随着Spark SQ的引入以及Hive On Apache Spark的新功能(HIVE-7292)的引入,我们对这两个项目的立场以及它们与Shark的关系有了很多的关注。在今天的Spark Summit上,我们宣布我们正在停止Shark的开发,并将资源全部集中在Spark SQL上,这将为现有Shark用户提供一个Shark特色的圈子(will provide a superset of Shark’s features for existing Shark users to move forward)。特别是,Spark SQL将提供从Shark 0.9服务器进行无缝升级途径,以及与Spark程序集成的新功能。
![image]()
1. Shark
3年前Shark项目开始时,Hive(MapReduce)是Hadoop上SQL的唯一选择。Hive将SQL编译成可扩展的MapReduce作业,并可以使用各种格式(通过其SerDes)。 但是,它的性能不如理想。为了交互式查询,组织部署了昂贵的专有企业数据仓库(EDW),这些仓库需要严格且冗长的ETL管道( organizations deployed expensive, proprietary enterprise data warehouses (EDWs) that required rigid and lengthy ETL pipelines)。
Hive和EDW之间的表现形成了鲜明的对比,导致了行业内一个巨大的争议,质疑通用数据处理引擎查询处理的固有缺陷。 许多人认为SQL交互需要为查询处理提供一个昂贵的专门的运行时构建(例如,EDW)(Many believed SQL interactivity necessitates an expensive, specialized runtime built for query processing)。Shark将成为第一个基于Hadoop系统的交互式SQL之一,是唯一一个构建在通用运行框架(Spark)之上(Shark became one of the first interactive SQL on Hadoop systems, and was the only one built on top of a general runtime (Spark))。It demonstrated that none of the deficiencies that made Hive slow were fundamental, and a general engine such as Spark could marry the best of both worlds: it can be as fast as an EDW, and scales as well as Hive/MapReduce.
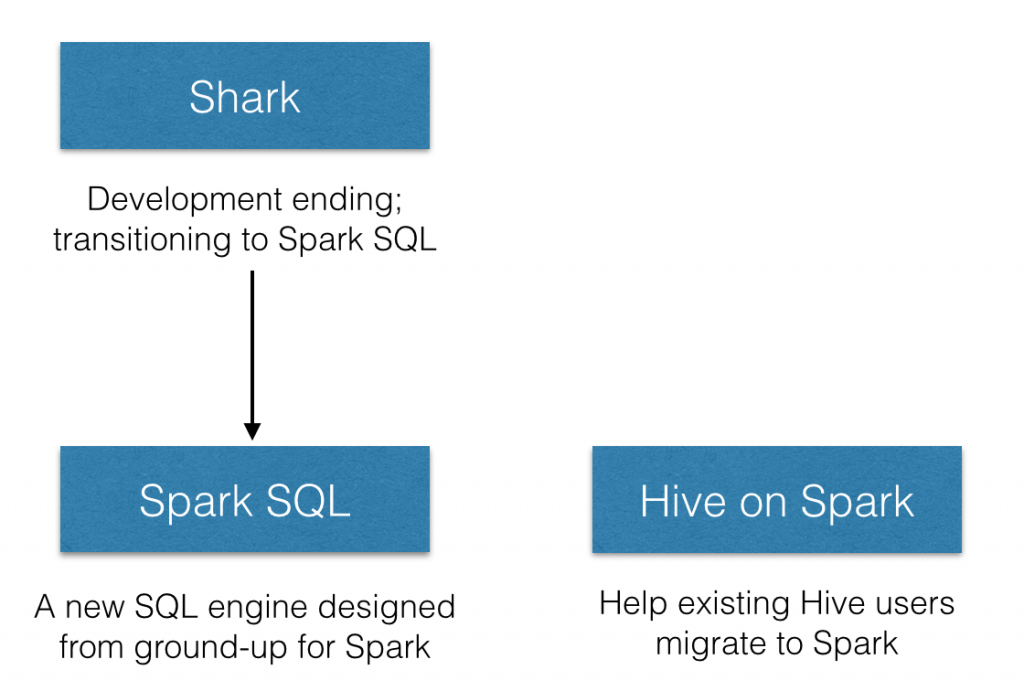
2. 从Shark到Spark SQL
Shark建立在Hive代码库上,通过交换Hive的物理执行引擎部分来实现性能提升(swapping out the physical execution engine part of Hive)。虽然这种方法使Shark用户能够加快其Hive查询,但Shark继承了Hive中庞大而复杂的代码库,从而难以优化和维护。 随着我们推动性能优化的边界,并将复杂分析与SQL集成,我们受到为MapReduce设计而遗留的限制。
正是由于这个原因,我们将结束Shark作为一个单独项目的开发,并将所有开发资源转移到Spark的新组件Spark SQL上。我们正在将我们在Shark中学到的内容应用到Spark SQL中,充分利用Spark的强大功能。这种新方法使我们能够更快地创新,并最终为用户带来更好的体验。
对于SQL用户,Spark SQL提供了最先进的SQL性能,并保持与Shark/Hive的兼容性。特别是像Shark一样,Spark SQL支持现有所有Hive数据格式,用户自定义函数(UDF)和Hive metastore。 随着将在Apache Spark 1.1.0中引入的功能,Spark SQL在TPC-DS性能方面比Shark好几乎一个数量级。
对于Spark用户,Spark SQL可以处理(半)结构化数据(Spark SQL becomes the narrow-waist for manipulating (semi-) structured data),以及从提供schema的数据源(如JSON,Parquet,Hive或EDW)中提取数据。它真正统一了SQL和复杂分析,允许用户混合和匹配SQL以及允许使用更多的命令式编程API进行高级分析。
对于开源黑客,Spark SQL提出了构建查询计划者的一种新颖优雅的方式。 在这个框架下添加新的优化是非常容易的。我们惊讶于 开源社区对Spark SQL所展示出的支持和热情,这在很大程度上得益于这一新设计。经过三个月的时间,40多个捐助者已经为此编写了代码。
3. Hive On Spark
虽然Spark SQL正在成为SQL on Spark的标准,但是我们确实意识到许多公司以及组织Hive的投资。 然而,这些组织中的很多也渴望迁移到Spark。Hive社区为该项目提出了一项新举措,将Spark添加为Hive的执行引擎之一。 对于这些组织,这项工作将为他们将执行迁移到Spark提供一条明确的途径。我们很高兴与Hive社区合作和支持,为最终用户提供平滑的体验。
总之,我们坚信Spark SQL将不仅是SQL,而且还是Spark进行结构化数据处理的未来。
原文:https://databricks.com/blog/2014/07/01/shark-spark-sql-hive-on-spark-and-the-future-of-sql-on-spark.html