摘要:为提升网络性能、降低人工调优成本,CANN推出了自动化网络调优工具AOE,通过子图调优、算子调优与梯度调优的功能,让网络可以在AI硬件上获得最佳性能。
本文分享自华为云社区《网络性能总不好?专家帮你来“看看”— CANN 6.0 黑科技 | 网络调优专家AOE,性能效率双提升》,作者:昇腾CANN 。
随着深度学习模型复杂度和数据集规模的增大,计算效率的提升成为不可忽视的问题。然而,算法网络的多样性、输入数据的不确定性以及硬件之间的差异性,使得网络调优耗费巨大成本,即使是经验丰富的专家,也需要耗费数天的时间。
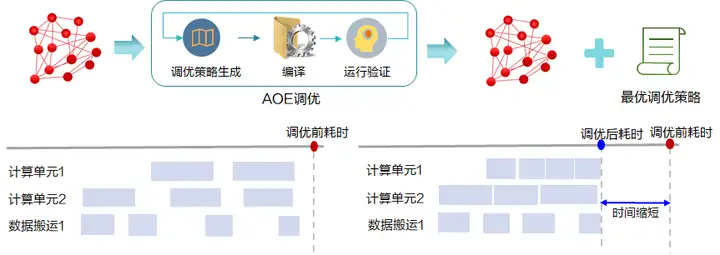
CANN(Compute Architecture for Neural Networks)是华为针对AI场景推出的异构计算架构,对上支持多种AI框架,对下服务AI处理器与编程,发挥承上启下的关键作用,是昇腾AI基础软硬件平台的核心。为了在提升网络性能的同时降低巨大的人工调优成本,CANN推出了自动化网络调优工具AOE(Ascend Optimization Engine),通过构建包含自动调优策略生成、编译、运行环境验证的闭环反馈机制,不断迭代,最终得到最优调优策略,从而在AI硬件上获得最佳网络性能。以ResNet50推理网络为例,经AOE调优后的网络性能提升100%以上,调优耗时不到30分钟。
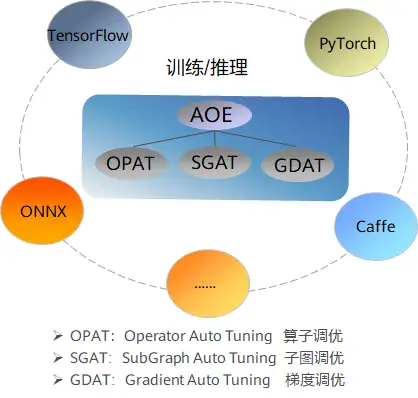
针对网络模型,AOE分别提供了算子调优、子图调优与梯度调优的功能。其中算子调优,主要针对算子的调度(Schedule)进行优化,从而使得昇腾AI处理器的多级Buffer与计算单元形成高效的流水并发作业流,充分释放硬件算力;子图调优,通过智能化的数据切分策略提升缓存利用率,从而大幅提升计算效率;梯度调优主要应用于集群训练场景下,通过自动化寻找最优梯度切分策略、降低通信拖尾时间,从而提升集群训练性能。同时,AOE能够支持多种主流开源框架,在训练和推理场景下全方位满足不同开发者的网络性能调优诉求。
算子调优,提升计算节点执行效率
1. 强化学习,生成Vector算子最优调度策略
AI处理器在计算过程中需要精心排布才能充分发挥算力,计算组件间的流水排布很大一部分由调度来承载,一个很小的调度操作映射到硬件行为上都可能产生巨大的差异。想要提升网络性能,势必需要为给定网络在指定设备上开发一套专属的调度逻辑。
网络的组成单元是算子,为算子执行寻找最优的调度策略是提升网络性能的关键。昇腾AI处理器的核心计算单元是AI Core,针对运行在AI Core上的算子,可以分为Vector与Cube两类,其中Vector算子主要负责执行向量运算,Cube算子主要负责执行矩阵运算。
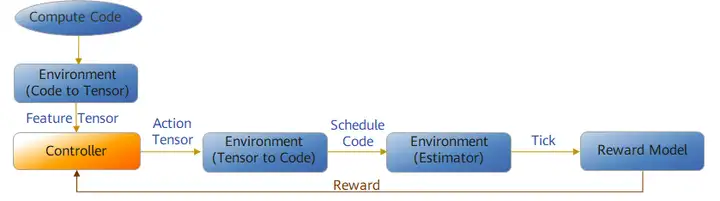
针对Vector算子,CANN采用了RL强化学习(Reinforcement Learning)搜索框架,将算子调度过程抽象成了基于MCTS蒙特卡洛树搜索(Monte Carlo Tree Search)的决策链,并模拟人工进行决策,再通过和环境不断交互得到性能数据,作为反馈值指导下一步决策。通过此方法一步步改善自身行为,最终获取算子执行对应的完整最优调度策略。
经过AOE调优后的Vector算子,平均性能较调优前可提升10%以上,平均调优时间仅需200s,效率与性能都有较大提升。
2. 遗传算法,提高Cube算子搜索效率
我们知道在深度学习网络中包含了大量的矩阵乘计算,而这部分计算在昇腾AI处理器中均通过Cube算力来承担,因此Cube算子作为重型算子,在网络中的影响权重较大,所以针对Cube算子的性能提升会给整个网络的性能带来较大的收益。
通过强化学习模式的搜索,我们已经可以做到解放人力进行Vector类型的算子优化,因为Vector算子的计算Buffer单一,调度算法可以基于各种Schedule原语为算子构建完整的调度策略。而Cube算子涉及多块片上Buffer之间的数据交互,如果按照和Vector算子相同的调优方式,可能最终会因为搜索空间过大导致搜索效率低下和搜索策略不佳的结果。
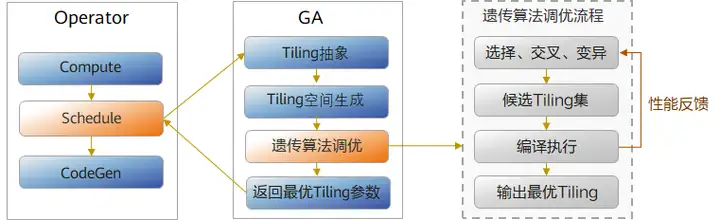
针对Cube算子,AOE以Schedule模板为基础,利用GA遗传算法(Genetic Algorithm),通过选择、交叉、变异等方式对影响最大的Schedule原语参数进行多轮调优,从而得到候选Tiling集,再根据在真实环境编译执行的性能反馈数据将候选策略进行排序,得到最优策略。
以卷积算子为例,若人工调优,需要消耗一个算子优化专家两天的时间;若使用AOE智能调优,平均仅需3分钟即可达到相同甚至更优的性能优化效果,极大地节省了人力成本!
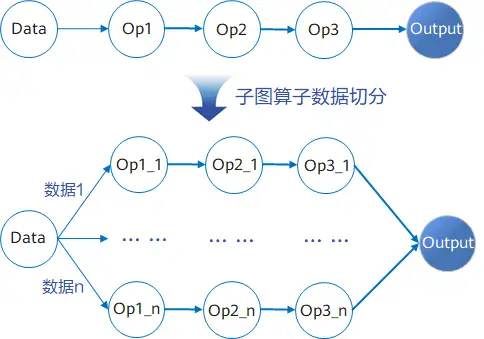
子图调优,获得更智能的数据切分
算子调优已经使得网络性能有了可观的提升,但AOE并没有止步于此。AOE在更宏观的粒度上加入了子图调优,从而实现更智能的数据切分。
深度学习模型的计算往往有较大的数据吞吐,数据读写往往成为网络性能的瓶颈,因此对于高速缓存利用率的提升成为计算效率优化的关键手段。
昇腾AI处理器中包含了高速缓存以降低外部访存的带宽压力,然而由于特征图(Feature Map)和模型参数的数据量巨大,会导致算子计算过程中的Cache命中率较低,影响整网计算效率。为了更好地提升高速缓存Cache命中率,AOE引入了子图调优的概念。
子图调优,基于算子切分数学等价原则,根据硬件Cache大小、算子shape等信息,将网络模型中的算子切分成多个算子,然后编排切分后算子的执行顺序,通过获取最佳的性能反馈,确定计算图切分策略和执行顺序。这样,就可以将一次性的数据流计算分解成多次进行执行,在分解后的数据流分支上,数据大小相比之前成倍递减,进而实现了Cache命中率的显著提升。
最终,在算子调优和子图调优的共同作用下,使用AOE进行性能调优后,主流推理网络的平均性能提升30%以上。以ResNet50推理网络为例,性能较调优前提升超过100%,整网调优耗时30分钟以内。
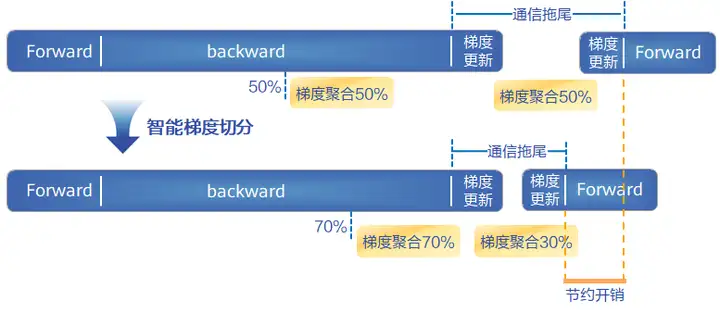
梯度调优,提升集群训练性能
大规模集群训练场景中,存在着计算节点多、梯度聚合过程复杂、通信开销大的痛点。梯度聚合过程和计算过程怎么更好的一定程度上相互掩盖,让整个过程保证较好的线性度,也是性能提升的关键问题。为此,AOE引入了梯度调优的功能,通过智能梯度切分算法,自动搜索出最优梯度参数切分方式,为梯度传输选择合适的通信时机和通信量,最大限度让计算和通信并行,从而将通信拖尾时间降至最低,促使集群训练达到最优性能。
相对人工调整梯度聚合数据量,自动梯度调优可以将梯度聚合数据量调参时间从数人天缩短至数十分钟,一举获得最优聚合策略,降低人工调参的不确定性。AOE通过调优知识库记录模型调优经验,使得模型聚合策略能够动态适应不同集群规模。
经过AOE调优后,主流训练网络在昇腾AI处理器上执行性能较调优前平均提升了20%以上。以ResNet50训练网络为例,性能较调优前提升了23%,整网调优耗时2H以内。
写在最后
昇腾异构计算架构CANN始终致力于提供“开放易用、极致性能”的AI开发体验,不断降低AI开发的门槛与成本。CANN提供的昇腾调优引擎AOE克服了传统调优方法耗时长、泛化性差、维护成本高等影响开发效率和可用性的弊端,为AI开发者提供了更智能化的性能优化手段。
以梦为马,未来可期,相信通过CANN的持续创新与不断演进,定将进一步释放AI硬件的澎湃算力,加速AI应用场景落地,共建智慧世界。
点击关注,第一时间了解华为云新鲜技术~