消息中间件应用广泛,Kafka、RabbitMQ 、RocketMQ 和 Pulsar 更是其中的佼佼者,经常被放在一起比较。
从数据迁移同步行业来看,Kafka 用户占了大多数,因为在大数据生态中,其是核心组件之一。RocketMQ 在国内也比较流行,主要应用在在线业务场景,这和它的技术特性和发展路径紧密相关。相比之下,RabbitMQ 和 Pulsar 的使用量在国内相对少些。
那么,它们到底有什么区别呢?本文将从架构设计、性能表现、可扩展性、可靠性 4 个角度进行对比,以呈现一个相对客观的产品状态。
架构设计
Kafka
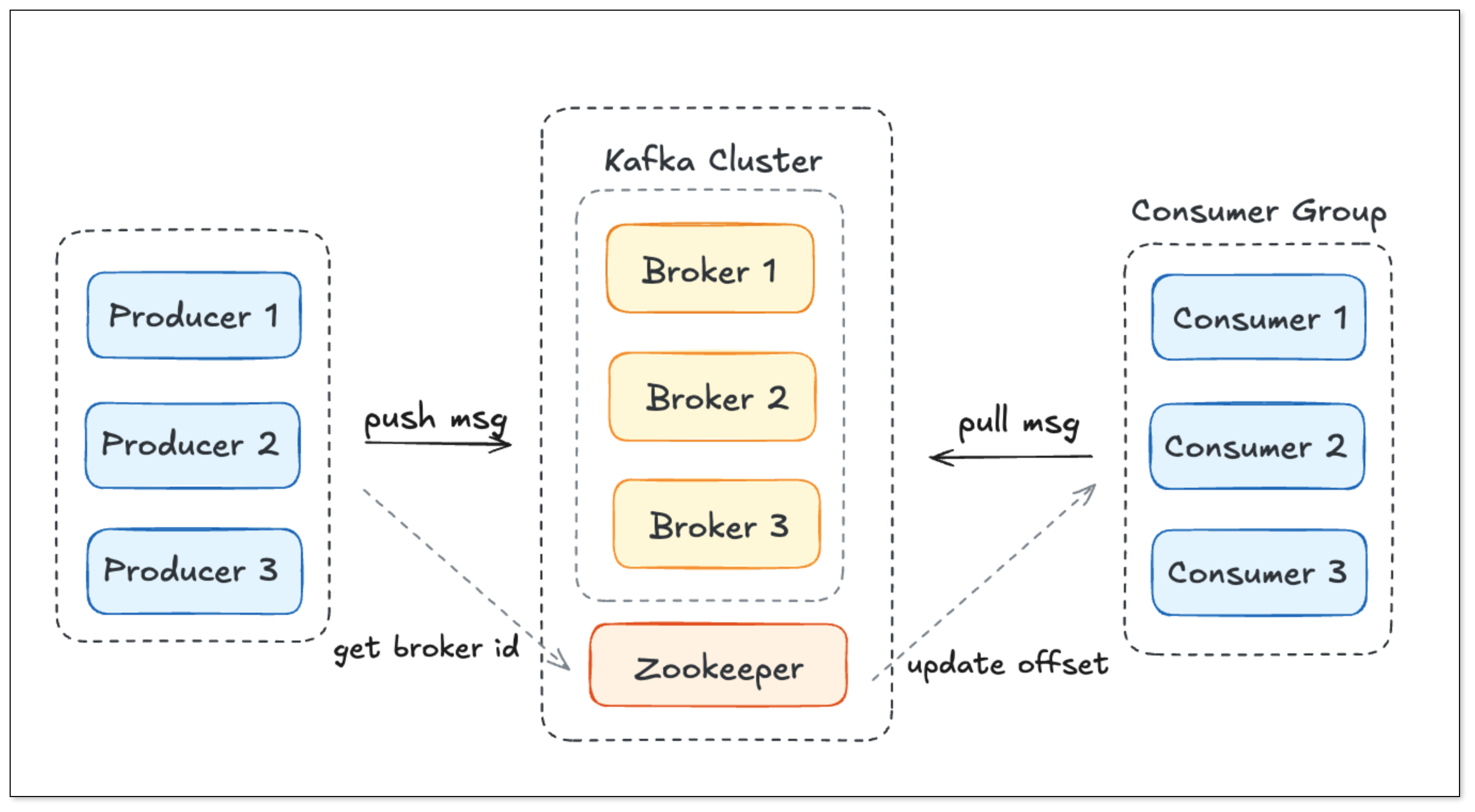
Kafka 采用分布式日志存储架构。Producer 将消息写入 Broker,Broker 将消息存储在分区日志中,Consumer 从分区中顺序拉取数据。ZooKeeper 管理集群元数据。
![]()
RabbitMQ
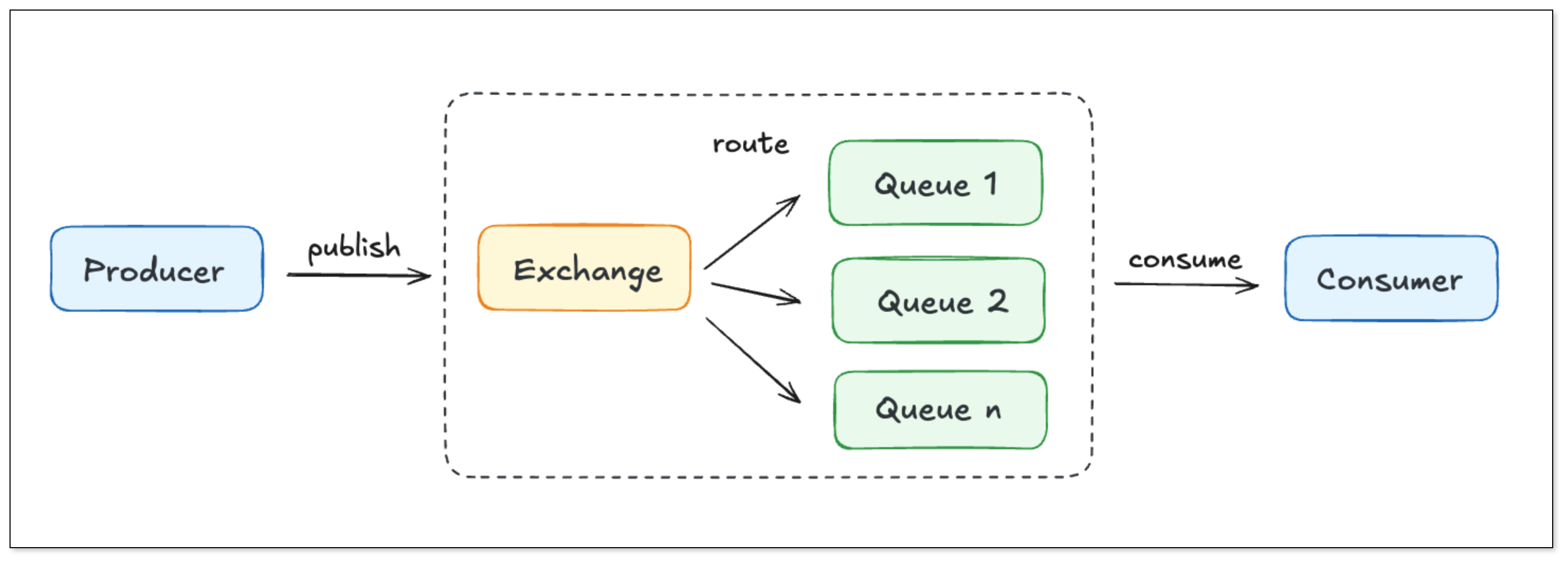
RabbitMQ 基于 AMQP 协议。Producer 将消息发送到 Exchange,再由 Exchange 根据路由规则将消息投递到不同 Queue,最终由 Consumer 消费。其路由模式(direct/topic/fanout/headers)非常灵活,便于应对复杂消息流转。
![]()
RocketMQ
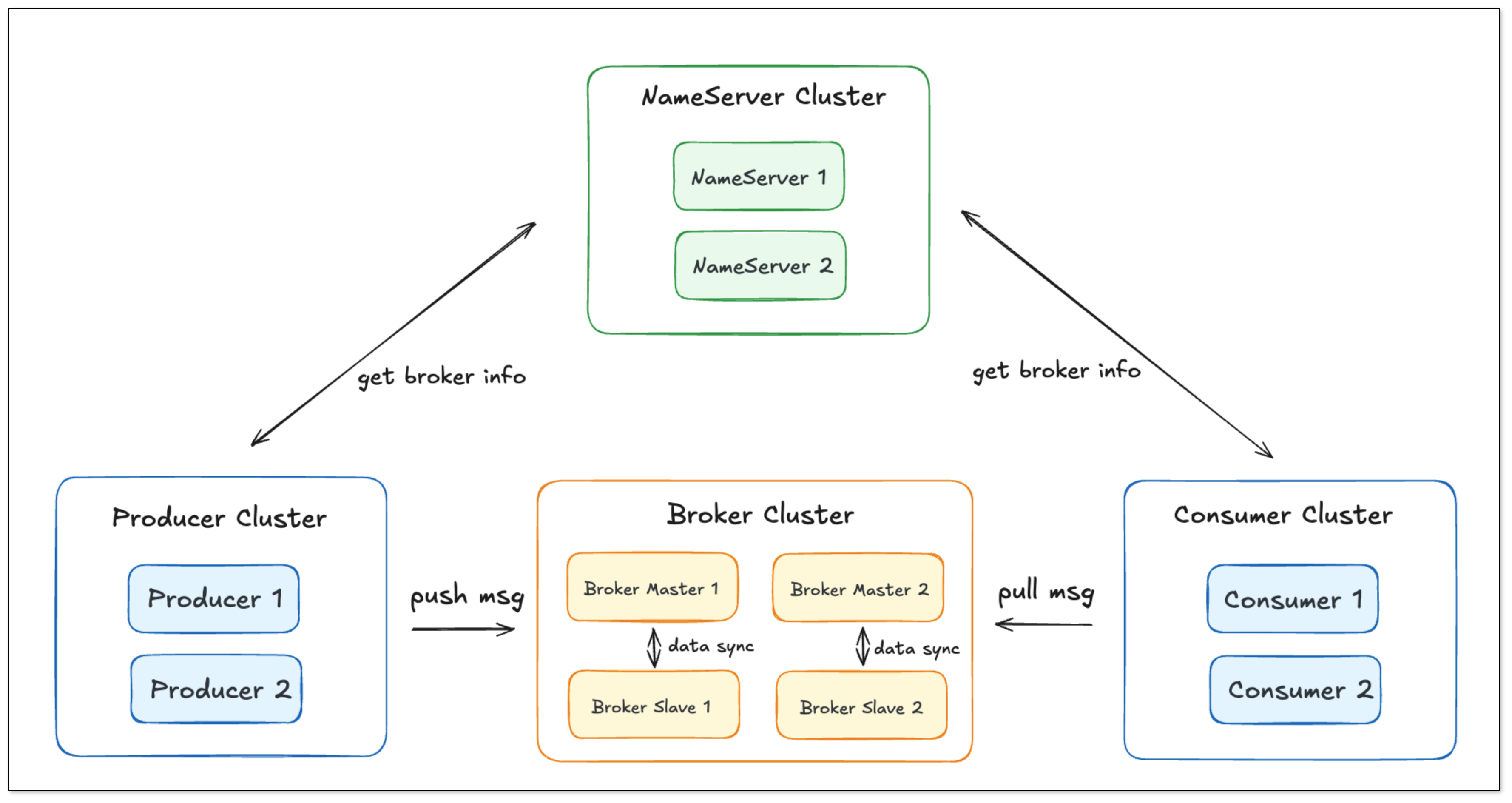
RocketMQ 采用轻量级 NameServer + Broker 架构,Producer 从 NameServer 获取路由信息,再将消息写入 Broker 的队列(MessageQueue)。支持事务消息、顺序消息。 ![]()
Pulsar
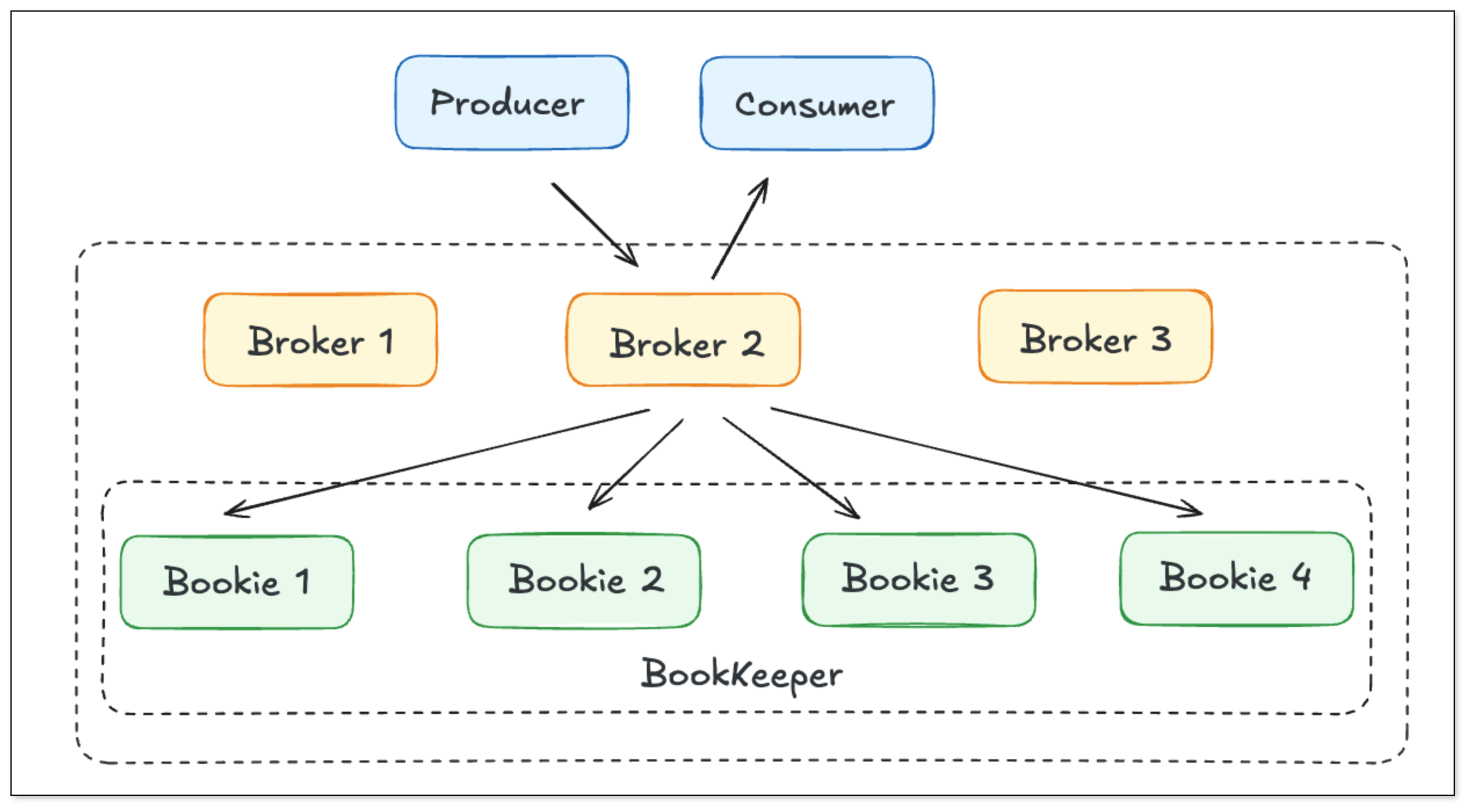
Pulsar 采用 Broker + BookKeeper(存储层)架构,实现计算与存储分离。支持分层存储,天然云原生。
![]()
性能表现
| 指标 |
Kafka |
RabbitMQ |
RocketMQ |
Pulsar |
| 吞吐量 |
单节点可达 数十万–百万 TPS,集群扩展后可达 百万级 TPS+ |
单节点约 万级 TPS,高并发下易受限 |
单节点 数十万 TPS,集群可扩展到百万级(双十一场景) |
单节点 数十万 TPS,大规模集群可达 百万级+ |
| 消息延迟 |
通常 数十毫秒 |
毫秒级,在高吞吐量情况下延迟增大 |
通常* 几十毫秒* |
通常 几十毫秒 |
| 消息堆积能力 |
天然支持海量堆积与历史回放(磁盘持久化,分区日志) |
不适合长时间、大规模堆积,内存压力大 |
支持长时间堆积 |
基于 BookKeeper,多副本存储,支持大规模堆积与分层存储 |
注:数据仅供参考,权威 benchmark 参见产品官方资料
可扩展性
Kafka :基于 分区(Partition) 实现水平扩展,一个 Topic 可以拆分为多个分区并行处理。Broker 集群内的节点数量可扩展至成百上千,支撑大规模实时数据流。
RabbitMQ :通过 多节点集群 模式扩展,但 Queue 需要复制到多个节点,带来较高的同步开销。因此更适合中等规模数据场景。
RocketMQ :通过 增加 Broker 和队列数量 提升性能,存储层支持动态增加 Broker,消费者也能独立扩展,可无停机进行扩容。对于大规模分布式系统,RocketMQ 的扩展方式比较友好。
Pulsar :采用 存算分离 ,可以单独增加 Broker 提升处理能力,增加 BookKeeper 提升存储能力,互不影响,再加上多租户动态资源分配,适合 大规模云原生环境。
可靠性
Kafka :依靠 分区多副本 机制保证数据安全。默认提供 At-least-once 语义,通过幂等写入和事务机制可以实现 Exactly-once。
RabbitMQ :3.8.0 版本中引入了 Quorum Queue,基于 Raft 共识算法,增强可靠性。提供 At-least-once 语义,保证不丢消息,但可能存在重复,需要业务端做幂等处理。
RocketMQ :通过 主从复制 和 刷盘机制 保证可靠性。新版本的 DLedger 基于 Raft 协议,支持自动主从切换,容错能力更强。
Pulsar:基于 BookKeeper 的多副本存储,即使 Broker 故障也能保障数据安全。天然支持多租户和隔离,可靠性和容错能力突出,尤其适合云原生环境。
总结
| 特性 |
Kafka |
RabbitMQ |
RocketMQ |
Pulsar |
| 实现语言 |
Java/Scala |
Erlang |
Java |
Java |
| 消费模式 |
Pull |
Push |
Pull |
Pull + Push |
| 吞吐量 |
极高 |
一般 |
较高 |
较高 |
| 延迟 |
低 |
极低,在高吞吐量情况下会受限 |
低 |
低 |
| 消息堆积能力 |
极强(长期存储可回放) |
较弱 |
强 |
强(分层存储,云原生) |
| 扩展性 |
极强,分区扩展 |
一般,受限于集群和硬件资源 |
较强 |
极强,计算存储分离 |
| 可靠性 |
极高,多副本 |
高,Quorum Queue 提升可靠性 |
较高,DLedger 提高主从切换容错 |
极高,存储分离 + 多副本 |
| 协议支持 |
Kafka 协议 |
AMQP、MQTT、STOMP 等 |
RocketMQ 原生及多协议扩展 |
Pulsar 原生协议及多协议扩展 |
| 社区与生态 |
活跃,生态最强 |
稳定,插件丰富 |
国内用户多,云支持好 |
新兴但发展快,云原生场景活跃 |
| 适用场景 |
日志采集、实时数仓、数据总线 |
即时通信、任务调度、请求-应答 |
电商订单、金融交易、支付系统 |
SaaS 平台、跨数据中心消息流转 |
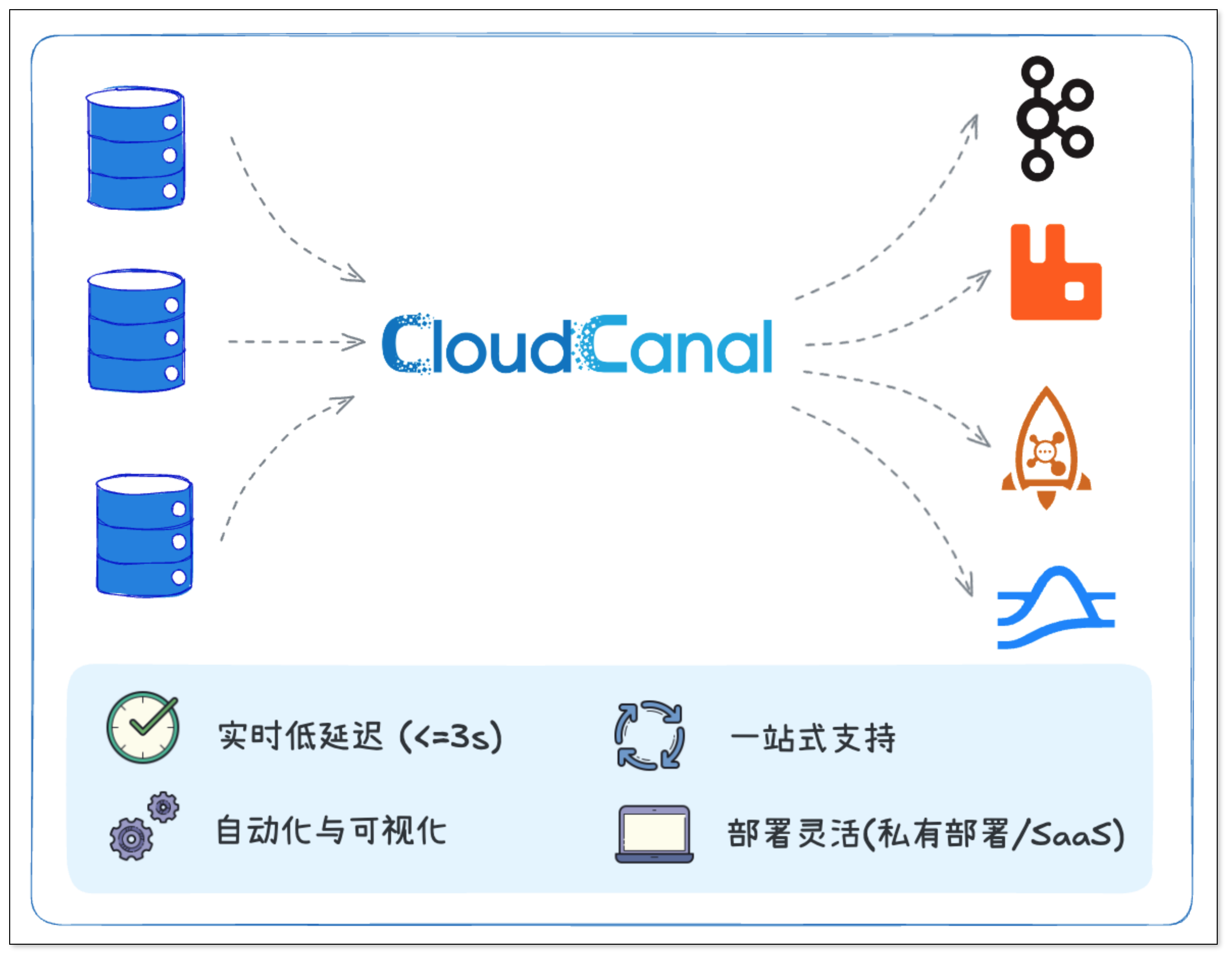
CloudCanal 如何支持数据流动?
上面我们对比了 Kafka、RabbitMQ、RocketMQ 和 Pulsar,可以看到它们在不同场景中各有优势。
无论选择哪一款消息中间件,都绕不开一个关键问题:如何把数据稳定、高效地同步到这些消息系统中?
这正是 CloudCanal 擅长的领域。CloudCanal 作为一款实时数据迁移与同步工具,具备以下特点:
- 实时低延迟:基于 CDC 技术捕获数据库变更,秒级同步到各类主流消息中间件,保证数据的实时流动。
- 一站式支持:同时支持 Kafka、RabbitMQ、RocketMQ、Pulsar 等主流消息系统,企业无需额外开发同步工具。
- 自动化与可视化:提供友好的 UI 界面,支持任务配置、监控与运维全流程可视化,降低运维负担。
- 部署灵活:支持本地私有部署和 SaaS 部署两种模式,适配不同规模的业务需求。
![]()
感兴趣的话,可点击查看如何在 5 分钟内快速实现 MySQL 到 Kafka 的数据迁移同步。
实操演示:五分钟快速实现 MySQL 到 Kafka 数据迁移同步
借助 CloudCanal,企业可以在不同消息系统之间自由选择和切换,而不必担心底层数据同步的复杂性。无论是构建实时数仓,还是支撑跨云多活的业务系统,CloudCanal 都能帮助开发者和 DBA 更快、更稳地落地。