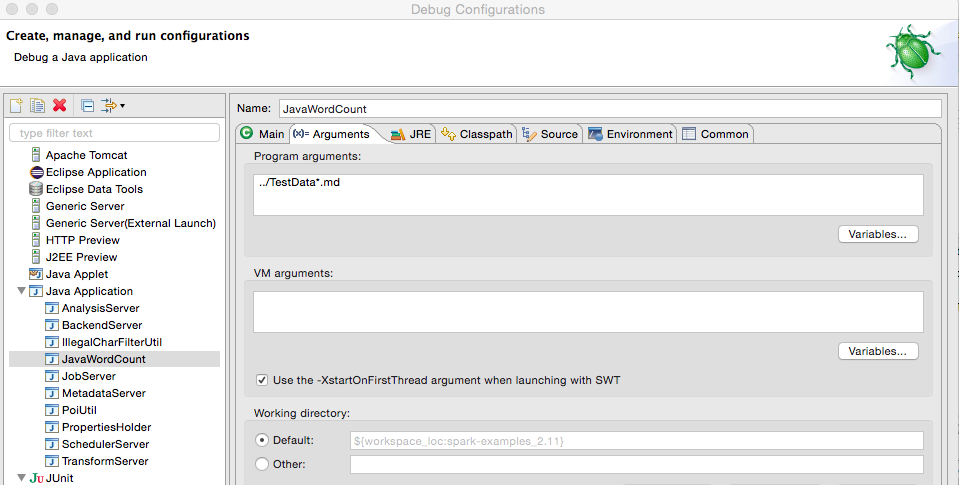
以Spark源码自带的JavaWordCount为例,介绍如何调试Spark源码。右键单击JavaWordCount.java,选择“Debug As”→“Java Application”即可。如果想修改配置参数,右键单击JavaWordCount.java,选择“Debug As”→“DebugConfigurations…”,从打开的对话框中选择JavaWordCount,在右侧标签可以修改Java执行参数、JRE、classpath、环境变量等配置,如图18所示:
![]()
图18 源码调试
读者也可以在Spark源码中设置断点,进行跟踪调试。
关于《Spark内核设计的艺术 架构设计与实现》
经过近一年的准备,基于Spark2.1.0版本的《
Spark内核设计的艺术 架构设计与实现》一书现已出版发行,图书如图:
电子版售卖链接如下: