
KTV歌曲推荐-PCA降维+逻辑回归-性别预测及过拟合处理
前言
上一篇使用逻辑回归预测了用户性别,由于矩阵比较稀疏所以会影响训练速度。所以考虑降维,降维方案有很多,本次只考虑PCA和SVD。
PCA和SVD原理
我简述一下:
- PCA是将高维数据映射到低维坐标系中,让数据尽量稀疏
- SVD就是非方阵的PCA
- 实际使用中SVD和PCA并无太大区别
- 如果特征大于数据记录数,并不能有好的效果,具体原因自己可以去看。
代码
数据获取和处理
以前文章写过很多次,这里略过 原数据shape为:2000*1900
PCA和矩阵转换
查看最佳维度数
%matplotlib inline import numpy as np import matplotlib.pyplot as plt from sklearn.decomposition import PCA pca = PCA().fit(song_hot_matrix) plt.plot(np.cumsum(pca.explained_variance_ratio_)) plt.xlabel('number of components') plt.ylabel('cumulative explained variance'); 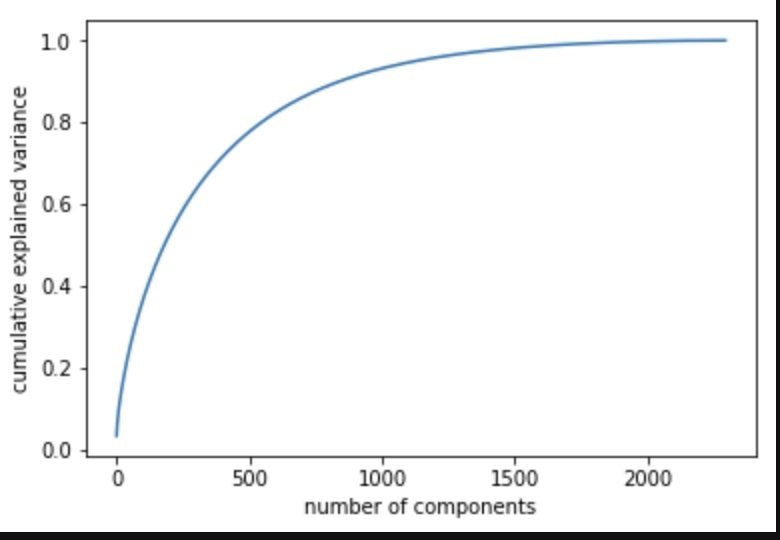
从图中可以看出大概1500维度已经可以达到90+解释性
保留99%矩阵解释性
pca = PCA(n_components=0.99, whiten=True) song_hot_matrix_pca = pca.fit_transform(song_hot_matrix) 得到压缩后特征为: 2000*1565 并没有压缩多少
模型训练
import os os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID" # see issue #152 os.environ["CUDA_VISIBLE_DEVICES"] = "" import numpy as np from keras.models import Sequential from keras.layers import Dense, Activation, Embedding,Flatten,Dropout import matplotlib.pyplot as plt from keras.utils import np_utils from sklearn import datasets from sklearn.model_selection import train_test_split n_class=user_decades_encoder.get_class_count() song_count=song_label_encoder.get_class_count() print(n_class) print(song_count) train_X,test_X, train_y, test_y = train_test_split(song_hot_matrix_pca, decades_hot_matrix, test_size = 0.2, random_state = 0) train_count = np.shape(train_X)[0] # 构建神经网络模型 model = Sequential() model.add(Dense(input_dim=song_hot_matrix_pca.shape[1], units=n_class)) model.add(Activation('softmax')) # 选定loss函数和优化器 model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy']) # 训练过程 print('Training -----------') for step in range(train_count): scores = model.train_on_batch(train_X, train_y) if step % 50 == 0: print("训练样本 %d 个, 损失: %f, 准确率: %f" % (step, scores[0], scores[1]*100)) print('finish!') 训练结果:
训练样本 4750 个, 损失: 0.371499, 准确率: 83.207470 训练样本 4800 个, 损失: 0.381518, 准确率: 82.193959 训练样本 4850 个, 损失: 0.364363, 准确率: 83.763909 训练样本 4900 个, 损失: 0.378466, 准确率: 82.551670 训练样本 4950 个, 损失: 0.391976, 准确率: 81.756759 训练样本 5000 个, 损失: 0.378810, 准确率: 83.505565 测试集验证:
# 准确率评估 from sklearn.metrics import classification_report scores = model.evaluate(test_X, test_y, verbose=0) print("%s: %.2f%%" % (model.metrics_names[1], scores[1]*100)) Y_test = np.argmax(test_y, axis=1) y_pred = model.predict_classes(song_hot_matrix_pca.transform(test_X)) print(classification_report(Y_test, y_pred)) accuracy: 50.20%
很明显已经过拟合
处理过拟合
这里使用加Dropout,随机丢弃特征的方式处理过拟合,代码:
# 构建神经网络模型 model = Sequential() model.add(Dropout(0.5)) model.add(Dense(input_dim=song_hot_matrix_pca.shape[1], units=n_class)) model.add(Activation('softmax')) 准确率70%
well done
其实SVD的做法与PCA类似,这里不再演示。经过我测试发现,在我的数据集上,PCA虽然加快了训练速度,但是丢弃了太多特征,导致数据很容易过拟合。加入dropout可以改善过拟合的情况,下一篇会分享自编码降维。
 关注公众号
关注公众号 低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。
持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
转载内容版权归作者及来源网站所有,本站原创内容转载请注明来源。
- 上一篇

代码质量管理工具:SonarQube常见的问题及正确解决方案
SonarQube 简介 Sonar 是一个用于代码质量管理的开放平台。通过插件机制,Sonar 可以集成不同的测试工具,代码分析工具,以及持续集成工具。 与持续集成工具(例如 Hudson/Jenkins 等)不同,Sonar 并不是简单地把不同的代码检查工具结果(例如 FindBugs,PMD 等)直接显示在 Web 页面上,而是通过不同的插件对这些结果进行再加工处理,通过量化的方式度量代码质量的变化,从而可以方便地对不同规模和种类的工程进行代码质量管理。 在对其他工具的支持方面,Sonar 不仅提供了对 IDE 的支持,可以在 Eclipse 和 IntelliJ IDEA 这些工具里联机查看结果;同时 Sonar 还对大量的持续集成工具提供了接口支持,可以很方便地在持续集成中使用 Sonar。 此外,Sonar 的插件还可以对 Java 以外的其他编程语言提供支持,对国际化以及报告文档化也有良好的支持 Math operands should be cast before assignment-数字操作在操作或赋值前要分配 对整数执行算术运算时,结果将始终是整数。您可以通...
- 下一篇
首推全云端开发体验,腾讯云构建 Serverless 应用新标准
在第三代通用计算平台的探索和布局上,腾讯云已经走在了全球的前列。3 月 6 日,腾讯云正式向外界展示了其在 Serverless 领域的最新进展,包括率先在业界推出 1 毫秒计费模式,并通过进一步打通上下生态链,构建三步上云的极致全云端开发体验。 作为一种新型的开发架构,Serverless 具备低人工、基础设施成本、低故障风险、高扩展性以及交付周期短等优势,但是在真正落地方面还面临成本费用过高、开发支持欠缺以及开源标准不统一等难题。腾讯云基于自身在计费模式、开发体验以及上下游生态等方面的超前探索,正在引领 Serverless 的行业“新标准”。 全球首推 1 毫秒计费,行业标准提升百倍 相比云主机的按秒付费,虽然目前行业内已经将 Serverless 架构的计费粒度普遍降低到 100 毫秒,但在实际应用中依然有大量实际运行时长少于 100 毫秒的业务场景依然按照 100 毫秒计费。 以实际运行时长 30 毫秒的场景来说,如果按照 100 毫秒计费的话,相当于用户多花费了 70% 的资源费用。这实际上给开发者造成了不必要的成本压力。为了进一步降低用户的资源成本,避免资源浪费,腾讯云在...
相关文章
文章评论
共有0条评论来说两句吧...
文章二维码
点击排行

推荐阅读






最新文章
- SpringBoot2编写第一个Controller,响应你的http请求并返回结果
- CentOS8,CentOS7,CentOS6编译安装Redis5.0.7
- MySQL8.0.19开启GTID主从同步CentOS8
- CentOS7,CentOS8安装Elasticsearch6.8.6
- Docker使用Oracle官方镜像安装(12C,18C,19C)
- Jdk安装(Linux,MacOS,Windows),包含三大操作系统的最全安装
- Linux系统CentOS6、CentOS7手动修改IP地址
- CentOS7安装Docker,走上虚拟化容器引擎之路
- CentOS7编译安装Cmake3.16.3,解决mysql等软件编译问题
- SpringBoot2全家桶,快速入门学习开发网站教程
 微信收款码
微信收款码 支付宝收款码
支付宝收款码