安装环境
| 主机 |
ip |
操作系统 |
| master |
10.30.45.239 |
centos7.4 |
| slave1 |
10.31.155.33 |
centos7.4 |
| slave2 |
10.81.233.67 |
centos7.4 |
阿里云3台ecs搭建一个小型的hbase分布式数据存储(这里的ip都是内网)。一台作为主master两台作为从slave。
安装步骤
- 安装vim编辑器
- 安装ssh
- 配置ssh免密码登陆
- 安装jdk
- 安装hadoop
- 安装zookeeper
- 安装时间同步服务 NTP
- 安装hbase
准备工作
版本
centos7.4 内核为3.10
Hadoop 2.8.3
Hbase 1.2.6
Zookeeper 3.4.10
Sqoop 1.4.7
Phoenix 4.13.1
修改hostname
# vim /etc/hostname
输入自定义主机名 ,三台都要改
修改hosts文件
分别登陆三台主机,修改hosts
vim /etc/hosts
--添加以下信息(三台都要改)
10.30.45.239 master
10.31.155.33 slave1
10.81.233.67 slave2
登陆master,下载所有安装包
--下载jdk8u31
wget --no-check-certificate --no-cookies --header "Cookie: oraclelicense=accept-securebackup-cookie" http://download.oracle.com/otn-pub/java/jdk/8u131-b11/d54c1d3a095b4ff2b6607d096fa80163/jdk-8u131-linux-x64.tar.gz
-- 下载 hadoop-2.8.3
wget http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.8.3/hadoop-2.8.3.tar.gz
--下载hbase 1.2.6
wget http://mirrors.hust.edu.cn/apache/hbase/1.2.6/hbase-1.2.6-bin.tar.gz
--下载zookeeper 3.4.10
wget http://apache.claz.org/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz
--下载phoenix4.13.1
wget http://mirror.bit.edu.cn/apache/phoenix/apache-phoenix-4.13.1-HBase-1.2/bin/apache-phoenix-4.13.1-HBase-1.2-bin.tar.gz
--下载sqoop1.4.7
wget http://mirror.cogentco.com/pub/apache/sqoop/1.4.7/sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
写这篇文章的时候是2018年4月。适当选择稳定的版本安装。下载官网如下:
设置3台ecs之间免密登陆
方便后期之间文件复制。
# # slave1
# ssh-keygen -t rsa
-- 不用输入密码,一路回车就行
# cp ~/.ssh/id_rsa.pub ~/.ssh/slave1_id_rsa.pub
# scp ~/.ssh/slave1_id_rsa.pub master:~/.ssh/
# # slave2
# ssh-keygen -t rsa
# cp ~/.ssh/id_rsa.pub ~/.ssh/slave2_id_rsa.pub
# scp ~/.ssh/slave2_id_rsa.pub master:~/.ssh/
# # master
ssh-keygen -t rsa
# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# cat ~/.ssh/slave1_id_rsa.pub >> ~/.ssh/authorized_keys
# cat ~/.ssh/slave2_id_rsa.pub >> ~/.ssh/authorized_kyes
-- 拷贝文件至slave1及slave2
# scp ~/.ssh/authorized_keys slave1:~/.ssh
# scp ~/.ssh/authorized_keys slave2:~/.ssh
关闭防火墙及SELINUX(master、slave1、slave2均需修改)
-- 关闭防火墙
# systemctl stop firewalld.service
# systemctl disable firewalld.service
-- 关闭SELINUX
# vim /etc/selinux/config
-- 注释掉
#SELINUX=enforcing
#SELINUXTYPE=targeted
-- 添加
SELINUX=disabled
设置时间同步
这里省略,第一我懒得配,第二阿里云有自动同步
安装jdk
登陆master
-- 解压jdk安装包
# mkdir /usr/java
# tar -zxvf jdk-8u131-linux-x64.tar.gz -C /usr/java
-- 拷贝jdk至slave1及slave2中
# scp -r /usr/java slave1:/usr
# scp -r /usr/java slave2:/usr
-- 设置jdk环境变量(master、slave1、slave2均需修改)
# vim /etc/environment
JAVA_HOME=/usr/java/jdk1.8.0_131
JRE_HOME=/usr/java/jdk1.8.0_131/jre
# vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_131
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
搭建Hadoop环境
解压安装
登陆master
# tar -zxvf hadoop-2.8.3-x64.tar.gz -C /usr
# cd /usr/hadoop-2.8.3
# mkdir tmp logs hdf hdf/data hdf/name
修改Hadoop配置文件
-- 修改 slaves 文件
# vim /usr/hadoop-2.8.3/etc/hadoop/slaves
-- 删除 localhost,添加
slave1
slave2
-- 修改 core-site.xml 文件
# vim /usr/hadoop-2.8.3/etc/hadoop/core-site.xml
-- 在 configuration 节点中添加以下内容
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/hadoop-2.8.3/tmp</value>
</property>
-- 修改 hdfs-site.xml 文件
# vim /usr/hadoop-2.8.3/etc/hadoop/hdfs-site.xml
-- 在 configuration 节点添加以下内容
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/hadoop-2.8.3/hdf/data</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/hadoop-2.8.3/hdf/name</value>
<final>true</final>
</property>
-- 修改 mapred-site.xml 文件
# cp /usr/hadoop-2.8.3/etc/hadoop/mapred-site.xml.template /usr/hadoop-2.8.3/etc/hadoop/mapred-site.xml
# vim /usr/hadoop-2.8.3/etc/hadoop/mapred-site.xml
-- 在 configuration 节点添加以下内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
-- 修改 yarn-site.xml 文件
# vim /usr/hadoop-2.8.3/etc/hadoop/yarn-site.xml
-- 在 configuration 节点添加以下内容
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
复制hadoop到slave节点
# scp -r /usr/hadoop-2.8.3 slave1:/usr
# scp -r /usr/hadoop-2.8.3 slave2:/usr
配置 master 和 slave 的 hadoop 环境变量
# vim /etc/profile
-- 添加如下内容
export HADOOP_HOME=/usr/hadoop-2.8.3
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HADOOP_LOG_DIR=/usr/hadoop-2.8.3/logs
export YARN_LOG_DIR=$HADOOP_LOG_DIR
-- 保存后执行
# source /etc/profile
# vim ~/.bashrc
-- 添加如下内容
export HADOOP_PREFIX=/usr/hadoop-2.8.3/
-- 保存后执行
# source ~/.bashrc
格式化 namenode
# /usr/hadoop-2.8.3/sbin/hdfs namenode -format
启动 hadoop(仅在master节点执行)
# ssh master
# /usr/hadoop-2.8.3/sbin/start-all.sh
到这一步已经成功完成了hadoop环境的搭建
Zookeeper环境搭建
解压缩 zookeeper 安装包到master,并建立基本目录
# tar -zxvf zookeeper-3.4.10.tar.gz -C /usr
# mkdir /usr/zookeeper-3.4.10/data
修改master配置文件
-- 复制配置文件模板
# cp /usr/zookeeper-3.4.10/conf/zoo-sample.cfg /usr/zookeeper-3.4.10/conf/zoo.cfg
-- 修改配置文件
# vim /usr/zookeeper-3.4.10/conf/zoo.cfg
-- 添加如下内容
dataDir=/usr/zookeeper-3.4.10/data
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
复制到各个子节点
# scp -r /usr/zookeeper-3.4.10 slave1:/usr
# scp -r /usr/zookeeper-3.4.10 slave2:/usr
创建myid文件
-- master节点添加myid文件
# ssh master
# touch /usr/zookeeper-3.4.10/data/myid
# echo 1 > /usr/zookeeper-3.4.10/data/myid
-- slave1节点添加myid文件
# ssh slave1
# touch /usr/zookeeper-3.4.10/data/myid
# echo 2 > /usr/zookeeper-3.4.10/data/myid
-- slave2节点添加myid文件
# ssh slave2
# touch /usr/zookeeper-3.4.10/data/myid
# echo 3 > /usr/zookeeper-3.4.10/data/myid
启动zookeeper(master、slave1、slave2均需执行)
-- 启动master
# ssh master
# cd /usr/zookeeper-3.4.10/bin
# ./zkServer.sh start
-- 启动slave1
# ssh slave1
# cd /usr/zookeeper-3.4.10/bin
# ./zkServer.sh start
-- 启动slave2
# ssh slave2
# cd /usr/zookeeper-3.4.10/bin
# ./zkServer.sh start
到这一步完成了zookeeper环境的搭建
HBase环境搭建
解压缩hbase安装包
# tar -zxvf hbase-1.2.6-bin.star.gz -C /usr
# mkdir /usr/hbase-1.2.6-bin/logs
-- 打开环境变量配置文件
# vim /usr/hbase-1.2.6/conf/hbase-env.sh
-- 添加如下内容
-- 1、设置java安装路径
export JAVA_HOME=/usr/java/jdk1.8.0_131
-- 2、设置hbase的日志地址
export HBASE_LOG_DIR=${HBASE_HOME}/logs
-- 3、设置是否使用hbase管理zookeeper(因使用zookeeper管理的方式,故此参数设置为false)
export HBASE_MANAGES_ZK=false
-- 4、设置hbase的pid文件存放路径
export HBASE_PID_DIR=/var/hadoop/pids
添加所有的region服务器到regionservers文件中
– 打开regionservers配置文件
# vim /usr/hbase-1.2.5/conf/regionservers
-- 删除localhost,新增如下内容
master
slave1
slave2
注:hbase在启动或关闭时会依次迭代访问每一行来启动或关闭所有的region服务器进程
修改Hbase集群的基本配置信息(hbase-site.xml),该配置将会覆盖Hbase的默认配置
-- 打开配置文件
# vim /usr/hbase-1.2.6/conf/hbase-site.xml
-- 在configuration节点下添加如下内容
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/zookeeper-3.4.10/data</value>
</property>
<property>
<name>hbase.master</name>
<value>hdfs://master:60000</value>
</property>
复制hbase到slave中
# scp -r /usr/hbase-1.2.6 slave1:/usr
# scp -r /usr/hbase-1.2.6 slave2:/usr
启动hbase(仅在master节点上执行即可)
# ssh master
# /usr/hbase-1.2.5/bin/start-hbase.sh
到这一步hbase环境搭建完成
本地测试
使用Habse shell连接Hbase
cd /usr/hbase-1.2.6/bin/
./hbase shell
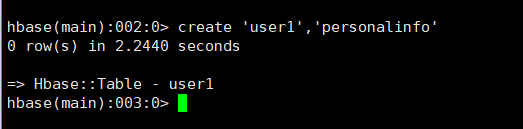
创建user1表
create 'user1','personalinfo'
对user1简单CURD
插入
put 'user1','roow1','personalinfo:name','zhangsan'
查询
get 'user1','row1','personalinfo:name'
其他命令 help查询就好
hbase(main):001:0> help
HBase Shell, version 1.2.6, rUnknown, Mon May 29 02:25:32 CDT 2017
Type 'help "COMMAND"', (e.g. 'help "get"' -- the quotes are necessary) for help on a specific command.
Commands are grouped. Type 'help "COMMAND_GROUP"', (e.g. 'help "general"') for help on a command group.
COMMAND GROUPS:
Group name: general
Commands: status, table_help, version, whoami
Group name: ddl
Commands: alter, alter_async, alter_status, create, describe, disable, disable_all, drop, drop_all, enable, enable_all, exists, get_table, is_disabled, is_enabled, list, locate_region, show_filters
Group name: namespace
Commands: alter_namespace, create_namespace, describe_namespace, drop_namespace, list_namespace, list_namespace_tables
Group name: dml
Commands: append, count, delete, deleteall, get, get_counter, get_splits, incr, put, scan, truncate, truncate_preserve
Group name: tools
Commands: assign, balance_switch, balancer, balancer_enabled, catalogjanitor_enabled, catalogjanitor_run, catalogjanitor_switch, close_region, compact, compact_rs, flush, major_compact, merge_region, move, normalize, normalizer_enabled, normalizer_switch, split, trace, unassign, wal_roll, zk_dump
Group name: replication
Commands: add_peer, append_peer_tableCFs, disable_peer, disable_table_replication, enable_peer, enable_table_replication, list_peers, list_replicated_tables, remove_peer, remove_peer_tableCFs, set_peer_tableCFs, show_peer_tableCFs
Group name: snapshots
Commands: clone_snapshot, delete_all_snapshot, delete_snapshot, list_snapshots, restore_snapshot, snapshot
Group name: configuration
Commands: update_all_config, update_config
Group name: quotas
Commands: list_quotas, set_quota
Group name: security
Commands: grant, list_security_capabilities, revoke, user_permission
Group name: procedures
Commands: abort_procedure, list_procedures
Group name: visibility labels
Commands: add_labels, clear_auths, get_auths, list_labels, set_auths, set_visibility
SHELL USAGE:
Quote all names in HBase Shell such as table and column names. Commas delimit
command parameters. Type <RETURN> after entering a command to run it.
Dictionaries of configuration used in the creation and alteration of tables are
Ruby Hashes. They look like this:
{'key1' => 'value1', 'key2' => 'value2', ...}
and are opened and closed with curley-braces. Key/values are delimited by the
'=>' character combination. Usually keys are predefined constants such as
NAME, VERSIONS, COMPRESSION, etc. Constants do not need to be quoted. Type
'Object.constants' to see a (messy) list of all constants in the environment.
If you are using binary keys or values and need to enter them in the shell, use
double-quote'd hexadecimal representation. For example:
hbase> get 't1', "key\x03\x3f\xcd"
hbase> get 't1', "key\003\023\011"
hbase> put 't1', "test\xef\xff", 'f1:', "\x01\x33\x40"
The HBase shell is the (J)Ruby IRB with the above HBase-specific commands added.
For more on the HBase Shell, see http://hbase.apache.org/book.html