目标
- 爬取京东商城上iPhone X用户评论数据;
- 使用jieba对评论数据进行分词处理;
- 使用wordcloud绘制词云图。
目前京东商城只会展示商品的前100页评论,所以我们能爬取到的评论只有1000条。
不过如果区分下好/差/中评分别爬取的话,理论上应该能保存3000条评论。
爬虫部分
-
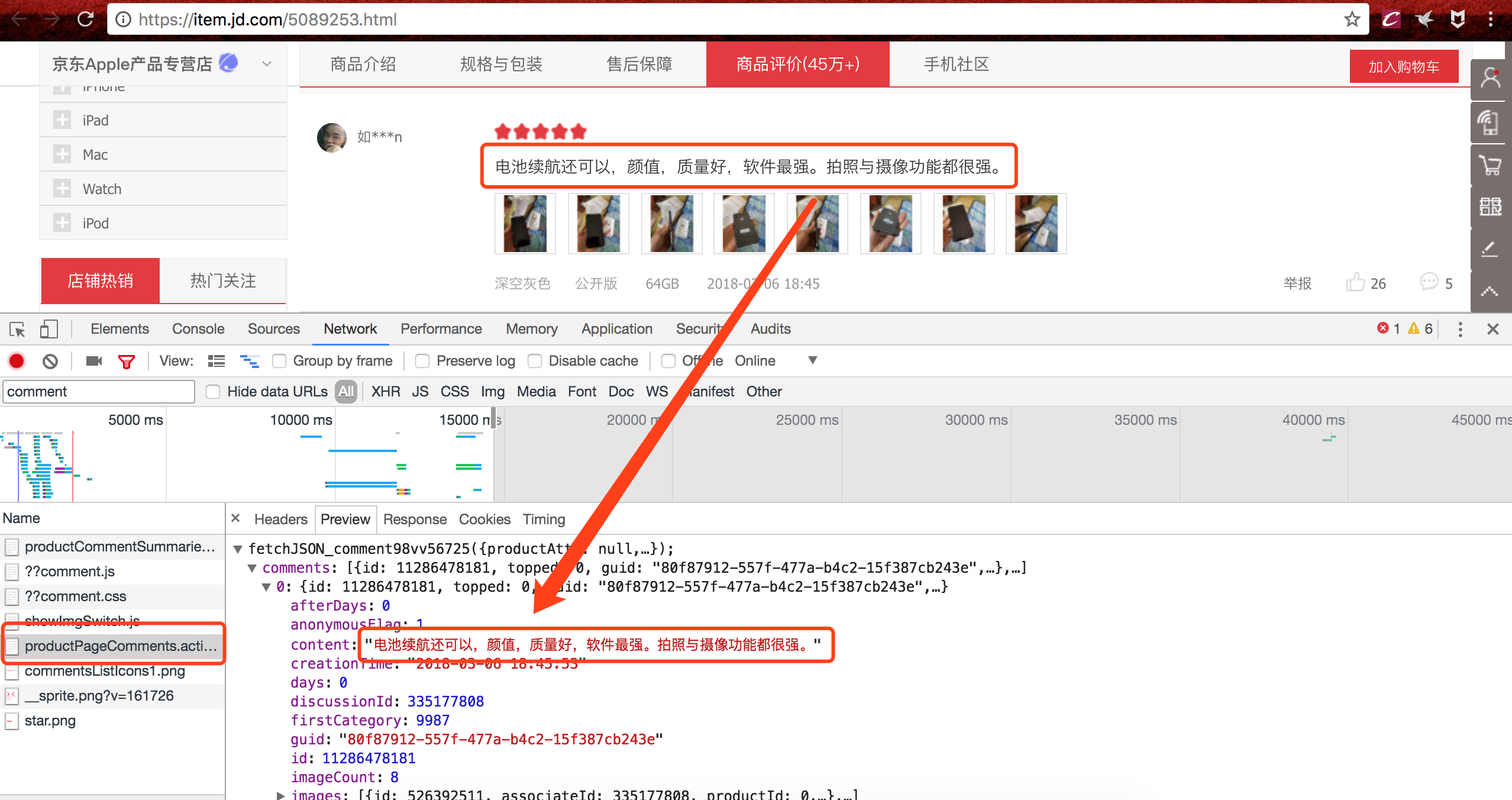
打开京东iphone X商品页面,进入控制台找到我们想要的用户评论,评论的接口地址也就找到了。
-
然后我们会发现这个接口地址是可以直接访问的,并不需要post参数,直接get就行,后面发现,连header都不需要设置,这样问题就很简单了。
-
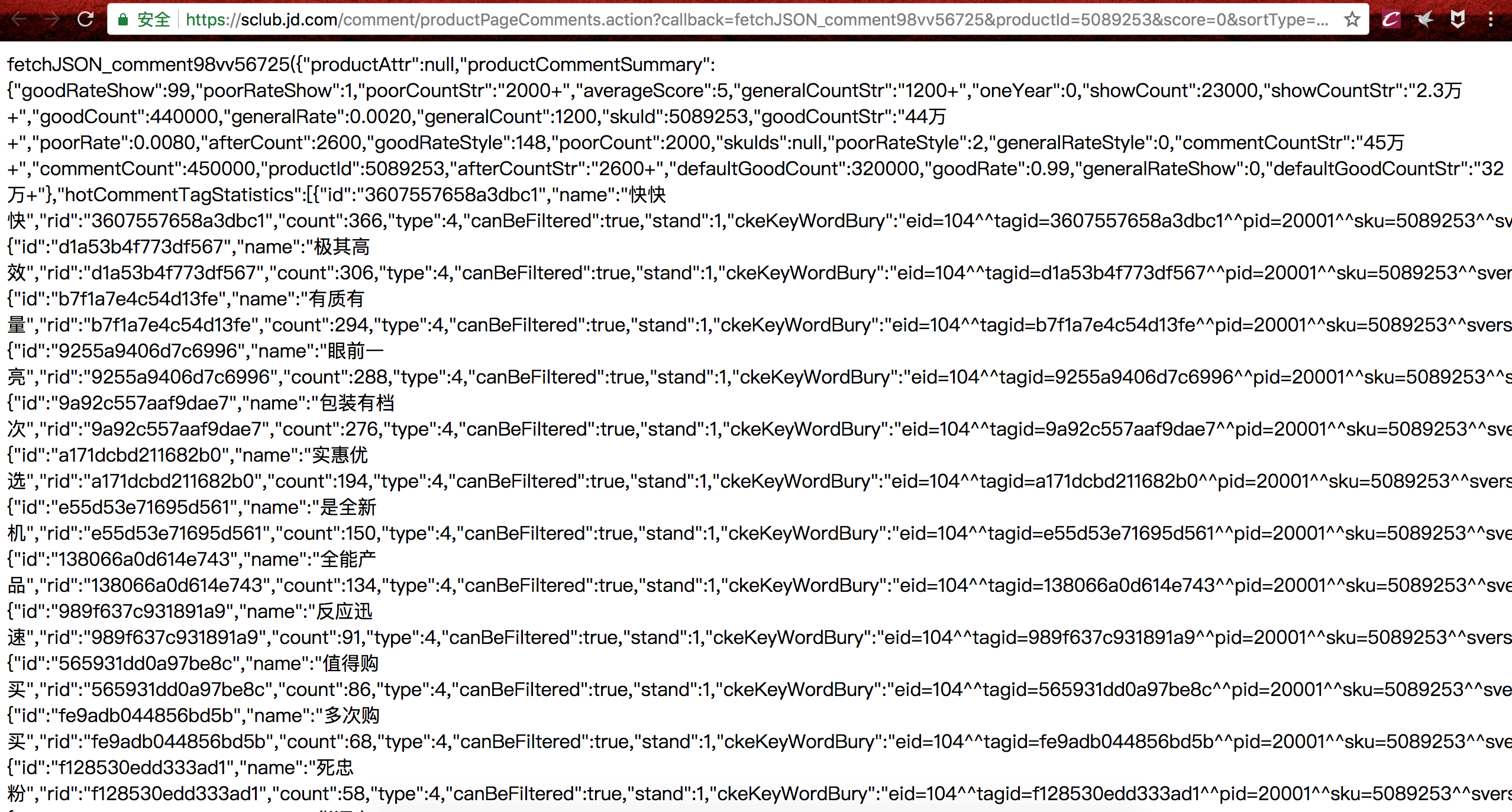
分析接口地址我们可以看到有几个参数:
productid:商品编号
score:好差评(0表示全部评论)
sortType:推荐排序/时间排序
page:页码
pagesize:每页显示评论数
还有两个没搞明白,不过不重要了,我们需要的就是写个循环传入page参数就行了。
-
接口地址返回的数据不是标准的json格式,我们需要手动处理下。
1.去掉前面的‘fetchJSON_comment98vv56725(’;
2.去掉末尾的‘);’;
3.json包加载数据处理就行了。
循环获取每个页面的评论数据,保存到本地。
绘制词云
绘制词云主要用到两个包,一个是jieba,用于文本分词的,一个是wordcloud,用于绘制最后的词云。参数比较多,大家可以直接访问jieba+wordcloud去查看。
代码部分
# -*- coding:utf-8 -*-
import requests
import json
import jieba
from scipy.misc import imread
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
import matplotlib.pyplot as plt
def jd_spider(page):
url = 'https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv56693&productId=5089253&score=0&sortType=5&page=%d&pageSize=10&isShadowSku=0&fold=1'%(page)
#用于存储单页评论,每页评论保存一次
comment = ''
#无需设置header,直接访问就行了
response = requests.get(url)
data = unicode(response.content,'GBK').encode('utf-8')
'''
接口地址返回的不是标准json数据,需要进行处理
去掉头部的‘fetchJSON_comment98vv56693(’和‘);’两部分
然后再用json包读取数据就可以了
'''
data = data.split('(',1)[1]#根据(进行切片一次处理,取第二部分
data = data[0:len(data)-2]#然后去掉后面的)和;
data_json = json.loads(str(data))['comments']
#循环读取每条评论,通过换行符连接起来
for i in list(range(len(data_json))):
comment = comment+data_json[i]['content'].encode('utf-8')+'\n'
print '****Page %d has been saved****'%(page)
return comment
#将读取的数据保存到本地txt文件
def save_comments(comments):
with open('comments.txt','a') as f:
f.write(comments)
'''
由于京东限制了,只展示前100页评论
循环99次就好了,后面返回的都是空页面
'''
for page in list(range(99)):
page = page+1
comments = jd_spider(page)
save_comments(comments)
print '****jd_spider@Awesome_Tang****'
'''
绘制词云部分
'''
back_color = imread('apple.png') # 解析该图片
wc = WordCloud(background_color='white', # 背景颜色
max_words=1000, # 最大词数
mask=back_color, # 以该参数值作图绘制词云,这个参数不为空时,width和height会被忽略
max_font_size=100, # 显示字体的最大值
font_path="/Users/tangwenpan/Downloads/simhei.ttf", # 解决显示口字型乱码问题
random_state=42, # 为每个词返回一个PIL颜色
# width=1000, # 图片的宽
# height=860 #图片的长
)
# 打开保存的评论数据
text = open('comments.txt').read()
def word_cloud(texts):
words_list = []
word_generator = jieba.cut(texts, cut_all=False) # 返回的是一个迭代器
for word in word_generator:
if len(word) > 1: #去掉单字
words_list.append(word)
return ' '.join(words_list)
text = word_cloud(text)
wc.generate(text)
# 基于彩色图像生成相应彩色
image_colors = ImageColorGenerator(back_color)
# 显示图片
plt.imshow(wc)
# 关闭坐标轴
plt.axis('off')
# 绘制词云
plt.figure()
plt.imshow(wc.recolor(color_func=image_colors))
plt.axis('off')
# 保存图片
wc.to_file('comment.png')
print 'comment.png has bee saved!'
一直觉得词云是个蛮好玩的东西,想自己也做下玩玩,所以这次也就是想着先做点东西出来,代码部分可能就比较粗糙了,后期有时间再改改。
Peace~